GC过程
对于HotSpot虚拟机垃圾回收过程,这里将分析介绍默认配置下MarkSweepPolicy的DefNewGeneration和TenuredGeneration的垃圾回收内容以及介绍其他GC策略和代实现的GC思想。GC的过程姑且简单地分为内存代实现无关的GC过程和内存代GC过程。 本文将先进行内存代实现无关的GC过程分析,内存代GC过程将在后面进行分析。
从GenCollectedHeap的do_collection()说起: 1.在GC之前有许多必要的检查和统计任务,比如对回收内存代的统计、堆内存大小的统计等,注意本节内容将不再去分析一些性能统计的内容,有兴趣的可自行分析。 (1).检查是否已经GC锁是否已经激活,并设置需要进行GC的标志为true,这时,通过is_active_and_needs_gc()就可以判断是否已经有线程触发了GC。
if (GC_locker::check_active_before_gc()) {
return; // GC is disabled (e.g. JNI GetXXXCritical operation)
}
(2).检查是否需要回收所有的软引用。
const bool do_clear_all_soft_refs = clear_all_soft_refs ||
collector_policy()->should_clear_all_soft_refs();
(3).记录永久代已经使用的内存空间大小。
const size_t perm_prev_used = perm_gen()->used();
(4).确定回收类型是否是FullGC以及gc触发类型(GC/Full GC(system)/Full GC,用作Log输出)。
bool complete = full && (max_level == (n_gens()-1));
const char* gc_cause_str = "GC ";
if (complete) {
GCCause::Cause cause = gc_cause();
if (cause == GCCause::_java_lang_system_gc) {
gc_cause_str = "Full GC (System) ";
} else {
gc_cause_str = "Full GC ";
}
}
(5).gc计数加1操作(包括总GC计数和FullGC计数)。
increment_total_collections(complete);
(6).统计堆已被使用的空间大小。
size_t gch_prev_used = used();
(7).如果是FullGC,那么从最高的内存代到最低的内存代,若某个内存代不希望对比其更低的内存代进行单独回收,那么就以该内存代作为GC的起始内存代。这里说明下什么是单独回收。新生代比如DefNewGeneration的实现将对新生代使用复制算法进行垃圾回收,而老年代TenuredGeneration的垃圾回收则会使用其标记-压缩-清理算法对新生代也进行处理。所以可以说DefNewGeneration的垃圾回收是对新生代进行单独回收,而TenuredGeneration的垃圾回收则是对老年代和更低的内存代都进行回收。
int starting_level = 0;
if (full) {
// Search for the oldest generation which will collect all younger
// generations, and start collection loop there.
for (int i = max_level; i >= 0; i--) {
if (_gens[i]->full_collects_younger_generations()) {
starting_level = i;
break;
}
}
}
2.接下来从GC的起始内存代开始,向最老的内存代进行回收 。 (1).其中should_collect()将根据该内存代GC条件返回是否应该对该内存代进行GC。若当前回收的内存代是最老的内存代,如果本次gc不是FullGC,将调用increment_total_full_collections()修正之前的FulllGC计数值。
int max_level_collected = starting_level;
for (int i = starting_level; i <= max_level; i++) {
if (_gens[i]->should_collect(full, size, is_tlab)) {
if (i == n_gens() - 1) { // a major collection is to happen
if (!complete) {
// The full_collections increment was missed above.
increment_total_full_collections();
}
(2).统计GC前该内存代使用空间大小以及其他记录工作 。 (3).验证工作 。
先调用prepare_for_verify()使各内存代进行验证的准备工作(正常情况下什么都不需要做),随后调用Universe的verify()进行GC前验证
if (VerifyBeforeGC && i >= VerifyGCLevel &&
total_collections() >= VerifyGCStartAt) {
HandleMark hm; // Discard invalid handles created during verification
if (!prepared_for_verification) {
prepare_for_verify();
prepared_for_verification = true;
}
gclog_or_tty->print(" VerifyBeforeGC:");
Universe::verify(true);
}
线程、堆(各内存代)、符号表、字符串表、代码缓冲、系统字典等,如对堆的验证将对堆内的每个oop对象的类型Klass进行验证,验证对象是否是oop,类型klass是否在永久代,oop的klass域是否是klass 。那么为什么在这里进行GC验证?GC前验证和GC后验证又分别有什么作用? VerifyBeforeGC和VerifyAfterGC都需要和UnlockDiagnosticVMOptions配合使用以用来诊断JVM问题,但是验证过程非常耗时,所以在正常的编译版本中并没有将验证内容进行输出。 (4).保存内存代各区域的碰撞指针到该区域的_save_mark_word变量。
save_marks();
(5).初始化引用处理器。
ReferenceProcessor* rp = _gens[i]->ref_processor();
if (rp->discovery_is_atomic()) {
rp->verify_no_references_recorded();
rp->enable_discovery();
rp->setup_policy(do_clear_all_soft_refs);
} else {
// collect() below will enable discovery as appropriate
}
(6).由各内存代完成gc
_gens[i]->collect(full, do_clear_all_soft_refs, size, is_tlab);
(7).将不可触及的引用对象加入到Reference的pending链表
if (!rp->enqueuing_is_done()) {
rp->enqueue_discovered_references();
} else {
rp->set_enqueuing_is_done(false);
}
rp->verify_no_references_recorded();
}
其中enqueue_discovered_references根据是否使用压缩指针选择不同的enqueue_discovered_ref_helper()模板函数 ,enqueue_discovered_ref_helper()实现如下:
template <class T>
bool enqueue_discovered_ref_helper(ReferenceProcessor* ref,
AbstractRefProcTaskExecutor* task_executor) {
T* pending_list_addr = (T*)java_lang_ref_Reference::pending_list_addr();
T old_pending_list_value = *pending_list_addr;
ref->enqueue_discovered_reflists((HeapWord*)pending_list_addr, task_executor);
oop_store(pending_list_addr, oopDesc::load_decode_heap_oop(pending_list_addr));
ref->disable_discovery();
return old_pending_list_value != *pending_list_addr;
}
pending_list_addr是Reference的私有静态(类)成员pending链表的首元素的地址,gc阶段当引用对象的可达状态变化时,会将引用加入到pending链表中,而Reference的私有静态(类)成员ReferenceHandler将不断地从pending链表中取出引用加入ReferenceQueue。 enqueue_discovered_reflists()根据是否使用多线程有着不同的处理方式,若采用多线程则会创建一个RefProcEnqueueTask交由AbstractRefProcTaskExecutor进行处理,这里我们分析单线程的串行处理情况: 这里,DiscoveredList数组_discoveredSoftRefs保存了最多_max_num_q*subclasses_of_ref个软引用的链表。在将引用链表处理后会将引用链表的起始引用置为哨兵引用,并设置引用链长度为0,表示该列表为空。
void ReferenceProcessor::enqueue_discovered_reflists(HeapWord* pending_list_addr,
AbstractRefProcTaskExecutor* task_executor) {
if (_processing_is_mt && task_executor != NULL) {
// Parallel code
RefProcEnqueueTask tsk(*this, _discoveredSoftRefs,
pending_list_addr, sentinel_ref(), _max_num_q);
task_executor->execute(tsk);
} else {
// Serial code: call the parent class's implementation
for (int i = 0; i < _max_num_q * subclasses_of_ref; i++) {
enqueue_discovered_reflist(_discoveredSoftRefs[i], pending_list_addr);
_discoveredSoftRefs[i].set_head(sentinel_ref());
_discoveredSoftRefs[i].set_length(0);
}
}
}
enqueue_discovered_reflist()如下:
取出refs_list链上的首元素,next为discovered域所成链表上的下一个元素
oop obj = refs_list.head();
while (obj != sentinel_ref()) {
assert(obj->is_instanceRef(), "should be reference object");
oop next = java_lang_ref_Reference::discovered(obj);
如果next是最后的哨兵引用,那么,原子交换discovered域所成链表上的表尾元素与pending_list_addr的值,即将其加入到pending链表的表头,接下来根据插入到表头的链表的处理方式,当pending链表为空时,作为表尾元素其next域指向自身,否则,将其next域指向链表的原表头元素,这样就将该元素插入到pending链表的原表头位置,即:
if (next == sentinel_ref()) { // obj is last
// Swap refs_list into pendling_list_addr and
// set obj's next to what we read from pending_list_addr.
oop old = oopDesc::atomic_exchange_oop(refs_list.head(), pending_list_addr);
// Need oop_check on pending_list_addr above;
// see special oop-check code at the end of
// enqueue_discovered_reflists() further below.
if (old == NULL) {
// obj should be made to point to itself, since
// pending list was empty.
java_lang_ref_Reference::set_next(obj, obj);
} else {
java_lang_ref_Reference::set_next(obj, old);
}
否则若next不是最后的哨兵引用,设置引用对象的next域为next,即将从引用链表的表头元素开始,将虚拟机所使用的discovered域所成链表转化为Java层可使用的next域所成pending列表。
} else {
java_lang_ref_Reference::set_next(obj, next);
}
最后设置引用对象的discovered域为NULL,即切断当前引用在discovered域所成链表中的引用关系,并继续遍历引用链
java_lang_ref_Reference::set_discovered(obj, (oop) NULL);
obj = next;
}
综上所述,入队的操作就是通过原来的discovered域进行遍历,将引用链表用next域重新连接后切断discovered域的关系并将新链表附在pending链表的表头。
(9).回到GC完成后的处理:更新统计信息和进行GC后验证
3.输出一些GC的日志信息
complete = complete || (max_level_collected == n_gens() - 1);
if (complete) { // We did a "major" collection
post_full_gc_dump(); // do any post full gc dumps
}
if (PrintGCDetails) {
print_heap_change(gch_prev_used);
// Print perm gen info for full GC with PrintGCDetails flag.
if (complete) {
print_perm_heap_change(perm_prev_used);
}
}
4.更新各内存代的大小
for (int j = max_level_collected; j >= 0; j -= 1) {
// Adjust generation sizes.
_gens[j]->compute_new_size();
}
5.FullGC后更新和调整永久代内存大小
if (complete) {
// Ask the permanent generation to adjust size for full collections
perm()->compute_new_size();
update_full_collections_completed();
}
6.若配置了ExitAfterGCNum,则当gc次数达到用户配置的最大GC计数时退出VM
if (ExitAfterGCNum > 0 && total_collections() == ExitAfterGCNum) {
tty->print_cr("Stopping after GC #%d", ExitAfterGCNum);
vm_exit(-1);
}
DefNewGeneration的GC过程
由于虚拟机的分代实现,虚拟机不会考虑各个内存代如何实现垃圾回收,具体的工作(对象内存的分配也是一样)由各内存代根据垃圾回收策略自行实现。
DefNewGeneration的使用复制算法进行回收。复制算法的思想是将eden和from区活跃的对象复制到to区,并清空eden区和from区,如果to区满了,那么部分对象将会被晋升移动到老年代,随后交换from和to区,即原来的to区存放了存活的对象作为新的from区存在,而from区被清空后当做新的to区而存在,移动次数超过一定阈值的对象也会被移动到老年代。
此外,在分析DefNewGeneration的垃圾回收之前,可以了解一下,在垃圾回收过程中,对对象的遍历处理定义一个抽象基类OopClosure(对象表),并使用其不同的实现类来完成对对象的不同处理。 其中使用FastScanClosure来处理所有的根对象,FastEvacuateFollowersClosure处理所有的递归引用对象等。
在前文分析中,会调用各个内存代的collect()来完成垃圾回收。话不多说,直接上代码:
一、DefNewGeneration的GC基本过程:
DefNewGeneration::collect()定义在/hotspot/src/share/vm/memory/defNewGeneration.cpp中 。 1.当Survivor区空间不足,从Eden区移动过来的对象将会晋升到老年代,然而当老年代空间不足时,那么垃圾回收就是不安全的,将直接返回。

if (!collection_attempt_is_safe()) {
if (Verbose && PrintGCDetails) {
gclog_or_tty->print(" :: Collection attempt not safe :: ");
}
gch->set_incremental_collection_failed(); // Slight lie: we did not even attempt one
return;
}
collection_attempt_is_safe()判断垃圾回收是否安全有以下判定条件:
bool DefNewGeneration::collection_attempt_is_safe() {
if (!to()->is_empty()) {
return false;
}
if (_next_gen == NULL) {
GenCollectedHeap* gch = GenCollectedHeap::heap();
_next_gen = gch->next_gen(this);
assert(_next_gen != NULL,
"This must be the youngest gen, and not the only gen");
}
return _next_gen->promotion_attempt_is_safe(used());
}
(1).To区非空,则可能有不够充足的转移空间 (2).调用下一个内存代的promotion_attempt_is_safe()进行判断,是否有充足的空间容纳新生代的所有对象
2.一些准备工作
(1).统计堆的使用空间大小(仅留作输出,可以不管)
(2).准备IsAliveClosure、ScanWeakRefClosure。
IsAliveClosure is_alive(this);
ScanWeakRefClosure scan_weak_ref(this);
(3).清空ageTable和to区。
age_table()->clear();
to()->clear(SpaceDecorator::Mangle);
(4).在初始化堆的过程,会创建一个覆盖整个空间的数组GenRemSet,数组每个字节对应于堆的512字节,用于遍历新生代和老年代空间,这里对GenRemSet进行初始化准备。
gch->rem_set()->prepare_for_younger_refs_iterate(false);
(5).准备FastEvacuateFollowersClosure。
FastScanClosure fsc_with_no_gc_barrier(this, false);
FastScanClosure fsc_with_gc_barrier(this, true);
set_promo_failure_scan_stack_closure(&fsc_with_no_gc_barrier);
FastEvacuateFollowersClosure evacuate_followers(gch, _level, this,
&fsc_with_no_gc_barrier,
&fsc_with_gc_barrier);
3.调用GenCollectedHeap的gen_process_strong_roots()将当前代上的根对象复制到转移空间中。
gch->gen_process_strong_roots(_level,
true, // Process younger gens, if any,
// as strong roots.
true, // activate StrongRootsScope
false, // not collecting perm generation.
SharedHeap::SO_AllClasses,
&fsc_with_no_gc_barrier,
true, // walk *all* scavengable nmethods
&fsc_with_gc_barrier);
4.递归处理根集对象的引用对象。
// "evacuate followers".
evacuate_followers.do_void();
5.处理发现的引用。
FastKeepAliveClosure keep_alive(this, &scan_weak_ref);
ReferenceProcessor* rp = ref_processor();
rp->setup_policy(clear_all_soft_refs);
rp->process_discovered_references(&is_alive, &keep_alive, &evacuate_followers,
NULL);
6.若没有发生晋升失败:
(1).那么此刻eden区和from区的对象应该已经全部转移了,将调用clear()情况这两片内存区域 。
if (!promotion_failed()) {
// Swap the survivor spaces.
eden()->clear(SpaceDecorator::Mangle);
from()->clear(SpaceDecorator::Mangle);
(2).交换from和to区域,为下次gc做准备。
swap_spaces();
swap_spaces只是交换了_from_space和_to_space的起始地址,并设置eden的下一片需要进行压缩的区域为现在的from区(与TenuredGeneration的标记-压缩-清理垃圾回收相关,用来标志各内存区的压缩顺序),即原来的to区,而新的from区的下一片需要进行压缩的区域为为NULL。
void DefNewGeneration::swap_spaces() {
ContiguousSpace* s = from();
_from_space = to();
_to_space = s;
eden()->set_next_compaction_space(from());
// The to-space is normally empty before a compaction so need
// not be considered. The exception is during promotion
// failure handling when to-space can contain live objects.
from()->set_next_compaction_space(NULL);
//...
}
(3).计算新的survior区域的对象进入老年代的经历的MinorGC次数阈值。
// Set the desired survivor size to half the real survivor space
_tenuring_threshold =
age_table()->compute_tenuring_threshold(to()->capacity()/HeapWordSize);
(4).当gc成功,会重新计算gc超时的时间计数。
AdaptiveSizePolicy* size_policy = gch->gen_policy()->size_policy();
size_policy->reset_gc_overhead_limit_count();
7.若发生了晋升失败,即老年代没有足够的内存空间用以存放新生代所晋升的对象: (1).恢复晋升失败对象的markOop(被标记的活跃对象的markword内容为转发指针,指向经过复制后对象的新地址)。
remove_forwarding_pointers();
remove_forwarding_pointers()会调用RemoveForwardPointerClosure对eden和from区内的对象进行遍历,RemoveForwardPointerClosure将调用其do_object()初始化eden和from区所有对象的对象头部分。
void DefNewGeneration::remove_forwarding_pointers() {
RemoveForwardPointerClosure rspc;
eden()->object_iterate(&rspc);
from()->object_iterate(&rspc);
//...assert
while (!_objs_with_preserved_marks.is_empty()) {
oop obj = _objs_with_preserved_marks.pop();
markOop m = _preserved_marks_of_objs.pop();
obj->set_mark(m);
}
_objs_with_preserved_marks.clear(true);
_preserved_marks_of_objs.clear(true);
在晋升失败处理的handle_promotion_failure()中,会将晋升失败对象以<oop, markOop>作为一对分别保存在_objs_with_preserved_marks和_preserved_marks_of_objs栈中,这里就会恢复晋升失败对象的对象头,并清除这两个栈。
(2).仍然需要交换from和to区域,设置from的下一片需要进行压缩的区域为to
swap_spaces();
from()->set_next_compaction_space(to());
当没有晋升失败是,gc成功,会清空eden和from区、交换from和to区、survivor区对象成熟阈值调整等,以准备下次gc;而当晋升失败时,虽然会在后面交换from和to区,但是并不会清空eden和from区,而是会清空eden和from区所有对象的对象头,而只恢复晋升失败部分的对象头(加上to区的部分就是全部活跃对象了),这样,在随后触发的FullGC中能够对From和To区进行压缩处理。
(3).设置堆的MinorGC失败标记,并通知老年代(更高的内存代)晋升失败,比如在ConcurrentMarkSweepGeneration会根据配置进行dump输出以供JVM问题诊断
gch->set_incremental_collection_failed();
// Inform the next generation that a promotion failure occurred.
_next_gen->promotion_failure_occurred();
8.设置from和to区域的并发遍历指针的安全值为碰撞指针所在位置,并更新堆的最后一次gc的时间
from()->set_concurrent_iteration_safe_limit(from()->top());
to()->set_concurrent_iteration_safe_limit(to()->top());
SpecializationStats::print();
update_time_of_last_gc(os::javaTimeMillis());
下面将分别对根集对象标记、活跃对象标记、引用处理进行分析:
二、DefNewGeneration的根集对象标记过程:
在分析gen_process_strong_roots()之前,首先看下处理函数会做哪些工作: 处理函数封装在之前构造的FastScanClosure中,而FastScanClosure的do_oop()调用了的工作函数do_oop_work()。让我们看看do_oop_work()究竟做了什么。 (1).这里使用模板函数来解决压缩指针的不同类型(实际的oop和压缩指针narrowOop)问题,并当对象非空时,获取该oop/narrowOop对象(narrowOop需要进行指针解压)
T heap_oop = oopDesc::load_heap_oop(p);
// Should we copy the obj?
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
(2).若该对象在遍历区域内(_boudary是在FastScanClosure初始化的时候,为初始化时指定代的结束地址,与当前遍历代的起始地址_gen_boundary共同作为对象的访问边界,故新生代DefNewGeneration会将其自身内存代和更低的内存代的活跃对象都标记复制到to区域中),若该对象没有被标记过,即其标记状态不为marked_value,就会将该对象复制到to区域内,随后根据是否使用指针压缩将新的对象地址进行压缩
if ((HeapWord*)obj < _boundary) {
assert(!_g->to()->is_in_reserved(obj), "Scanning field twice?");
oop new_obj = obj->is_forwarded() ? obj->forwardee()
: _g->copy_to_survivor_space(obj);
oopDesc::encode_store_heap_oop_not_null(p, new_obj);
}
copy_to_survivor_space()的过程如下: 当该对象占用空间小于应当直接移动到老年代的阈值时,就会将其分配到to区
size_t s = old->size();
oop obj = NULL;
// Try allocating obj in to-space (unless too old)
if (old->age() < tenuring_threshold()) {
obj = (oop) to()->allocate(s);
}
否则会尝试将该对象晋升,若晋升失败,则调用handle_promotion_failure()处理
if (obj == NULL) {
obj = _next_gen->promote(old, s);
if (obj == NULL) {
handle_promotion_failure(old);
return old;
}
}
将原对象的数据内容复制到to区域新分配的对象上,并增加该对象的复制计数和更新ageTable (Prefetch使用的是目标架构的prefetch指令,用于将指定地址和长度的内存预取到cache,用于提升存取性能)
else {
// Prefetch beyond obj
const intx interval = PrefetchCopyIntervalInBytes;
Prefetch::write(obj, interval);
// Copy obj
Copy::aligned_disjoint_words((HeapWord*)old, (HeapWord*)obj, s);
// Increment age if obj still in new generation
obj->incr_age();
age_table()->add(obj, s);
}
最后调用forward_to()设置原对象的对象头为转发指针(表示该对象已被复制,并指明该对象已经被复制到什么位置)
// Done, insert forward pointer to obj in this header
old->forward_to(obj);
接下来分析gen_process_strong_roots(): 现在考虑一个问题:我们知道,被根对象所触及的所有对象都是活跃对象,那么如何确定一个内存代中的活跃对象呢?或者换个思路,内存代中哪些对象是不可触及的垃圾对象呢?如果其他内存代没有指向该对象的引用并且该对象也没有被内存代内其他对象引用,那么该对象就是一个垃圾对象。据此,把内存代内活跃对象的处理分为两步:第一步,将内存代内正常的根对象和其他内存代内直接引用的内存代内的对象移动到To区域,这些对象作为活跃对象(虽然其他内存代的对象可能在下次Full GC成为垃圾对象,但显然Minor GC显然不能将这些对象当做垃圾对象),这样,活跃对象的引用判断范围就缩小到了当前内存代,内存代内剩下的对象只要不是被这些活跃对象所引用,那么就必然是垃圾对象了;第二步,递归遍历这些对象,将其所引用的在该内存代的对象移动到To区域。最终,剩下的对象就是垃圾对象了。 1.调用SharedHeap的process_strong_roots()处理根集对象,在当前内存代(新生代的eden和from区)的根集对象将会被复制到to区
if (!do_code_roots) {
SharedHeap::process_strong_roots(activate_scope, collecting_perm_gen, so,
not_older_gens, NULL, older_gens);
} else {
bool do_code_marking = (activate_scope || nmethod::oops_do_marking_is_active());
CodeBlobToOopClosure code_roots(not_older_gens, /*do_marking=*/ do_code_marking);
SharedHeap::process_strong_roots(activate_scope, collecting_perm_gen, so,
not_older_gens, &code_roots, older_gens);
}
结合FastScanClosure可知,process_strong_roots()主要将当前内存代上的正常根对象复制到To区域。 2.处理更低的内存代
if (younger_gens_as_roots) {
if (!_gen_process_strong_tasks->is_task_claimed(GCH_PS_younger_gens)) {
for (int i = 0; i < level; i++) {
not_older_gens->set_generation(_gens[i]);
_gens[i]->oop_iterate(not_older_gens);
}
not_older_gens->reset_generation();
}
}
(1).内存代的oop_iterate()是调用space_iterate()对该内存代的内存空间进行遍历
//定义在/hotspot/src/share/vm/memory/generation.cpp中
void Generation::oop_iterate(OopClosure* cl) {
GenerationOopIterateClosure blk(cl, _reserved);
space_iterate(&blk);
}
(2).space_iterate()由Generation的实现类重写,以OneContigSpaceCardGeneration为例(后面会处理更高的内存代,这里DefNewGeneration并没有更低的内存代),将遍历代上的内存空间。
void OneContigSpaceCardGeneration::space_iterate(SpaceClosure* blk,
bool usedOnly) {
blk->do_space(_the_space);
}
(3).GenerationOopIterateClosure的do_space()如下:
virtual void do_space(Space* s) {
s->object_iterate(_cl);
}
(4).space的oop_iterate()根据Eden和from/to的实现如下:
void ContiguousSpace::oop_iterate(MemRegion mr, OopClosure* blk) {
//...
HeapWord* obj_addr = block_start(mr.start());
HeapWord* t = mr.end();
// Handle first object specially.
oop obj = oop(obj_addr);
SpaceMemRegionOopsIterClosure smr_blk(blk, mr);
obj_addr += obj->oop_iterate(&smr_blk);
while (obj_addr < t) {
oop obj = oop(obj_addr);
assert(obj->is_oop(), "expected an oop");
obj_addr += obj->size();
// If "obj_addr" is not greater than top, then the
// entire object "obj" is within the region.
if (obj_addr <= t) {
obj->oop_iterate(blk);
} else {
// "obj" extends beyond end of region
obj->oop_iterate(&smr_blk);
break;
}
};
}
该函数的作用是遍历该区域的起始地址到空闲分配指针之间的所有对象,并调用对象的oop_iterate()进行处理。
(5).oop是在堆上的对象的基类型,其oop_iterate()调用了Klass的oop_oop_iterate##nv_suffix()
inline int oopDesc::oop_iterate(OopClosureType* blk) { \
SpecializationStats::record_call(); \
return blueprint()->oop_oop_iterate##nv_suffix(this, blk); \
}
(6).oop_oop_iterate##nv_suffix()由具体的Klass子类(如对象在堆上的实现instanceKlass)实现,以访问和处理其所包含的引用对象
#define InstanceKlass_OOP_OOP_ITERATE_DEFN(OopClosureType, nv_suffix) \
\
int instanceKlass::oop_oop_iterate##nv_suffix(oop obj, OopClosureType* closure) { \
SpecializationStats::record_iterate_call##nv_suffix(SpecializationStats::ik);\
/* header */ \
if (closure->do_header()) { \
obj->oop_iterate_header(closure); \
} \
InstanceKlass_OOP_MAP_ITERATE( \
obj, \
SpecializationStats:: \
record_do_oop_call##nv_suffix(SpecializationStats::ik); \
(closure)->do_oop##nv_suffix(p), \
assert_is_in_closed_subset) \
return size_helper(); \
}
instanceKlass的OopMapBlock描述了在实例对象空间中一连串引用类型域的起始位置和数量,而InstanceKlass_OOP_MAP_ITERATE(是一个语句块)会遍历OopMapBlock的所有块
#define InstanceKlass_OOP_MAP_ITERATE(obj, do_oop, assert_fn) \
{ \
/* Compute oopmap block range. The common case \
is nonstatic_oop_map_size == 1. */ \
OopMapBlock* map = start_of_nonstatic_oop_maps(); \
OopMapBlock* const end_map = map + nonstatic_oop_map_count(); \
if (UseCompressedOops) { \
while (map < end_map) { \
InstanceKlass_SPECIALIZED_OOP_ITERATE(narrowOop, \
obj->obj_field_addr<narrowOop>(map->offset()), map->count(), \
do_oop, assert_fn) \
++map; \
} \
} else { \
while (map < end_map) { \
InstanceKlass_SPECIALIZED_OOP_ITERATE(oop, \
obj->obj_field_addr<oop>(map->offset()), map->count(), \
do_oop, assert_fn) \
++map; \
} \
} \
}
InstanceKlass_SPECIALIZED_OOP_ITERATE如下:
#define InstanceKlass_SPECIALIZED_OOP_ITERATE( \
T, start_p, count, do_oop, \
assert_fn) \
{ \
T* p = (T*)(start_p); \
T* const end = p + (count); \
while (p < end) { \
(assert_fn)(p); \
do_oop; \
++p; \
} \
}
其中T为所要处理的对象的指针或压缩指针,start_p为OopMapBlock中引用域的起始地址,count为OopMapBlock中引用的数量,do_oop为引用的处理,assert_fn为断言,该宏所定义的语句块就是将对象引用域的引用调用FastScanClosure的do_oop_nv进行处理。 所以,对更低内存代的遍历和处理就是把更低内存代的对象在DefNewGeneration内存代所引用的对象移动到To区域。
3.处理更高的内存代
for (int i = level+1; i < _n_gens; i++) {
older_gens->set_generation(_gens[i]);
rem_set()->younger_refs_iterate(_gens[i], older_gens);
older_gens->reset_generation();
}
类似地,把更高内存代的对象在DefNewGeneration内存代所引用的对象移动到To区域。这样就完成了第一步,将回收范围限定在DefNewGeneration内存代内。
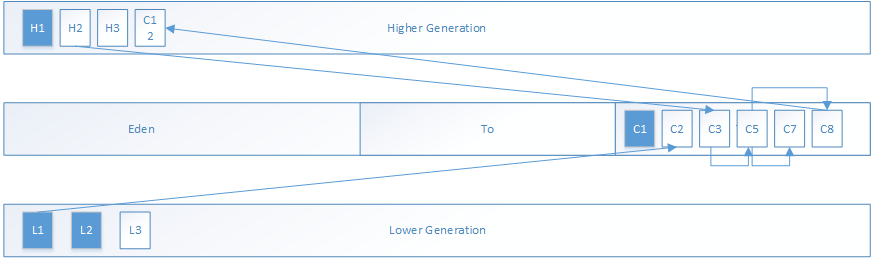
假设堆上有如图所示的对象引用模型:其中深色对象为根对象,箭头代表对象的引用关系,我们主要关注当前内存代(DefNewGeneration)的对象和其处理过程。
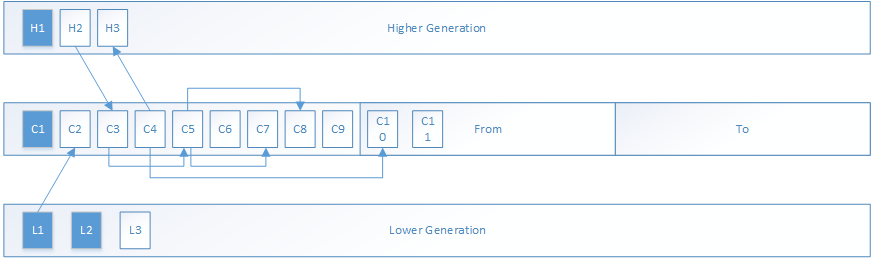
那么根集对象的处理将如下:
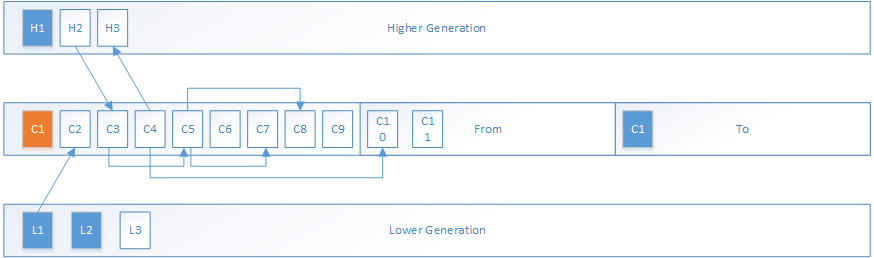
遍历所有的根对象,将在DefNewGeneration的根对象复制到To区域中,其中橙色对象表示该根对象已被复制移动到To空间,其头部为转发指针:
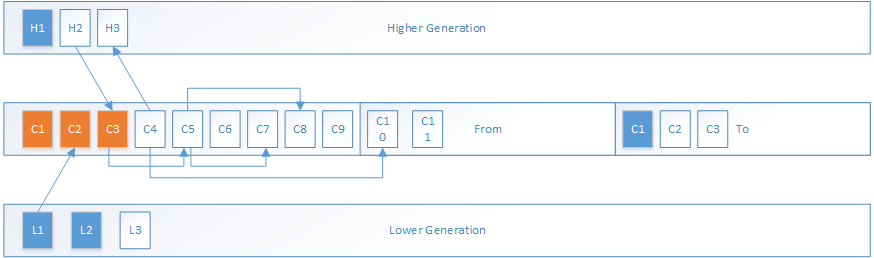
将更高或更低内存代所引用的在DefNewGeneration中的对象复制到To区域中
三、DefNewGeneration的存活对象的递归标记过程:
在分析递归标记活跃对象的过程之前,不妨先了解一下递归标记所使用的cheney算法。 在广优先遍历扫描活跃对象的过程中,对于所需的遍历队列,将复用to的从空闲指针开始的一段空间作为隐式队列。在之前,根集对象已经被拷贝到to区域的空闲空间,而scanned指针仍然停留在没有复制根集对象时空闲指针的位置,即scanned指针到当前空闲分配指针(to()->top())的这段空间保存着已经标记的根集对象,所以只需要继续遍历这段空间的根集对象,将发现的引用对象复制到to区域后,让scanned指针更新到这段空间的结束位置,而若还有未标记的对象的话,那么,空间指针必然又前进了一段距离,继续遍历这段新的未处理空间的对象,直至scanned指针追上空闲分配指针即可 FastEvacuateFollowersClosure的do_void()将完成递归标记工作: 当各分代的空闲分配指针不在变化时,说明所有可触及对象都已经递归标记完成,否则,将调用oop_since_save_marks_iterate()进行遍历标记。
void DefNewGeneration::FastEvacuateFollowersClosure::do_void() {
do {
_gch->oop_since_save_marks_iterate(_level, _scan_cur_or_nonheap,
_scan_older);
} while (!_gch->no_allocs_since_save_marks(_level));
guarantee(_gen->promo_failure_scan_is_complete(), "Failed to finish scan");
}
1.循环条件oop_since_save_marks_iterate()是对当前代、更高的内存代以及永久代检查其scanned指针_saved_mark_word是否与当前空闲分配指针位置相同,即检查scanned指针是否追上空闲分配指针
bool GenCollectedHeap::no_allocs_since_save_marks(int level) {
for (int i = level; i < _n_gens; i++) {
if (!_gens[i]->no_allocs_since_save_marks()) return false;
}
return perm_gen()->no_allocs_since_save_marks();
}
在DefNewGeneration中,eden和from区的分配指针不应当有所变化,只需要检查to区的空闲分配指针位置是否变化即可
bool DefNewGeneration::no_allocs_since_save_marks() {
assert(eden()->saved_mark_at_top(), "Violated spec - alloc in eden");
assert(from()->saved_mark_at_top(), "Violated spec - alloc in from");
return to()->saved_mark_at_top();
}
2.循环处理oop_since_save_marks_iterate(): (1).oop_since_save_marks_iterate()是对当前代、更高的内存代以及永久代的对象遍历处理
#define GCH_SINCE_SAVE_MARKS_ITERATE_DEFN(OopClosureType, nv_suffix) \
void GenCollectedHeap:: \
oop_since_save_marks_iterate(int level, \
OopClosureType* cur, \
OopClosureType* older) { \
_gens[level]->oop_since_save_marks_iterate##nv_suffix(cur); \
for (int i = level+1; i < n_gens(); i++) { \
_gens[i]->oop_since_save_marks_iterate##nv_suffix(older); \
} \
perm_gen()->oop_since_save_marks_iterate##nv_suffix(older); \
}
那么为什么要处理更高的内存代对象?因为在复制过程中,有对象通过晋升移动到了更高的内存代。 不过为什么老年代TenuredGeneration不像ConcurrentMarkSweepGeneration一样维护一个晋升对象的链表PromotionInfo来加快晋升对象的处理呢?
oop_since_save_marks_iterate##nv_suffix()在DefNewGeneration中的定义如下,实际上是调用eden、to、from区的同名函数进行处理,并更新各区的空闲分配指针。
#define DefNew_SINCE_SAVE_MARKS_DEFN(OopClosureType, nv_suffix) \
\
void DefNewGeneration:: \
oop_since_save_marks_iterate##nv_suffix(OopClosureType* cl) { \
cl->set_generation(this); \
eden()->oop_since_save_marks_iterate##nv_suffix(cl); \
to()->oop_since_save_marks_iterate##nv_suffix(cl); \
from()->oop_since_save_marks_iterate##nv_suffix(cl); \
cl->reset_generation(); \
save_marks(); \
}
(2).之前说到,在空间分配指针到scanned指针之间的区域就是已分配但未扫描的对象,所以在这里将对这片区域内的对象调用遍历函数进行处理,以标记遍历的对象所引用的对象,并保存新的scanned指针。
#define ContigSpace_OOP_SINCE_SAVE_MARKS_DEFN(OopClosureType, nv_suffix) \
\
void ContiguousSpace:: \
oop_since_save_marks_iterate##nv_suffix(OopClosureType* blk) { \
HeapWord* t; \
HeapWord* p = saved_mark_word(); \
assert(p != NULL, "expected saved mark"); \
\
const intx interval = PrefetchScanIntervalInBytes; \
do { \
t = top(); \
while (p < t) { \
Prefetch::write(p, interval); \
debug_only(HeapWord* prev = p); \
oop m = oop(p); \
p += m->oop_iterate(blk); \
} \
} while (t < top()); \
\
set_saved_mark_word(p); \
下面继续递归处理活跃对象的过程:
递归标记的开始时,Scanned指针为To区域的起点,Top指向空闲区域的起点,Scanned到Top之间的对象就是需要进行递归标记的对象

第一轮递归标记后,根集对象中C3引用了C5,C5被移动至To区域,Scanned指针指向已处理完的对象,这时C1、C2、C3均已被遍历完毕,现在C5需要被遍历。其中绿色对象代表被移动到To区域的非根集对象。

第二轮递归标记后,C5引用了C7、C8,这两个对象被移动到了To区域,这时C5已被遍历完毕,现在C7、C8需要被遍历

第三轮标记没有任何引用被发现,Scanned指针追上了Top指针,所有存活对象被遍历完毕

在以上分析的基础之上,我们假设还有一个C12为C8所引用,但是To区域没有足够的空间,那么C12就会晋升到更高的内存代(老年代)
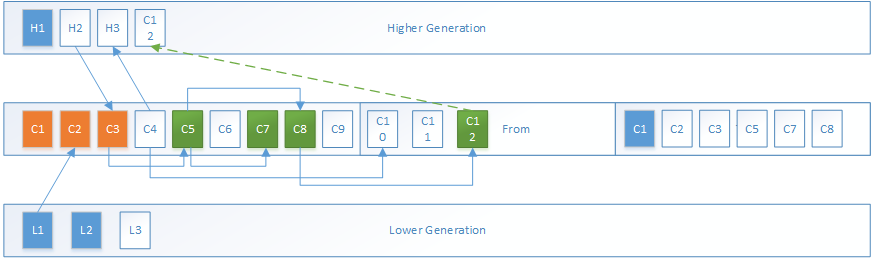
最后,将清理Eden和From区域,并交换From和To区域
四、DefNewGeneration的引用处理:
1.处理_discoveredSoftRefs数组中的软引用
// Soft references
{
TraceTime tt("SoftReference", trace_time, false, gclog_or_tty);
process_discovered_reflist(_discoveredSoftRefs, _current_soft_ref_policy, true,
is_alive, keep_alive, complete_gc, task_executor);
}
update_soft_ref_master_clock();
2.处理_discoveredWeakRefs数组中的弱引用
// Weak references
{
TraceTime tt("WeakReference", trace_time, false, gclog_or_tty);
process_discovered_reflist(_discoveredWeakRefs, NULL, true,
is_alive, keep_alive, complete_gc, task_executor);
}
3.处理_discoveredFinalRefs数组中的Final引用
// Final references
{
TraceTime tt("FinalReference", trace_time, false, gclog_or_tty);
process_discovered_reflist(_discoveredFinalRefs, NULL, false,
is_alive, keep_alive, complete_gc, task_executor);
}
4.处理_discoveredPhantomRefs列表中的影子引用
// Phantom references
{
TraceTime tt("PhantomReference", trace_time, false, gclog_or_tty);
process_discovered_reflist(_discoveredPhantomRefs, NULL, false,
is_alive, keep_alive, complete_gc, task_executor);
}
5.处理JNI弱全局引用
{
TraceTime tt("JNI Weak Reference", trace_time, false, gclog_or_tty);
if (task_executor != NULL) {
task_executor->set_single_threaded_mode();
}
process_phaseJNI(is_alive, keep_alive, complete_gc);
}
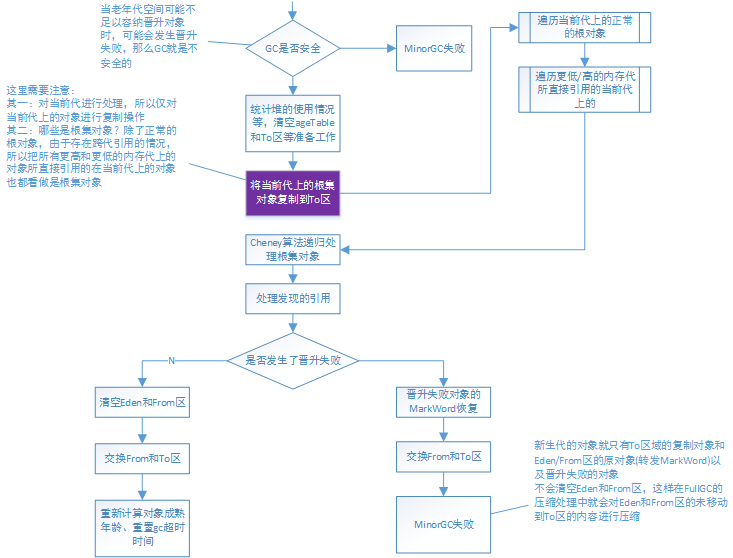
process_discovered_reflist()过程比较复杂,这里就不继续进行了,有兴趣的可以自行分析,DefNewGeneration的GC流程图如下:
分类: Hotspot源码探索
TenuredGeneration的GC过程
老年代TenuredGeneration所使用的垃圾回收算法是标记-压缩-清理算法。在回收阶段,将标记对象越过堆的空闲区移动到堆的另一端,所有被移动的对象的引用也会被更新指向新的位置。看起来像是把杂陈的箱子一股脑推到房间的一侧一样。 下面,从TenuredGeneration的collect()开始,分析TenuredGeneration的GC过程。
void TenuredGeneration::collect(bool full,
bool clear_all_soft_refs,
size_t size,
bool is_tlab) {
retire_alloc_buffers_before_full_gc();
OneContigSpaceCardGeneration::collect(full, clear_all_soft_refs,
size, is_tlab);
}
转而调用了父类OneContigSpaceCardGeneration的collect():
void OneContigSpaceCardGeneration::collect(bool full,
bool clear_all_soft_refs,
size_t size,
bool is_tlab) {
SpecializationStats::clear();
// Temporarily expand the span of our ref processor, so
// refs discovery is over the entire heap, not just this generation
ReferenceProcessorSpanMutator
x(ref_processor(), GenCollectedHeap::heap()->reserved_region());
GenMarkSweep::invoke_at_safepoint(_level, ref_processor(), clear_all_soft_refs);
SpecializationStats::print();
}
接着看GenMarkSweep的invoke_at_safepoint(): 1.前面的实现都是进行一些gc前的初始化工作和统计工作 (1).设置引用处理器和引用处理策略为clear_all_softrefs
_ref_processor = rp;
rp->setup_policy(clear_all_softrefs);
(2).增加调用计数,并统计gc前的堆的使用大小
gch->perm_gen()->stat_record()->invocations++;
// Capture heap size before collection for printing.
size_t gch_prev_used = gch->used();
(3).保存当前内存代和更低的内存代、以及永久代的已使用区域
gch->save_used_regions(level, true /* perm */);
(4).创建遍历栈
allocate_stacks();
2.接下来就是MarkSweepCompact算法的实现了,算法的实现分为四个阶段: mark_sweep_phase1-4,其中: mark_sweep_phase1:递归标记所有活跃对象 mark_sweep_phase2:计算所有活跃对象在压缩后的偏移地址 mark_sweep_phase3:更新对象的引用地址 mark_sweep_phase4:移动所有活跃/存活对象到新的位置
mark_sweep_phase1(level, clear_all_softrefs);
mark_sweep_phase2();
//...
mark_sweep_phase3(level);
//...
mark_sweep_phase4();
3.在将对象标记入栈的时候,会将原MarkWord保存在_preserved_marks,MarkWord被设置为转发指针,当四个处理阶段结束后,恢复这些”废弃”对象的MarkWord,以防止下次GC时干扰标记,虽然没有真正“清空”死亡对象的内存空间,但由于对象引用将指向新的位置,原来的这些对象所占用内存空间将会被看作是空闲空间。
restore_marks();
保存各内存代的mark指针为当前空闲分配指针
gch->save_marks();
4.一些gc后的处理工作,例如清空所有遍历栈、更新堆的一些使用信息和最近一次gc发生的时间等
mark_sweep_phase1:递归标记所有活跃对象
1.与新生代类似,标记根集对象。
follow_root_closure.set_orig_generation(gch->get_gen(level));
gch->gen_process_strong_roots(level,
false, // Younger gens are not roots.
true, // activate StrongRootsScope
true, // Collecting permanent generation.
SharedHeap::SO_SystemClasses,
&follow_root_closure,
true, // walk code active on stacks
&follow_root_closure);
follow_root_closure的工作函数如下:
void MarkSweep::FollowRootClosure::do_oop(oop* p) { follow_root(p); }
void MarkSweep::FollowRootClosure::do_oop(narrowOop* p) { follow_root(p); }
不考虑压缩指针的解压,follow_root()实现如下:
template <class T> inline void MarkSweep::follow_root(T* p) {
assert(!Universe::heap()->is_in_reserved(p),
"roots shouldn't be things within the heap");
//...
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
if (!obj->mark()->is_marked()) {
mark_object(obj);
obj->follow_contents();
}
}
follow_stack();
}
对于没有被标记的活跃对象,follow_root()会调用mark_object()标记该对象(设置转发指针),随后调用follow_contents()和follow_stack()处理该对象,根据借助栈进行递归标记的思想,递归标记的过程就是遍历根集对象,把根集对象进行标记后,将其所引用的对象压入栈,然后遍历栈中元素,递归标记活跃对象及其所引用的对象,直至栈空为止。
oop_follow_contents()就应该是将当前活跃对象所引用的对象标记并压入栈的过程:
void instanceKlass::oop_follow_contents(oop obj) {
assert(obj != NULL, "can't follow the content of NULL object");
obj->follow_header();
InstanceKlass_OOP_MAP_ITERATE( \
obj, \
MarkSweep::mark_and_push(p), \
assert_is_in_closed_subset)
}
InstanceKlass_OOP_MAP_ITERATE()语句块在”源码分析HotSpot GC过程(二):DefNewGeneration的GC过程“一文中已经分析过了,其作用就是遍历对象的引用域,使用OopClosure进行处理。 故follow_contents()处理活跃对象就是将该对象标记后,将该对象所引用的对象标记后压入_marking_stack。那么,可以预见,follow_stack()的处理必然就是遍历栈中的对象,并递归地将其引用对象标记和入栈直到栈空为止,那么下面看看follow_stack()的具体实现:
void MarkSweep::follow_stack() {
do {
while (!_marking_stack.is_empty()) {
oop obj = _marking_stack.pop();
assert (obj->is_gc_marked(), "p must be marked");
obj->follow_contents();
}
// Process ObjArrays one at a time to avoid marking stack bloat.
if (!_objarray_stack.is_empty()) {
ObjArrayTask task = _objarray_stack.pop();
objArrayKlass* const k = (objArrayKlass*)task.obj()->blueprint();
k->oop_follow_contents(task.obj(), task.index());
}
} while (!_marking_stack.is_empty() || !_objarray_stack.is_empty());
}
那么结果如何呢?好消息是,follow_stack()的前半段确实如此,坏消息是栈空了并不一定会结束,因为,光有一个_marking_stack栈是不够的,对于数组对象的引用如果全都放在标记栈中时,当数组非常大时,就会出现爆栈的问题,这里就需要一个_objArrayKlass和一个ObjArrayTask用来处理数组对象的引用问题。具体的实现这里就不再深入下去了。
分析完活跃对象的处理过程,我们回到mark_sweep_phase1()中: 注意gen_process_strong_roots()传入的younger_gens_as_roots参数为false,即不会对更低的内存代进行处理,因为在SharedHeap::process_strong_roots的处理过程中,就已经标记了所有的活跃对象。但是,如果存在更高内存代,那么更低内存代是无法将更高内存代的没有被引用的对象当做垃圾对象处理的,所以虽然不会再处理更低的内存代,但仍要将更高内存代的对象当做根集对象递归遍历。(Hotspot中TenuredGeneration没有更高的内存代了) 2.递归标记发现的引用
// Process reference objects found during marking
{
ref_processor()->setup_policy(clear_all_softrefs);
ref_processor()->process_discovered_references(
&is_alive, &keep_alive, &follow_stack_closure, NULL);
}
3.卸载不再使用的类
// Follow system dictionary roots and unload classes
bool purged_class = SystemDictionary::do_unloading(&is_alive);
4.部分类卸载后,需要清理CodeCache,此外,需要清空标记栈
// Follow code cache roots
CodeCache::do_unloading(&is_alive, &keep_alive, purged_class);
follow_stack(); // Flush marking stack
5.部分类卸载后,更新存活类的子类、兄弟类、实现类的引用关系
follow_weak_klass_links();
6.清理未被标记的软引用和弱引用
follow_mdo_weak_refs();
7.删除拘留字符串表中未被标记的字符串对象
StringTable::unlink(&is_alive);
8.清理符号表中没有被引用的符号
SymbolTable::unlink();
mark_sweep_phase2:计算所有活跃对象在压缩后的偏移地址
void GenMarkSweep::mark_sweep_phase2() {
GenCollectedHeap* gch = GenCollectedHeap::heap();
Generation* pg = gch->perm_gen();
//...
VALIDATE_MARK_SWEEP_ONLY(reset_live_oop_tracking(false));
gch->prepare_for_compaction();
VALIDATE_MARK_SWEEP_ONLY(_live_oops_index_at_perm = _live_oops_index);
CompactPoint perm_cp(pg, NULL, NULL);
pg->prepare_for_compaction(&perm_cp);
}
GenCollectedHeap的prepare_for_compaction()如下:
void GenCollectedHeap::prepare_for_compaction() {
Generation* scanning_gen = _gens[_n_gens-1];
// Start by compacting into same gen.
CompactPoint cp(scanning_gen, NULL, NULL);
while (scanning_gen != NULL) {
scanning_gen->prepare_for_compaction(&cp);
scanning_gen = prev_gen(scanning_gen);
}
}
看到还记得在DefNewGeneration的GC分析中下一片压缩区域的设置么? 根据内存代的不同实现,如DefNewGeneration分为Eden区(EdenSpace,ContiguousSpace的子类)、From/To区(ContiguousSpace),TenuredGeneration只有一个_the_space区(ContiguousSpace),这里直接看ContiguousSpace对prepare_for_compaction的实现:
// Faster object search.
void ContiguousSpace::prepare_for_compaction(CompactPoint* cp) {
SCAN_AND_FORWARD(cp, top, block_is_always_obj, obj_size);
}
SCAN_AND_FORWARD(),该函数定义在/hotspot/src/share/vm/memory/space.hpp中 1.compact_top为压缩指针,指向压缩的目标内存空间的起始地址,在压缩地址计算的开始,指向当前内存区域的起始位置
HeapWord* compact_top; /* This is where we are currently compacting to. */ \
\
/* We're sure to be here before any objects are compacted into this \
* space, so this is a good time to initialize this: \
*/ \
set_compaction_top(bottom());
2.初始化CompactPoint,若CompactPoint的压缩区域为空,即这是内存代的第一片区域,那么初始化CompactPoint的压缩区域为内存代的第一片区域,初始化压缩指针为区域的起始地址,初始化区域的压缩的目标区域起始地址为该区域的起始地址,初始化压缩边界为区域边界(默认实现),若CompactPoint的压缩区域不为空,那么之前继续进行该区域的压缩工作,即初始化压缩指针为原压缩指针的值。
if (cp->space == NULL) { \
//assert
cp->space = cp->gen->first_compaction_space(); \
compact_top = cp->space->bottom(); \
cp->space->set_compaction_top(compact_top); \
cp->threshold = cp->space->initialize_threshold(); \
} else { \
compact_top = cp->space->compaction_top(); \
}
3.每经过MarkSweepAlwaysCompactCount次GC,就允许当前区域空间的MarkSweepDeadRatio%(TenuredSpace)/PermMarkSweepDeadRatio%(ContigPermSpace)大小被用来将死亡对象当做存活对象处理,这里姑且将这些对象称为弥留对象,把这片空间称为弥留空间好了(实际上并没有这样的明确定义)。
nt invocations = SharedHeap::heap()->perm_gen()->stat_record()->invocations;\
bool skip_dead = ((invocations % MarkSweepAlwaysCompactCount) != 0); \
\
size_t allowed_deadspace = 0; \
if (skip_dead) { \
const size_t ratio = allowed_dead_ratio(); \
allowed_deadspace = (capacity() * ratio / 100) / HeapWordSize; \
}
4.q为遍历指针,t为扫描边界,end_of_live为最后一个活跃对象的地址,LiveRange保存着死亡对象后面存活对象的地址范围,first_dead为第一个死亡对象的地址
HeapWord* q = bottom(); \
HeapWord* t = scan_limit(); \
\
HeapWord* end_of_live= q; /* One byte beyond the last byte of the last \
live object. */ \
HeapWord* first_dead = end();/* The first dead object. */ \
LiveRange* liveRange = NULL; /* The current live range, recorded in the \
first header of preceding free area. */ \
_first_dead = first_dead;
在边界内遍历,若当前遍历的对象被标记过,即这是一个活跃对象,那么为该对象计算压缩后的地址,设置转发指针,并更新压缩指针和最后一个活跃对象的地址,并继续遍历
while (q < t) {
if (block_is_obj(q) && oop(q)->is_gc_marked()) { \
/* prefetch beyond q */ \
Prefetch::write(q, interval); \
/* size_t size = oop(q)->size(); changing this for cms for perm gen */\
size_t size = block_size(q); \
compact_top = cp->space->forward(oop(q), size, cp, compact_top); \
q += size; \
end_of_live = q; \
}
否则,跳过死亡对象,遍历直到遇到一个活跃对象为止
else { \
/* run over all the contiguous dead objects */ \
HeapWord* end = q; \
do { \
/* prefetch beyond end */ \
Prefetch::write(end, interval); \
end += block_size(end); \
} while (end < t && (!block_is_obj(end) || !oop(end)->is_gc_marked()));
若仍有弥留空间可以用,那么在这片空间上调用insert_deadspace()构造弥留对象,当做活跃对象进行压缩的计算处理
if (allowed_deadspace > 0 && q == compact_top) { \
size_t sz = pointer_delta(end, q); \
if (insert_deadspace(allowed_deadspace, q, sz)) { \
compact_top = cp->space->forward(oop(q), sz, cp, compact_top); \
q = end; \
end_of_live = end; \
continue; \
} \
}
更新上一个LiveRange的活跃对象结束地址,这个活跃范围对象设置在死亡对象的MarkWord上,由于在死亡对象后遇到了一个新的活跃对象,于是需要重新构造一个LiveRange对象来记录下一片活跃对象的地址范围。
if (liveRange) { \
liveRange->set_end(q); \
}
liveRange = (LiveRange*)q; \
liveRange->set_start(end); \
liveRange->set_end(end);
保存首个死亡对象的地址,并继续遍历
/* see if this is the first dead region. */ \
if (q < first_dead) { \
first_dead = q; \
} \
\
/* move on to the next object */ \
q = end; \
}
循环结束,更新最后一个死亡对象的活跃对象范围、最后一个活跃对象的地址、第一个死亡对象的地址
if (liveRange != NULL) { \
liveRange->set_end(q); \
} \
_end_of_live = end_of_live; \
if (end_of_live < first_dead) { \
first_dead = end_of_live; \
} \
_first_dead = first_dead;
保存当前空间的压缩指针
cp->space->set_compaction_top(compact_top);
mark_sweep_phase3:更新对象的引用地址
1.adjust_root_pointer_closure和adjust_pointer_closure都是静态创建的对象引用地址调整函数的封装对象,这里将调用gen_process_strong_roots()并使用这两个处理函数调整根集对象指针的引用地址。
adjust_root_pointer_closure.set_orig_generation(gch->get_gen(level));
adjust_pointer_closure.set_orig_generation(gch->get_gen(level));
gch->gen_process_strong_roots(level,
false, // Younger gens are not roots.
true, // activate StrongRootsScope
true, // Collecting permanent generation.
SharedHeap::SO_AllClasses,
&adjust_root_pointer_closure,
false, // do not walk code
&adjust_root_pointer_closure);
adjust_root_pointer_closure()的工作函数如下:
void MarkSweep::AdjustPointerClosure::do_oop(oop* p) { adjust_pointer(p, _is_root); }
void MarkSweep::AdjustPointerClosure::do_oop(narrowOop* p) { adjust_pointer(p, _is_root); }
MarkSweep的adjust_pointer将会解析引用对象的MarkWord,若该引用对象已经被标记,就会解析转发指针,并设置引用地址为引用对象新的地址。
template <class T> inline void MarkSweep::adjust_pointer(T* p, bool isroot) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
oop new_obj = oop(obj->mark()->decode_pointer());
//...assert
if (new_obj != NULL) {
//...assert
oopDesc::encode_store_heap_oop_not_null(p, new_obj);
}
}
VALIDATE_MARK_SWEEP_ONLY(track_adjusted_pointer(p, isroot));
}
所以对引用地址的更新就是遍历各内存代对象/引用,若对象所引用的对象已经被标记,则更新其引用地址为转发指针所转向的新地址。 gen_process_strong_roots()完成了对初始根对象的引用地址更新
2.调整引用指针的引用地址
CodeBlobToOopClosure adjust_code_pointer_closure(&adjust_pointer_closure,
/*do_marking=*/ false);
gch->gen_process_weak_roots(&adjust_root_pointer_closure,
&adjust_code_pointer_closure,
&adjust_pointer_closure);
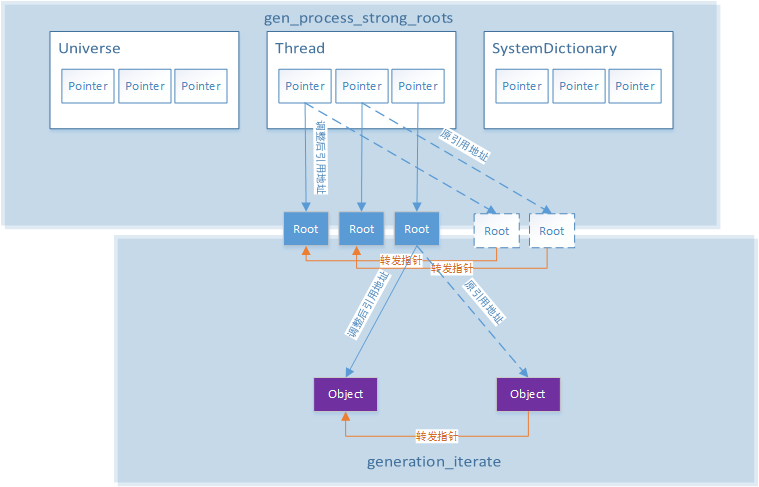
3.使用GenAdjustPointersClosure遍历各内存代,以更新引用对象的引用地址
GenAdjustPointersClosure blk;
gch->generation_iterate(&blk, true);
pg->adjust_pointers();
其基本思想如图所示:
mark_sweep_phase4:移动所有active对象到新的位置
1.永久代对象压缩,只有在永久代对象压缩后,实例才能获得正确的类数据地址
pg->compact();
2.使用GenCompactClosure遍历堆上的对象
GenCompactClosure blk;
gch->generation_iterate(&blk, true);
GenCollectedHeap的generation_iterate()将调用GenCompactClosure的do_generation()遍历各个内存代
void GenCollectedHeap::generation_iterate(GenClosure* cl,
bool old_to_young) {
if (old_to_young) {
for (int i = _n_gens-1; i >= 0; i--) {
cl->do_generation(_gens[i]);
}
} else {
for (int i = 0; i < _n_gens; i++) {
cl->do_generation(_gens[i]);
}
do_generation()实际上是调用各个内存代的compact()进行处理(因为各个内存代的区域组织形式不同,比如新生代有Eden和From/To区,而老年代只有一个区域存在)
class GenCompactClosure: public GenCollectedHeap::GenClosure {
public:
void do_generation(Generation* gen) {
gen->compact();
}
};
compact()调用了CompactibleSpace(ContiguousSpace的父类)的SCAN_AND_COMPACT()完成对象内容的复制
void CompactibleSpace::compact() {
SCAN_AND_COMPACT(obj_size);
}
SCAN_AND_COMPACT()定义在/hotspot/src/share/vm/memory/space.hpp中 (1).q是遍历指针,t是最后一个活跃对象的位置,记录最后一个活跃对象的位置,就不必再遍历全部内存区域,否则当gc后剩余的活跃对象较少时,将会进行很多不必要的遍历
HeapWord* q = bottom(); \
HeapWord* const t = _end_of_live; \
(2).跳过死亡对象区域
if (q < t && _first_dead > q && \
!oop(q)->is_gc_marked()) { \
//...
HeapWord* const end = _first_dead; \
\
while (q < end) { \
size_t size = obj_size(q); \
//...assert
q += size; \
}
当第一个死亡对象的地址与最后一个活跃对象的地址不相同时,即有连续多个死亡对象存在,那么第一个死亡对象的MarkWord就是之前保存的LiveRange,通过LiveRange可以获取下一个活跃对象的地址
if (_first_dead == t) { \
q = t; \
} else { \
/* $$$ Funky */ \
q = (HeapWord*) oop(_first_dead)->mark()->decode_pointer(); \
}
(3).开始遍历,对于死亡对象,同样通过LiveRange获取下一个存活对象的地址
const intx scan_interval = PrefetchScanIntervalInBytes; \
const intx copy_interval = PrefetchCopyIntervalInBytes; \
while (q < t) { \
if (!oop(q)->is_gc_marked()) { \
/* mark is pointer to next marked oop */ \
q = (HeapWord*) oop(q)->mark()->decode_pointer(); \
}
(4).复制原对象的数据内容到压缩后的地址,并初始化新的位置的对象的MarkWord
else { \
/* prefetch beyond q */ \
Prefetch::read(q, scan_interval); \
\
/* size and destination */ \
size_t size = obj_size(q); \
HeapWord* compaction_top = (HeapWord*)oop(q)->forwardee(); \
\
/* prefetch beyond compaction_top */ \
Prefetch::write(compaction_top, copy_interval); \
\
//...
Copy::aligned_conjoint_words(q, compaction_top, size); \
oop(compaction_top)->init_mark(); \
//...
q += size; \
}
我们以如下分代和引用模型为基础进行TenuredGeneration的GC分析: 其中蓝色对象为正常的根对象,箭头代表引用关系。
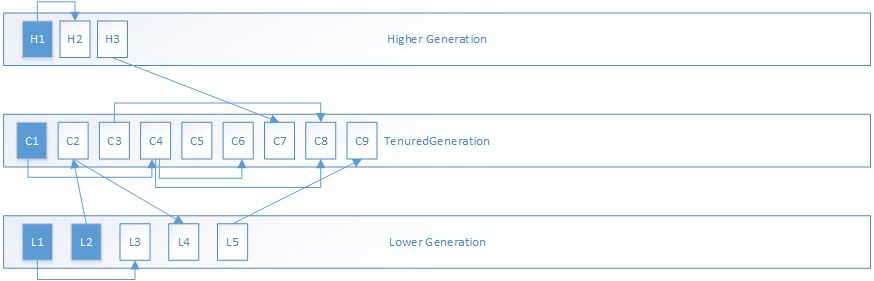
1.MarkSweepPhase1过程分为两步,第一步是递归标记所有根对象: 以根集对象C1为例,借助标记栈的标记过程如下,其中橙色对象为被标记的正常的根对象,绿色为被标记的其他对象:
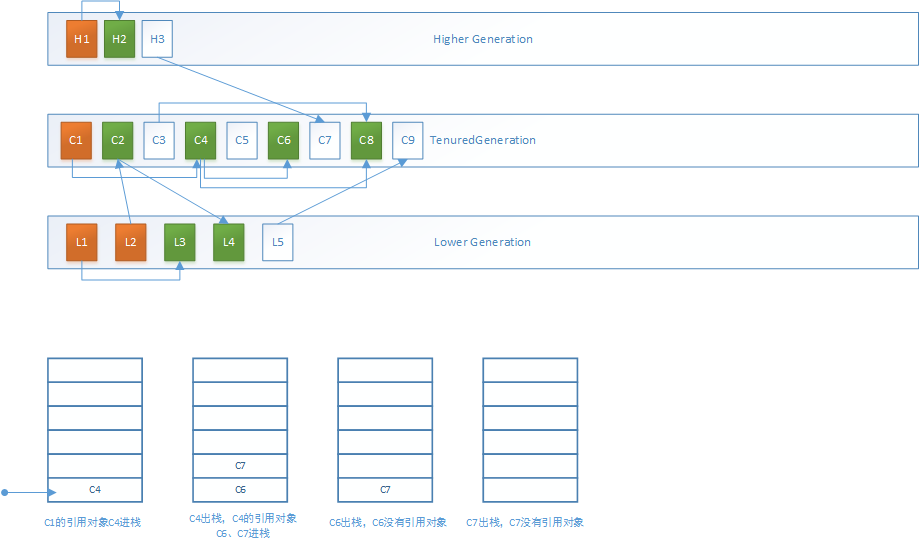
第二步是递归标记作为更高内存代的对象,这里即为H3,和其所引用的C7对象:
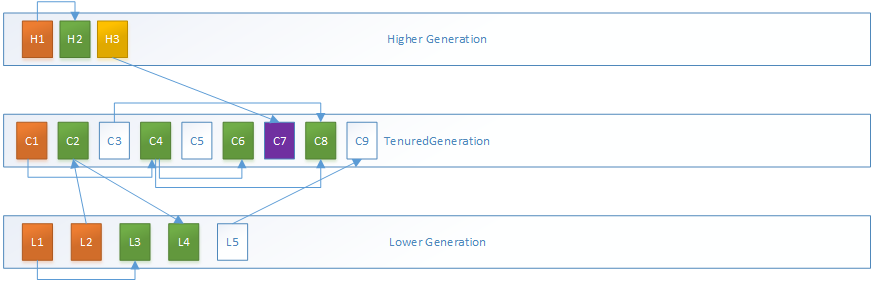
2.MarkSweepPhase2过程,以TenuredGeneration为代表进行分析: C3、C5、C9对象均为垃圾对象,由于前面没有垃圾对象,C1、C2的转发指针均指向自身所在地址
而C3是垃圾对象,C3的MarkWord被设置为LiveRange,指向前一块活跃对象的范围,而C4的转发指针将压缩到C3的起始地址

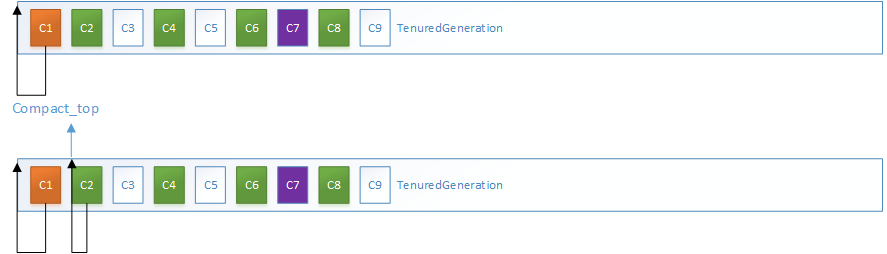
以此类推,计算所有活跃对象的转发地址和活跃范围,注意这里压缩指针位置是根据前一次的指针位置和前一个活跃对象的大小计算的

3.MarkSweepPhase3过程,这里C4、C6、C7、C8的压缩后地址均已发生变化,但对象内容尚未复制到新地址,所以以虚线边框浅色来代表这个”名义上存在的”新对象,并更新引用这些对象的指针地址:

4.MarkSweepPhase3过程,C4、C6、C7、C8的对象内容复制到新地址。

分类: Hotspot源码探索
ZGC gc策略及回收过程
源码文件:/src/hotspot/share/gc/z/zDirector.cpp
一、回收策略
main入口函数:
void ZDirector::run_service() {
// Main loop
while (_metronome.wait_for_tick()) {
sample_allocation_rate();
const GCCause::Cause cause = make_gc_decision();
if (cause != GCCause::_no_gc) {
ZCollectedHeap::heap()->collect(cause);
}
}
}
ZMetronome::wait_for_tick 是zgc定义的一个循环时钟函数,sample_allocation_rate函数则用于rule_allocation_rate策略估算可能oom的时间。重点关注:make_gc_decision函数,在判断从make_gc_decision函数返回的结果不是no_gc后,zgc将进行一次gc。
make_gc_decision函数:
GCCause::Cause ZDirector::make_gc_decision() const {
// Rule 0: Timer
if (rule_timer()) {
return GCCause::_z_timer;
}
// Rule 1: Warmup
if (rule_warmup()) {
return GCCause::_z_warmup;
}
// Rule 2: Allocation rate
if (rule_allocation_rate()) {
return GCCause::_z_allocation_rate;
}
// Rule 3: Proactive
if (rule_proactive()) {
return GCCause::_z_proactive;
}
// No GC
return GCCause::_no_gc;
}
make_gc_decision一共提供了4种被动gc策略:
rule 1:固定间隔时间
通过配置ZCollectionInterval参数,可以控制zgc在一个固定的时间间隔进行gc,默认值为0,表示不采用该策略,否则则判断从上次gc到现在的时间间隔是否大于ZCollectionInterval秒,是则gc。源码如下:
bool ZDirector::rule_timer() const {
if (ZCollectionInterval == 0) {
// Rule disabled
return false;
}
// Perform GC if timer has expired.
const double time_since_last_gc = ZStatCycle::time_since_last();
const double time_until_gc = ZCollectionInterval - time_since_last_gc;
log_debug(gc, director)("Rule: Timer, Interval: %us, TimeUntilGC: %.3lfs",
ZCollectionInterval, time_until_gc);
return time_until_gc <= 0;
}
rule 2:预热规则
is_warm函数判断gc次数是否已超过3次,是则不使用该策略。
注释说的很清楚,当gc次数少于3时,判断堆使用率达到10%/20%/30%时,使用该策略
bool ZDirector::rule_warmup() const {
if (is_warm()) {
// Rule disabled
return false;
}
// Perform GC if heap usage passes 10/20/30% and no other GC has been
// performed yet. This allows us to get some early samples of the GC
// duration, which is needed by the other rules.
const size_t max_capacity = ZHeap::heap()->current_max_capacity();
const size_t used = ZHeap::heap()->used();
const double used_threshold_percent = (ZStatCycle::ncycles() + 1) * 0.1;
const size_t used_threshold = max_capacity * used_threshold_percent;
log_debug(gc, director)("Rule: Warmup %.0f%%, Used: " SIZE_FORMAT "MB, UsedThreshold: " SIZE_FORMAT "MB",
used_threshold_percent * 100, used / M, used_threshold / M);
return used >= used_threshold;
}
bool ZDirector::is_warm() const {
return ZStatCycle::ncycles() >= 3;
}
// 位置:ZStat.cpp
uint64_t ZStatCycle::ncycles() {
return _ncycles; // gc次数
}
rule 3:分配速率预估
is_first函数判断如果是首次gc,则直接返回false。
ZAllocationSpikeTolerance默认值为2,分配速率策略采用正态分布模型预测内存分配速率,加上ZAllocationSpikeTolerance修正因子,可以覆盖超过99.9%的内存分配速率的可能性
bool ZDirector::rule_allocation_rate() const {
if (is_first()) {
// Rule disabled
return false;
}
// Perform GC if the estimated max allocation rate indicates that we
// will run out of memory. The estimated max allocation rate is based
// on the moving average of the sampled allocation rate plus a safety
// margin based on variations in the allocation rate and unforeseen
// allocation spikes.
// Calculate amount of free memory available to Java threads. Note that
// the heap reserve is not available to Java threads and is therefore not
// considered part of the free memory.
const size_t max_capacity = ZHeap::heap()->current_max_capacity();
const size_t max_reserve = ZHeap::heap()->max_reserve();
const size_t used = ZHeap::heap()->used();
const size_t free_with_reserve = max_capacity - used;
const size_t free = free_with_reserve - MIN2(free_with_reserve, max_reserve);
// Calculate time until OOM given the max allocation rate and the amount
// of free memory. The allocation rate is a moving average and we multiply
// that with an allocation spike tolerance factor to guard against unforeseen
// phase changes in the allocate rate. We then add ~3.3 sigma to account for
// the allocation rate variance, which means the probability is 1 in 1000
// that a sample is outside of the confidence interval.
const double max_alloc_rate = (ZStatAllocRate::avg() * ZAllocationSpikeTolerance) + (ZStatAllocRate::avg_sd() * one_in_1000);
const double time_until_oom = free / (max_alloc_rate + 1.0); // Plus 1.0B/s to avoid division by zero
// Calculate max duration of a GC cycle. The duration of GC is a moving
// average, we add ~3.3 sigma to account for the GC duration variance.
const AbsSeq& duration_of_gc = ZStatCycle::normalized_duration();
const double max_duration_of_gc = duration_of_gc.davg() + (duration_of_gc.dsd() * one_in_1000);
// Calculate time until GC given the time until OOM and max duration of GC.
// We also deduct the sample interval, so that we don't overshoot the target
// time and end up starting the GC too late in the next interval.
const double sample_interval = 1.0 / ZStatAllocRate::sample_hz;
const double time_until_gc = time_until_oom - max_duration_of_gc - sample_interval;
log_debug(gc, director)("Rule: Allocation Rate, MaxAllocRate: %.3lfMB/s, Free: " SIZE_FORMAT "MB, MaxDurationOfGC: %.3lfs, TimeUntilGC: %.3lfs",
max_alloc_rate / M, free / M, max_duration_of_gc, time_until_gc);
return time_until_gc <= 0;
}
bool ZDirector::is_first() const {
return ZStatCycle::ncycles() == 0;
}
rule 4:积极回收策略
通过ZProactive可启用积极回收策略,is_warm函数判断启用该策略必须是在预热之后(gc次数超过3次)
自上一次gc后,堆使用率达到xmx的10%或者已过了5分钟,这个参数是弥补第三个规则中没有覆盖的场景,从上述分析可以得到第三个条件更多的覆盖分配速率比较高的场景。
bool ZDirector::rule_proactive() const {
if (!ZProactive || !is_warm()) {
// Rule disabled
return false;
}
// Perform GC if the impact of doing so, in terms of application throughput
// reduction, is considered acceptable. This rule allows us to keep the heap
// size down and allow reference processing to happen even when we have a lot
// of free space on the heap.
// Only consider doing a proactive GC if the heap usage has grown by at least
// 10% of the max capacity since the previous GC, or more than 5 minutes has
// passed since the previous GC. This helps avoid superfluous GCs when running
// applications with very low allocation rate.
const size_t used_after_last_gc = ZStatHeap::used_at_relocate_end();
const size_t used_increase_threshold = ZHeap::heap()->current_max_capacity() * 0.10; // 10%
const size_t used_threshold = used_after_last_gc + used_increase_threshold;
const size_t used = ZHeap::heap()->used();
const double time_since_last_gc = ZStatCycle::time_since_last();
const double time_since_last_gc_threshold = 5 * 60; // 5 minutes
if (used < used_threshold && time_since_last_gc < time_since_last_gc_threshold) {
// Don't even consider doing a proactive GC
log_debug(gc, director)("Rule: Proactive, UsedUntilEnabled: " SIZE_FORMAT "MB, TimeUntilEnabled: %.3lfs",
(used_threshold - used) / M,
time_since_last_gc_threshold - time_since_last_gc);
return false;
}
const double assumed_throughput_drop_during_gc = 0.50; // 50%
const double acceptable_throughput_drop = 0.01; // 1%
const AbsSeq& duration_of_gc = ZStatCycle::normalized_duration();
const double max_duration_of_gc = duration_of_gc.davg() + (duration_of_gc.dsd() * one_in_1000);
const double acceptable_gc_interval = max_duration_of_gc * ((assumed_throughput_drop_during_gc / acceptable_throughput_drop) - 1.0);
const double time_until_gc = acceptable_gc_interval - time_since_last_gc;
log_debug(gc, director)("Rule: Proactive, AcceptableGCInterval: %.3lfs, TimeSinceLastGC: %.3lfs, TimeUntilGC: %.3lfs",
acceptable_gc_interval, time_since_last_gc, time_until_gc);
return time_until_gc <= 0;
}
最后,当所有策略都不满足时,返回_no_gc,表示不进行gc
