依赖注入(DI)
- 依赖注入(Dependency Injection,DI)。将对象的控制权交给 Spring 管理。
- 依赖 : 指Bean对象的创建依赖于容器 . Bean对象的依赖资源 .
- 注入 : 指Bean对象所依赖的资源 , 由容器来设置和装配 .
实现方式
依赖注入(DI,即Dependence Injection),有三种注入方式:
- 构造器注入
- setter 注入
- 接口注入
创建 Bean 对象的方式
调用构造函数创建Bean
调用构造方法创建Bean是最常用的一种情况,Spring容器通过new关键字调用构造器来创建Bean实例,通过class属性指定Bean实例的实现类,也就是说,如果使用构造器创建Bean方法,则
-
Bean实现类Person.java
package ioc.pojo; public class Person{ private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } }因为是通过构造函数创建Bean,因此我们需要提供无参数构造函数,另外我们定义了一个name属性,并提供了setter方法,Spring容器通过该方法为name属性注入参数。
-
配置文件applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 指定class属性,通过构造方法创建Bean实例 -->
<bean id="person" class="cn.demo.spring.Person">
<!-- 通过构造方法赋值 -->
<constructor-arg name="name" value="魔术师"></constructor-arg>
</bean>
</beans>
配置文件中,通过
调用静态工厂方法创建Bean
把创建Bean的任务交给了静态工厂,而不是构造函数,这个静态工厂就是一个Java类,那么使用静态工厂创建Bean咱们又需要添加哪些属性呢?我们同样需要在
class:指定静态工厂的实现类,告诉Spring该Bean实例应该由哪个静态工厂创建(指定工厂地址)
factory-method:指定由静态工厂的哪个方法创建该Bean实例(指定由工厂的哪个车间创建Bean)
如果静态工厂方法需要参数,则使用
public class StaticFactory {
public static IAccountService getAccountService() {
return new AccountServiceImpl();
}
}
配置方式如下:
<bean id = "accountService" class = "cn.demo.spring.StaticFactory" factory-method="getAccountService"></bean>
调用实例工厂方法创建Bean
使用某个类中的静态方法创建对象,并存入spring容器,如下
/**
*模拟一个工厂类,该类可能存在于jar包中,无法通过修改源码的方式来提供默认构造函数
*
*/
public class InstanceFactory {
public IAccountService getAccountService() {
return new AccountServiceImpl();
}
}
配置方式如下:
<bean id = "instanceFactory" class = "cn.demo.spring.factory.InstanceFactory"></bean>
<bean id = "accountService" factory-bean="instanceFactory" factory-method="getAccountService"></bean>
Spring工厂创建对象
Spring工厂类
public class PersonSpringFactory implements FactoryBean<Person> {
//生产bean对象的方法
@Override
public Person getObject() throws Exception {
return new Person("ww");
}
//获取bean类型的方法
@Override
public Class<?> getObjectType() {
return Person.class;
}
//告知当前bean是否采用单例模式
@Override
public boolean isSingleton() {
return true;//采用单例模式
}
}
Spring配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--Spring工厂方式创建bean-->
<bean id="person" class="cn.demo.spring.PersonSpringFactory"></bean>
</beans>
测试
/**
* 无参构造创建对象,必须有无参构造
*/
@Test
public void test(){
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Person p = (Person) context.getBean("person");
System.out.println(p);
((ClassPathXmlApplicationContext) context).close();
}
装配 bean
Spring 提供了三种主要的 Bean 的装配机制:
- 隐式的 bean 发现机制和自动装配
- 在 Java 中显示配置
- 在 XML 中显示配置
自动装配
1. Spring 实现自动化装配的两种方式
- 组件扫描(component scanning):Spring 会自动发现应用上下文中所创建的 bean 组件
- 自动装配(autowiring):Spring 自动满足 bean 之间的依赖
流程
①创建可发现的 bean
如在类上使用
@Component注解。
②为组件扫描的 bean 命名
如在
@Component("XXX")注解上增加 bean 的 ID;如在类上用
@Named("XXX")替换@Component注解。
③设置组件扫描的基础包
如在同包或父包下的主类上开启
@ComponentScan注解扫描
- 无参默认扫描本包及其子包;
@ComponentScan(basePackages = "xxx", "yyy")扫描指定多个包;@ComponentScan(basePackageClasses = "xxx.class", "yyy.class")扫描指定多个类。
④通过为 bean 添加注解实现自动装配
如
@Autowired注解修饰构造方法或 setter 方法。
Java 代码装配 bean
. 流程**
①创建配置类
如创建一个 JavaConfig 类,并为其添加
@Configuration注解
②声明简单的 bean
创建返回实例的方法,并为其添加
@Bean注解
③借助 JavaConfig 实现注入
2. 适用场景
将第三方库中的组件装配为 bean。
XML 装配 bean
流程
①创建 XML 配置规范
创建一个以
<beans>元素为根的 XML 文件
②声明一个 <bean>
③借助构造器注入初始化 bean
两种方式:一是
<constructor-arg>元素;二是使用 Spring 3.0 引入的 c-命名空间。
④设置属性
两种方式:一是使用
<property>元素;二是使用 p-命名空间。
导入和混合配置
1. bean 的导入
bean 的导入有两种方式:
- 对于 JavaConfig 装配的 bean,可通过
@Import(xxx.class)注解导入到另一个类中 - 对于 XML 装配的 bean,可通过
@ImportResource("classpath:xxx.xml")注解导入到另一个类中
2. 在 XML 中配置 JavaConfig
在一个新的 XML 文件中同时引用 XML 和 JavaConfig,用 <bean> 元素声明 JavaConfig。
使用
<import>元素只能导入其他 XML 配置文件。
高级装配
环境与 profile
配置 profile bean
在类或方法上使用 <@Profile("")> 元素。
- dev 开发环境
- prod 生产环境
- test 测试环境
如
<@Profile("dev ")>,表示只在 dev profile 激活时才会创建对应的 bean。
激活 profile
激活配置项
通过设置 spring.profiles.active 和 spring.profiles.default 这两个属性来确定激活的 profile。
- spring.profiles.active 表示激活的 profile
- spring.profiles.default 表示没有声明激活 profile 时的 profile 默认激活值
配置方式
- 作为 DispatcherServlet 的初始化参数
- 作为 Web 应用的上下文参数
- 作为 JNDI 条目
- 作为环境变量
- 作为 JVM 的系统属性
- 在集成测试类上,使用
@ActiveProfiles注解设置
条件化的 bean
配置流程
①在需要配置的条件化 bean 类或方法上使用 @Conditional 注解,给定一个入参类
如
@Conditional(xxx.class)
②此入参类需要实现 Condition 接口,并重写 mathes(ConditionContext ctx, AnnotatedTypeMetadata metadata) 方法
mathes(ConditionContext ctx, AnnotatedTypeMetadata metadata)方法返回 true 表示创建 bean;false 则表示不创建。
ConditionContext 作用
- 根据 getRegistry() 返回的 BeanDefinitionRegistry 检查 bean 定义
- 根据 getBeanFactory() 返回的 ConfigurableListableBeanFactory 检查 bean 是否存在,存在则查看 bean 的属性
- 根据 getEnvironment() 返回的 Environment 检查环境变量是否存在以及它的值是什么
- 读取并检查 getResourceLoader() 返回的 ResourceLoader 所加载的资源
- 根据 getClassLoader() 返回的 ClassLoader 加载并检查类是否存在
AnnotatedTypeMetadata 作用
检查带有 @Bean 注解的方法上还有其他的什么注解。
处理自动装配的歧义性
标识首选的 bean
@Primary 修饰 bean,表示此 bean 作为多个相同 bean 的首选。
限定自动装配的 bean
@Qualifier 修饰需要注入的 bean,表示限定为指定的唯一 bean(如 @Qualifier("xxx") )。
使用自定义的限定符注解
创建自定义的限定符注解,如命名为 @Diy
@Target({ElementType.FIELD, ElementType.METHOD, ElementType.CONSTRUCTOR, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
@Qualifier
public @interface Diy {
String value() default "";
}
Java 8 允许出现重复的注解,只要注解本身带有
@Repeatable注解即可。(但是 Spring 的@Qualifier注解并没有在定义时添加@Repeatable注解)
Bean的作用域
bean 标签的 scope 属性
作用:用于指定 bean 的作用范围
Spring 中 bean 的五种作用域:
-
单例(Singleton):单例的(default)
1)在容器启动完成之前就已经创建好对象,保存在容器中
2)任何获取都是获取之前创建好的对象
-
原型(Prototype):多例的每次注入或者通过 Spring 应用上下文获取的时候,都会创建一个新的 bean 实例
1)容器启动默认不会去创建多实例bean
2)获取时去创建这个bean
3)每次获取都会创建一个对象
-
会话(Session):Web 应用中,为每个会话创建一个 bean 实例
-
请求(Request):Web 应用中,为每个请求创建一个 bean 实例
-
全局会话(Application) : 作用于集群的会话范围(全局会话范围),当不是集群范围时,它就是 session
bean 的作用域默认为单例模式。
无状态的 bean 是线程安全的。
声明方式
使用 @Scope 声明指定所需用的作用域。
如指定原型模式:
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
Bean的生命周期

①Spring 对 bean 进行实例化;
②Spring 将值和 bean 的引用注入到 bean 对应的属性中
③如果 bean 实现了 BeanNameAware 接口,Spring 将 bean 的 ID 传递给 setBeanName() 方法
④如果 bean 实现了 BeanFactoryAware 接口,Spring 将调用 setBeanFactory() 方法,将 BeanFactory 容器实例传入
⑤如果 bean 实现了 ApplicationContextAware 接口,Spring 将调用 setApplicationContext() 方法,将 bean 所在的应用上下文引用传进来
⑥如果 bean 实现了 BeanPostProcessor 接口,Spring 将调用它们的 postProcessBeforeInitialization() 方法
⑦如果 bean 实现了 InitializingBean 接口,Spring 将调用它们的 afterPropertiesSet() 方法;同样,如果 bean 使用了 init-method 方法初始化方法,该方法也会被调用
⑧如果 bean 实现了 BeanPostProcessor 接口,Spring 将调用它们的 postProcessAfterInitialization() 方法
⑨此时 bean 可被使用,并一直驻留在应用上下文中,直到改应用上下文被销毁
⑩如果 bean 实现了 DisposableBean 接口,Spring 将调用它的destroy() 接口方法;同样,若 bean 使用 destroy-method 声明了销毁方法,该方法也会被调用
单例对象:
- 出生:当容器创建时发生
- 活着:只要容器还在对象就一直活着
- 死亡:容器销毁,对象消亡
(容器启动)构造器 ——-> 初始化方法 ——-> (容器关闭)销毁方法
总结:单例对象的声明周期和容器相同
多例对象:
- 出生:当我们使用对象时 Spring 框架为我们创建
- 活着:对象只要是在使用过程中就活着
- 死亡:当对象长时间不用,且没有别的对象引用时,由 Java 的GC回收
获取bean(构造器 ——> 初始化方法) ———> 容器关闭不会关闭销毁方法
后置处理器:
(容器启动)构造器 ——-> 后置处理器before…. ———->初始化方法 ————>后置处理器after…. ———>bean初始化完成
无论bean是否有初始化方法,后置处理器都会默认其有,还会继续工作。
运行时值注入
Spring 提供了两种运行时求值的方式:
- 属性占位符(Property placeholder)
- Spring 表达式语言(SpEL)
使用属性占位符
使用注解@PropertySource
使用 @PropertySource 注解对指定 bean 注入外部的值,然后通过 Spring 的 Environment 对象来获取指定属性值。
Environment
Spring 的 Environment 对象获取属性值的四种方法:
String getProperty(String key)根据属性返回对应属性值String getProperty(String key, String defaultValue)根据属性返回对应属性值,若属性不存在则返回设置的默认值T getProperty(String key, Class<T> type)根据属性返回对应属性对象T getProperty(String key, Class<T> type, T defaultValue)据属性返回对应属性对象,若属性不存在则返回设置的默认对象
Spring 的 Environment 对象检查 profile 是否激活的三种方法:
String[] getActiveProfiles()返回激活 profile 名称的数组String[] getDefaultProfiles()返回默认 profile 名称的数组boolean accepetsProfiles()如果 Environment 支持给定 profile,则返回 true
解析属性占位符
Spring 装配中,占位符使用 ${...} 包装属性名称。
若通过组件扫描和自动装配来创建和初始化应用时,使用 @Value 注解来配置属性。
使用属性占位符前,需要配置一个 PropertyPlaceHolderConfigurer 的 bean 或 PropertySourcesPlaceHolderConfigurer 的 bean(推荐用这个,因为它能够基于 Spring 的 Environment 及其属性来源解析占位符)。
使用 SpEL
特性
SpEL的特性:
- 使用 bean 的 ID 来引用 bean
- 调用方法和访问对象的属性
- 对值进行算术、关系和逻辑运算
- 正则表达式匹配
- 集合操作
样例
- #{T(System).currentTimeMillis()} 表示当前时间毫秒数
- #{xxx.yyy} 表示 ID 为 xxx 的 bean 的 yyy 属性
- #{systemProperties{ ‘xxx.yyy’ }} 表示通过 systemProperties 对象引用系统属性
作用
- 表示字面值(如 #{3.14) 表示浮点值)
- 引用 bean 、属性和方法(如 #{xxx.yyy})
- 在表达式中使用类型运算符 T() 调用指定类的方法(如 #{T(System).currentTimeMillis()} )
SpEL 运算符
| 运算符类型 | 运算符 |
|---|---|
| 算术运算符 | +、-、*、/、%、^ |
| 比较运算符 | <、>、==、<=、>=、lt、gt、eq、le、ge |
| 逻辑运算符 | and、or、not、| |
| 条件运算符 | ?: (ternary)、?: (Elvis) |
| 正则表达式 | mathes |
使用注解开发
AOP(面向切面编程)
什么是AOP
AOP(Aspect Oriented Programming),即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。
面向切面是面向对象中的一种方式而已。在代码执行过程中,动态嵌入其他代码,叫做面向切面编程。常见的使用场景:日志,事务,数据库操作
面向切面编程的几个核心概念
| 概念 | 说明 |
|---|---|
| 切面(aspect) | 切面泛指交叉业务逻辑。比如事务处理、日志处理就可以理解为切面。切入点和通知的结合。切入点指的是被增强过的方法,通知指的是提供了公共代码的方法。建立切入点方法和通知方法在执行调用的对应关系指的是切面。 |
| 织入(waving) | 实际就是对主业务逻辑的一种增强织入是指将切面代码插入到目标对象的过程。原有的service无法实现事务的支持,于是我们用动态代理技术创建了一个新的对象,返回了一个代理对象。在返回代理对象时,从中加入了事务支持。加入支持的过程称为织入。 |
| 连接点(joinpoint) | 连接点指切面可以织入的位置。被拦截到的点,这些点指的是方法,spring只支持方法类型的连接点。在业务层接口中,其中所有的方法都是连接点,连接业务和增强方法。帮助我们将增强事务控制的代码加到业务当中来,使得方法加上事务支持从而形成完整的业务逻辑。 |
| 切入点(pointcut) | 切入点指切面具体织入的位置。被增强的方法。切入点是连接点的子集。 |
| 通知/增强(advice) | 通知是切面的一种实现,可以完成简单织入功能(织入功能就是在这里完成的)。通知定义了增强代码切入到目标代码的时间点,是目标方法执行之前执行,还是之后执行等。通知类型不同,切入时间不同。拦截到连接点后要做的事情。动态代理中invoke方法具有拦截的功能,能拦截被代理对象中所执行的所有方法。拦截后要做的就是提供事务的支持,包括开启事务、执行操作、提交事务、返回结果。 |
| 顾问(Advisor) | 顾问是切面的另一种实现,能够将通知以更为复杂的方式织入到目标对象中,是将通知包装为更复杂切面的装配器。 不仅指定了切入时间点,还可以指定具体的切入点 |
| 引介(Introduction) | 明代表的类型的额外的方法或字段。 Spring允许引入新的接口(以及一个对应的实现)到任何被代理的对象。例如,你可以使用引入来使一个bean实现IsModified接口,以便简化缓存。 |
| 目标对象(target) | 代理的目标对象。 |
| 代理(proxy) | 织入后产生的对象。 |
AOP的实现方式
| 通知类型 | 说明 |
|---|---|
| 前置通知(MethodBeforeAdvice) | 目标方法执行之前调用 |
| 后置通知(AfterReturningAdvice) | 目标方法执行完成之后调用 |
| 环绕通知(MethodInterceptor) | 目标方法执行前后都会调用方法,且能增强结果 |
| 异常处理通知(ThrowsAdvice) | 目标方法出现异常调用 |
整个 aspect 就可以描述为: 满足 pointcut 规则的 joinpoint 会被添加相应的 advice 操作.
AOP 的术语
Joinpoint(连接点):所谓连接点是指那些被拦截到的点。 在 spring 中,这些点指的是方法,因为 spring 只支持方法类型的连接点.( 即那些方法可以被拦截)Pointcut(切入点):所谓切入点是指我们要对哪些 Joinpoint 进行拦截的定义.( 实际拦截的方法)Advice(通知/增强):所谓通知是指拦截到Joinpoint之后所要做的事情就是通知.通知分为前置通知,后置通知,异常通知,最终通知,环绕通知(切面要完成的功能)Introduction(引介):引介是一种特殊的通知在不修改类代码的前提下, Introduction 可以在运行期为类动态地添加一些方法或 Field.Target(目标对象):即代理的目标对象Weaving(织入):是指把增强应用到目标对象来创建新的代理对象的过程.spring 采用动态代理织入, 而 AspectJ 采用编译期织入和类装载期织入Proxy(代理):一个类被 AOP 织入增强后, 就产生一个结果代理类Aspect(切面):是切入点和通知(引介)的结合

AOP核心概念
AOP,面向切面编程,它有三个核心概念:
- 通知(advice)
- 切点(pointcut)
- 连接点(joinpoint)
在一个或多个连接点上,可以把切面的功能(通知)织入到程序的执行过程中。
通知 Advice
1. 概念
通知(Advice)定义了切面何时使用,包含需要用于多个应用对象的横切行为。
分类
通知 Advice 分为五个类型(对应的 AspectJ 注解):
- 前置通知(@Before):在目标方法被调用之前调用通知功能
- 后置通知(@After):在目标方法完成之后或抛出异常后调用通知,此时不会关心方法的输出是什么
- 返回通知(@AfterReturning):在目标方法成功执行之后调用通知
- 异常通知(@AfterThrowing):在目标方法抛出异常后调用通知
- 环绕通知(@Around):通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的行为
连接点 Join point
连接点是在应用执行过程中能够插入切面(应用通知)的所有点。
连接点可以是调用方法时、抛出异常时、修改字段时等等。
切点 Pointcut
概念
切点定义了通知被应用的具体位置(连接点)。
使用方式
在需要声明为切点的方法上开启 @Pointcut 注解即可。
切面 Aspect
概念
切面是通知和切点的结合。
使用方式
①在需要声明为切面的类上开启 @Aspect 注解;
②在声明切面类为 bean 的配置类上开启 @EnableAspectJAutoProxy 注解,启用自动代理功能。
引入 Introduction
引入允许向现有的类添加新方法或属性。
织入 Weaving
概念
织入是把切面应用到目标对象并创建新的代理对象的过程。
织入点
- 编译期:切面在目标类编译时被织入。(如 AspectJ)
- 类加载期:切面在目标类加载到 JVM 时被织入(如 ClassLoader、ApspectJ 5 的加载时织入)
- 运行期:切面在应用运行的某个时刻被织入(如 AOP)
AOP 支持
Sping 提供了4种类型的 AOP 支持:
- 基于代理的经典 Spring AOP
- 纯 POJO 切面
@AspectJ注解驱动的切面- 注入式 AspectJ 切面(适用于 Spring 各版本)
Spring 通知的 AOP 实现
Spring 运行时通知对象流程
①Spring 在运行期把切面织入到 Spring 管理的 bean 中;
②因为目标类被代理类封装,调用目标 bean 方法前,会执行切面逻辑。
Spring 代理对象是懒加载模式,用到才会加载。
如果使用 ApplicationContext 时,在 ApplicationContext 从 BeanFactory 中加载 所有 bean 时,Spring 才会创建被代理的对象。
适用场景
Spring 只支持方法级别的连接点,因为 Spring 基于动态代理。
AspectJ 和 JBoss 支持字段和构造器级别的连接点。
AOP 对 AspectJ 的支持
Spring AOP 对 AspectJ 支持的切点指示器如下表。
| AspectJ 指示器 | 描述 |
|---|---|
| arg() | 限制连接点匹配参数为指定类型的执行方法 |
| @args() | 限制连接点匹配参数由指定注解标注的执行方法 |
| execution() | 用于匹配是连接点的执行方法 |
| this() | 限制连接点匹配 AOP 代理的 bean 引用为指定类型的类 |
| target | 限制连接点匹配目标对象为指定类型的类 |
| @target() | 限制连接点匹配特定的执行对象,这些对象对应的类要具有指定类型的注解 |
| within() | 限制连接点匹配指定的类型 |
| @within() | 限制连接点匹配指定注解所标注的类型(当使用 Spring AOP 时,方法定义在由指定注解所标注的类里) |
| @annotation | 限定匹配带有指定注解的连接点 |
- 只有 execution 指示器是实际执行匹配的
- 其他指示器都是限制匹配的
AOP 为对象增加方法
AOP 不仅可以对方法增加新的功能,还能对一个对象增加新的方法。
使用方式
通过 @DeclareParents 注解修饰需要新增方法的 bean。
注解由三部分组成:
- value:指定哪种类型的 bean 引入该接口
- defaultImpl:指定了为引入功能提供实现的类
- @DeclareParents:标注的静态属性知名了要引入的接口
局限性
只能为有源码的通知类添加注解。
无源码的解决方案
在 XML 中声明切面,XML 中的 AOP 配置元素如下表。
| AOP 配置元素 | 用途 |
|---|---|
| <aop:advisor> | 定义 AOP 通知器 |
| <aop:after> | 定义 AOP 后置通知(不管被通知的方法是否执行成功) |
| <aop:after-returning> | 定义 AOP 返回通知 |
| <aop:after-throwing> | 定义 AOP 异常通知 |
| <aop:around> | 定义 AOP 环绕通知 |
| <aop:aspect> | 定义一个切面 |
| <aop:aspectj-autoproxy> | 启用 @AspectJ 注解驱动的切面 |
| <aop:before> | 定义一个 AOP 前置通知 |
| <aop:config> | 顶层的 AOP 配置元素,大多数 <aop:*>元素必须包含在<aop:config>元素内 |
| <aop:declare-parents> | 以透明的方式为被通知的对象引入额外的接口 |
| <aop:pointcut> | 定义一个切点 |
AOP的底层实现
JDK动态代理
创建接口
- UserDao
public interface UserDao {
public void add();
public void update();
}
- UserDaoImpl
public class UserDaoImpl implements UserDao {
@Override
public void add() {
System.out.println("添加用户");
}
@Override
public void update() {
System.out.println("更新用户");
}
}
创建生成代理的类
- JavaJDKProxy
public class JavaJDKProxy {
private UserDao userDao;
public JavaJDKProxy(UserDao userDao){
super();
this.userDao=userDao;
}
/**
* 创建userDao的代理类
* 工厂模式
* @return
*/
public UserDao createProxy(){
UserDao userDaoProxy =(UserDao) Proxy.newProxyInstance(userDao.getClass().getClassLoader(), userDao.getClass().getInterfaces(), new InvocationHandler() {
/**
* InvocationHandler 生成方式:
* 1.匿名内部类的形式
* 2.直接让当前类谁实现 InvocationHandler 接口, 然后创建代理的 InvocationHandler 写 this
* 3.重写写一个类实现 InvocationHandler 接口, 在本类中通过的 new 的方式创建
* @param proxy
* @param method
* @param args
* @return
* @throws Throwable
*/
//代用目标对象的任何一个方法都相当于代用 invoke
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//如果执行的 add 方法, 那么就记录日志
if ("add".equals(method.getName())){
// 记录日志
System.out.println("------记录日志-----");
//然后执行 add 方法
/**
* method.invoke(obj,args): 对带有指定参数的指定对象调用由此 Method
* 对象表示的底层方法。
* 参数一: obj - 从中调用底层方法的对象
* 参数二: args 用于方法调用的参数
* 返回值: result:使用参数 args 在 obj 上指派该对象所表示方法的结果
*/
Object result = method.invoke(userDao,args);
return result;
}
return method.invoke(userDao,args);
}
});
return userDaoProxy;
}
}
- UserDaoTest
public class UserDaoTest {
@Test
public void testUserDao(){
// 生成目标对象
UserDao userDao = new UserDaoImpl();
// 创建代理对象
UserDao proxy = new JavaJDKProxy(userDao).createProxy();
//proxy.add();
proxy.update();
}
}
CGLIB 动态代理
CGLIB(Code Generation Library)是一个开源项目! 是一个强大的, 高性能, 高质量的 Code 生成类库, 它可以 在运行期扩展 Java 类与实现 Java 接口。 Hibernate 支持它来实现 PO(Persistent Object 持久化对象)字节码的 动态生成 Hibernate 生成持久化类的 javassist. CGLIB 生成代理机制:其实生成了一个真实对象的子类.( 只能对类生成代理) 下载 cglib 的 jar 包.
- 现在做 cglib 的开发,可以不用直接引入 cglib 的包.已经在 spring 的核心中集成 cglib.
创建类
- ProductDao
public class ProductDao {
public void add(){
System.out.println("增加商品");
}
public void update(){
System.out.println("更新商品");
}
}
- CglibProxy
public class CglibProxy implements MethodInterceptor{
private ProductDao productDao;
public CglibProxy(ProductDao productDao) {
this.productDao = productDao;
}
public ProductDao createProxy(){
//1.使用CGLIB生成代理
Enhancer enhancer = new Enhancer();
//2.为其设置父类(因为采用继承机制,所以的指定父类)
enhancer.setSuperclass(productDao.getClass());
//3.设置回调:和javaProxyInvoke相似
enhancer.setCallback(this);
//4.创建代理
return (ProductDao) enhancer.create();
}
/**
*
* @param o CGLIB根据指定父类生成的代理对象(是ProductDao的子类)
* @param method 拦截的方法
* @param objects 拦截方法的参数数组
* @param methodProxy 方法的代理对象,用于执行父类的方法
* @return
* @throws Throwable
*/
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
if ("add".equals(method.getName())){
//在执行 add 方法前执行记录日志
System.out.println("----记录日志----");
// 执行add方法
Object result = methodProxy.invokeSuper(o,objects);
// 执行add方法后的返回值
return result;
}
// 执行的其他方法
return methodProxy.invokeSuper(o,objects);
}
}
- ProductDaoTest
public class ProductDaoTest {
@Test
public void testProductDao(){
// 目标对象
ProductDao productDao = new ProductDao();
// 生成代理对象
ProductDao proxy = new CglibProxy(productDao).createProxy();
proxy.add();
proxy.update();
}
}
spring 代理知识总结
Spring 框架,如果类实现了接口,就使用 JDK 的动态代理生成代理对象,如果这个类没有实现任何接口,使用CGLIB 生成代理对象.( 底层会自动切换)
Spring 在运行期, 生成动态代理对象, 不需要特殊的编译器 Spring AOP 的底层就是通过 JDK 动态代理或 CGLib 动态代理技术 为目标Bean 执行横向织入
- 若目标对象实现了若干接口, spring 使用 JDK 的
java.lang.reflect.Proxy类代理。 -
若目标对象没有实现任何接口, spring 使用 CGLIB 库生成目标对象的子类。
- 程序中应优先对接口创建代理, 便于程序解耦维护
- 标记为 final 的方法, 不能被代理, 因为无法进行覆盖
- JDK 动态代理, 是针对接口生成子类, 接口中方法不能使用 final 修饰
- CGLib 是针对目标类生产子类, 因此类或方法 不能使 final 的
- Spring 只支持方法连接点, 不提供属性连接
Spring的事务管理
事务的介绍
数据库事务特性
- 原子性 多个数据库操作是不可分割的,只有所有的操作都执行成功,事务才能被提交;只要有一个操作执行失败,那么所有的操作都要回滚,数据库状态必须回复到操作之前的状态
- 一致性 事务操作成功后,数据库的状态和业务规则必须一致。例如:从A账户转账100元到B账户,无论数据库操作成功失败,A和B两个账户的存款总额是不变的。
- 隔离性 当并发操作时,不同的数据库事务之间不会相互干扰(当然这个事务隔离级别也是有关系的)
- 持久性 事务提交成功之后,事务中的所有数据都必须持久化到数据库中。即使事务提交之后数据库立刻崩溃,也需要保证数据能能够被恢复。
事物隔离级别
当数据库并发操作时,可能会引起脏读、不可重复读、幻读等现象。
- 脏读 事务A读取事务B尚未提交的更改数据,并做了修改;此时如果事务B回滚,那么事务A读取到的数据是无效的,此时就发生了脏读。
- 不可重复读 一个事务执行相同的查询两次或两次以上,每次都得到不同的数据。如:A事务下查询账户余额,此时恰巧B事务给账户里转账100元,A事务再次查询账户余额,那么A事务的两次查询结果是不一致的。
- 幻读 A事务读取B事务提交的新增数据,此时A事务将出现幻读现象。幻读与不可重复读容易混淆,如何区分呢?幻读是读取到了其他事务提交的新数据,不可重复读是读取到了已经提交事务的更改数据(修改或删除)
对于以上问题,可以有多个解决方案,设置数据库事务隔离级别就是其中的一种,数据库事务隔离级别分为四个等级,通过一个表格描述其作用。
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 |
|---|---|---|---|
| READ UNCOMMITTED | 允许 | 允许 | 允许 |
| READ COMMITTED | 脏读 | 允许 | 允许 |
| REPEATABLE READ | 不允许 | 不允许 | 允许 |
| SERIALIZABLE | 不允许 | 不允许 | 不允许 |
Spring事务支持核心接口
Spring事务管理高层抽象主要包括3个接口,Spring的事务主要是由他们共同完成的:
- TransactionDefinition:事务定义信息(隔离、传播、超时、只读)—通过配置如何进行事务管理。
- PlatformTransactionManager:事务管理器—主要用于平台相关事务的管理
- TransactionStatus:事务具体运行状态—事务管理过程中,每个时间点事务的状态信息。

TransactionDefinition(事务定义信息)
定义与spring兼容的事务属性的接口
public interface TransactionDefinition {
// 如果当前没有事物,则新建一个事物;如果已经存在一个事物,则加入到这个事物中。
int PROPAGATION_REQUIRED = 0;
// 支持当前事物,如果当前没有事物,则以非事物方式执行。
int PROPAGATION_SUPPORTS = 1;
// 使用当前事物,如果当前没有事物,则抛出异常。
int PROPAGATION_MANDATORY = 2;
// 新建事物,如果当前已经存在事物,则挂起当前事物。
int PROPAGATION_REQUIRES_NEW = 3;
// 以非事物方式执行,如果当前存在事物,则挂起当前事物。
int PROPAGATION_NOT_SUPPORTED = 4;
// 以非事物方式执行,如果当前存在事物,则抛出异常。
int PROPAGATION_NEVER = 5;
// 如果当前存在事物,则在嵌套事物内执行;如果当前没有事物,则与PROPAGATION_REQUIRED传播特性相同
int PROPAGATION_NESTED = 6;
// 使用后端数据库默认的隔离级别。
int ISOLATION_DEFAULT = -1;
// READ_UNCOMMITTED 隔离级别
int ISOLATION_READ_UNCOMMITTED = Connection.TRANSACTION_READ_UNCOMMITTED;
// READ_COMMITTED 隔离级别
int ISOLATION_READ_COMMITTED = Connection.TRANSACTION_READ_COMMITTED;
// REPEATABLE_READ 隔离级别
int ISOLATION_REPEATABLE_READ = Connection.TRANSACTION_REPEATABLE_READ;
// SERIALIZABLE 隔离级别
int ISOLATION_SERIALIZABLE = Connection.TRANSACTION_SERIALIZABLE;
// 默认超时时间
int TIMEOUT_DEFAULT = -1;
// 获取事物传播特性
int getPropagationBehavior();
// 获取事物隔离级别
int getIsolationLevel();
// 获取事物超时时间
int getTimeout();
// 判断事物是否可读
boolean isReadOnly();
// 获取事物名称
@Nullable
String getName();
}
该接口主要提供的方法:
-
getIsolationLevel:隔离级别获取
-
getPropagationBehavior:传播行为获取
-
getTimeout:获取超时时间
-
isReadOnly 是否只读(保存、更新、删除—对数据进行操作-变成可读写的,查询-设置这个属性为true,只能读不能写)
-
withDefaults()
Return an unmodifiable TransactionDefinition with defaults. For customization purposes, use the modifiable DefaultTransactionDefinition instead. Since: 5.2这些事务的定义信息,都可以在配置文件中配置和定制。
Spring事物传播特性
| 传播特性名称 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事物,则新建一个事物;如果已经存在一个事物,则加入到这个事物中 |
| PROPAGATION_SUPPORTS | 支持当前事物,如果当前没有事物,则以非事物方式执行 |
| PROPAGATION_MANDATORY | 使用当前事物,如果当前没有事物,则抛出异常 |
| PROPAGATION_REQUIRES_NEW | 新建事物,如果当前已经存在事物,则挂起当前事物 |
| PROPAGATION_NOT_SUPPORTED | 以非事物方式执行,如果当前存在事物,则挂起当前事物 |
| PROPAGATION_NEVER | 以非事物方式执行,如果当前存在事物,则抛出异常 |
| PROPAGATION_NESTED | 如果当前存在事物,则在嵌套事物内执行;如果当前没有事物,则与PROPAGATION_REQUIRED传播特性相同 |
Spring事物隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
mysql默认的事务隔离级别为 可重复读repeatable-read
Oracle 默认隔离级别 READ_COMMITTED
PlatformTransactionManager(事务管理器)
Spring事务基础结构中的中心接口
public interface PlatformTransactionManager {
// 根据指定的传播行为,返回当前活动的事务或创建新事务。
TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException;
// 就给定事务的状态提交给定事务。
void commit(TransactionStatus status) throws TransactionException;
// 执行给定事务的回滚。
void rollback(TransactionStatus status) throws TransactionException;
}
该接口提供三个方法:
- commit:提交事务
- rollback:回滚事务
- getTransaction:获取事务状态
Spring将事物管理委托给底层的持久化框架来完成,因此,Spring为不同的持久化框架提供了不同的PlatformTransactionManager接口实现。列举几个Spring自带的事物管理器:
| 事物管理器 | 说明 |
|---|---|
| org.springframework.jdbc.datasource.DataSourceTransactionManager | 提供对单个javax.sql.DataSource事务管理,用于Spring JDBC抽象框架、iBATIS或MyBatis框架的事务管理 |
| org.springframework.orm.jpa.JpaTransactionManager | 提供对单个javax.persistence.EntityManagerFactory事务支持,用于集成JPA实现框架时的事务管理 |
| org.springframework.transaction.jta.JtaTransactionManager | 提供对分布式事务管理的支持,并将事务管理委托给Java EE应用服务器事务管理器 |
- DataSourceTransactionManager针对JdbcTemplate、MyBatis 事务控制 ,使用Connection(连接)进行事务控制 : 开启事务 connection.setAutoCommit(false); 提交事务 connection.commit(); 回滚事务 connection.rollback();
- HibernateTransactionManage针对Hibernate框架进行事务管理, 使用Session的Transaction相关操作进行事务控制 : 开启事务 session.beginTransaction(); 提交事务 session.getTransaction().commit(); 回滚事务 session.getTransaction().rollback();
事务管理器的选择? 用户根据选择和使用的持久层技术,来选择对应的事务管理器。
TransactionStatus(事务状态)
- 事物状态描述
- TransactionStatus接口
public interface TransactionStatus extends SavepointManager, Flushable {
// 返回当前事务是否为新事务(否则将参与到现有事务中,或者可能一开始就不在实际事务中运行)
boolean isNewTransaction();
// 返回该事务是否在内部携带保存点,也就是说,已经创建为基于保存点的嵌套事务。
boolean hasSavepoint();
// 设置事务仅回滚。
void setRollbackOnly();
// 返回事务是否已标记为仅回滚
boolean isRollbackOnly();
// 将会话刷新到数据存储区
@Override
void flush();
// 返回事物是否已经完成,无论提交或者回滚。
boolean isCompleted();
}
SavepointManager接口
public interface SavepointManager {
// 创建一个新的保存点。
Object createSavepoint() throws TransactionException;
// 回滚到给定的保存点。
// 注意:调用此方法回滚到给定的保存点之后,不会自动释放保存点,
// 可以通过调用releaseSavepoint方法释放保存点。
void rollbackToSavepoint(Object savepoint) throws TransactionException;
// 显式释放给定的保存点。(大多数事务管理器将在事务完成时自动释放保存点)
void releaseSavepoint(Object savepoint) throws TransactionException;
}
用户管理事务,需要先配置事务管理方案TransactionDefinition、 管理事务通过TransactionManager完成,TransactionManager根据 TransactionDefinition进行事务管理,在事务运行过程中,每个时间点都可以通过获取TransactionStatus了解事务运行状态!
Spring事务管理两种方式
-
编程式的事务管理 通过TransactionTemplate手动管理事务 在实际应用中很少使用,原因是要修改原来的代码,加入事务管理代码(侵入性 )
-
使用XML配置声明式事务 Spring的声明式事务是通过AOP实现的(环绕通知) 开发中经常使用(代码侵入性最小)–推荐使用!
Spring编程式事务
- 数据库表结构
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`balance` int(11) DEFAULT NULL COMMENT '账户余额',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='--账户表'
- 实现
import org.apache.commons.dbcp.BasicDataSource;
import org.springframework.dao.DataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
import javax.sql.DataSource;
/**
* Spring编程式事务
*/
public class MyTransaction {
private JdbcTemplate jdbcTemplate;
private DataSourceTransactionManager txManager;
private DefaultTransactionDefinition txDefinition;
private String insert_sql = "insert into account (balance) values ('100')";
public void save() {
// 1、初始化jdbcTemplate
DataSource dataSource = getDataSource();
jdbcTemplate = new JdbcTemplate(dataSource);
// 2、创建物管理器
txManager = new DataSourceTransactionManager();
txManager.setDataSource(dataSource);
// 3、定义事物属性
txDefinition = new DefaultTransactionDefinition();
txDefinition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
// 3、开启事物
TransactionStatus txStatus = txManager.getTransaction(txDefinition);
// 4、执行业务逻辑
try {
jdbcTemplate.execute(insert_sql);
//int i = 1/0;
jdbcTemplate.execute(insert_sql);
txManager.commit(txStatus);
} catch (DataAccessException e) {
txManager.rollback(txStatus);
e.printStackTrace();
}
}
public DataSource getDataSource() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/my_test?useSSL=false&useUnicode=true&characterEncoding=UTF-8");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
}
- 测试类及结果
public class MyTest {
@Test
public void test1() {
MyTransaction myTransaction = new MyTransaction();
myTransaction.save();
}
}
运行测试类,在抛出异常之后手动回滚事物,所以数据库表中不会增加记录。
基于@Transactional注解的声明式事物
其底层建立在 AOP 的基础之上,对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。通过声明式事物,无需在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过等价的基于标注的方式),便可以将事务规则应用到业务逻辑中。
- 接口
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
/**
* 账户接口
*/
@Transactional(propagation = Propagation.REQUIRED)
public interface AccountServiceImp {
void save() throws RuntimeException;
}
- 实现
import org.springframework.jdbc.core.JdbcTemplate;
/**
* 账户接口实现
*/
public class AccountServiceImpl implements AccountServiceImp {
private JdbcTemplate jdbcTemplate;
private static String insert_sql = "insert into account(balance) values (100)";
@Override
public void save() throws RuntimeException {
System.out.println("==开始执行sql");
jdbcTemplate.update(insert_sql);
System.out.println("==结束执行sql");
System.out.println("==准备抛出异常");
throw new RuntimeException("==手动抛出一个异常");
}
public void setJdbcTemplate(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
}
- 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
<!--开启tx注解-->
<tx:annotation-driven transaction-manager="transactionManager"/>
<!--事物管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--数据源-->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/my_test?useSSL=false&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</bean>
<!--jdbcTemplate-->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--业务bean-->
<bean id="accountService" class="com.demo.aop.AccountServiceImpl">
<property name="jdbcTemplate" ref="jdbcTemplate"/>
</bean>
</beans>
- 测试
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
** 基于tx标签的声明式事务
*/
public class MyTest {
@Test
public void test1() {
// 基于tx标签的声明式事务
ApplicationContext ctx = new ClassPathXmlApplicationContext("aop.xml");
AccountServiceImp studentService = ctx.getBean("accountService", AccountServiceImp.class);
studentService.save();
}
}
- 测试
==开始执行sql
==结束执行sql
==准备抛出异常
java.lang.RuntimeException: ==手动抛出一个异常
at com.demo.spring.AccountServiceImpl.save(AccountServiceImpl.java:24)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
测试方法中手动抛出了一个异常,Spring会自动回滚事物,查看数据库可以看到并没有新增记录。
注意:默认情况下Spring中的事务处理只对RuntimeException方法进行回滚,所以,如果此处将RuntimeException替换成普通的Exception不会产生回滚效果。
SpringMVC
什么是MVC
-
MVC是模型(Model)、视图(View)、控制器(Controller)的简写,是一种软件设计规范。
-
是将业务逻辑、数据、显示分离的方法来组织代码。
-
MVC主要作用是降低了视图与业务逻辑间的双向偶合。
-
MVC不是一种设计模式,MVC是一种架构模式。当然不同的MVC存在差异。
Model(模型):数据模型,提供要展示的数据,因此包含数据和行为,可以认为是领域模型或
JavaBean组件(包含数据和行为),不过现在一般都分离开来:Value Object(数据Dao) 和 服务层
(行为Service)。也就是模型提供了模型数据查询和模型数据的状态更新等功能,包括数据和业务。
View(视图):负责进行模型的展示,一般就是我们见到的用户界面,客户想看到的东西。
Controller(控制器):接收用户请求,委托给模型进行处理(状态改变),处理完毕后把返回的模型
数据返回给视图,由视图负责展示。 也就是说控制器做了个调度员的工作。
最典型的MVC就是SP + servlet + javabean的模式。
MVC框架要做哪些事情
- 将url映射到java类或java类的方法 .
- 封装用户提交的数据 .
- 处理请求–调用相关的业务处理–封装响应数据 .
- 将响应的数据进行渲染 . jsp / html 等表示层数据 .
说明:
常见的服务器端MVC框架有:Struts、Spring MVC、ASP.NET MVC、Zend Framework、JSF;常见前端MVC框架:vue、angularjs、react、backbone;由MVC演化出了另外一些模式如:MVP、MVVM 等等
SpringMVC概述
Spring MVC是Spring Framework的一部分,是基于Java实现MVC的轻量级Web框架。
查看官方文档:https://docs.spring.io/spring/docs/5.2.0.RELEASE/spring-framework-reference/web.html#spring-web
我们为什么要学习SpringMVC呢?
Spring MVC的特点:
- 轻量级,简单易学
- 高效 , 基于请求响应的MVC框架
- 与Spring兼容性好,无缝结合
- 约定优于配置
- 功能强大:RESTful、数据验证、格式化、本地化、主题等
- 简洁灵活
Spring的web框架围绕DispatcherServlet [ 调度Servlet ] 设计。
DispatcherServlet的作用是将请求分发到不同的处理器。从Spring 2.5开始,使用Java 5或者以上版本的用户可以采用基于注解形式进行开发,十分简洁;
正因为SpringMVC好 , 简单 , 便捷 , 易学 , 天生和Spring无缝集成(使用SpringIoC和Aop) , 使用约定优于配置 . 能够进行简单的junit测试 . 支持Restful风格 .异常处理 , 本地化 , 国际化 , 数据验证 , 类型转换 , 拦截器 等等……所以我们要学习
SpringMVC的原理:
当发起请求时被前置的控制器拦截到请求,根据请求参数生成代理请求,找到请求对应的实际控制器,控制器处理请求,创建数据模型,访问数据库,将模型响应给中心控制器,控制器使用模型与视图渲染视图结果,将结果返回给中心控制器,再将结果返回给请求者。
SpringMVC组件
- 中心控制器(DispatcherServlet):负责将请求路由到其他组件中;
- 处理器映射(Handler mapping):根据请求路由寻找对应的处理器;
- 控制器(Controller):执行业务逻辑,并返回结果;
- 视图解析器(View resolver):将逻辑视图名匹配对应的视图实现;
- 模型(model):控制器完成处理逻辑后返回给用户并在浏览器展示的的信息;
- 视图(view):友好的界面展示代码,通常是 HTML、JSP 等。
SpringMVC流程

①DispatcherServlet表示前置控制器,是整个SpringMVC的控制中心。用户发出请求,DispatcherServlet接收请求并拦截请求。
我们假设请求的url为 : http://localhost:8080/SpringMVC/hello
如上url拆分成三部分:
http://localhost:8080服务器域名
SpringMVC部署在服务器上的web站点
hello表示控制器
通过分析,如上url表示为:请求位于服务器localhost:8080上的SpringMVC站点的hello控制器。
②HandlerMapping为处理器映射。DispatcherServlet调用HandlerMapping,HandlerMapping根据请求url查找Handler。
③HandlerExecution表示具体的Handler,其主要作用是根据url查找控制器,如上url被查找控制器为:hello。
④HandlerExecution将解析后的信息传递给DispatcherServlet,如解析控制器映射等。
⑤HandlerAdapter表示处理器适配器,其按照特定的规则去执行Handler。
⑥Handler让具体的Controller执行。
⑦Controller将具体的执行信息返回给HandlerAdapter,如ModelAndView。处理器处理完业务后,会返回一个 ModelAndView 对象,Model 是返回的数据对象,View 是个逻辑上的 View。
⑧HandlerAdapter将视图逻辑名或模型传递给DispatcherServlet。
⑨DispatcherServlet调用视图解析器(ViewResolver)来解析HandlerAdapter传递的逻辑视图名。
⑩视图解析器将解析的逻辑视图名传给DispatcherServlet。
①DispatcherServlet根据视图解析器解析的视图结果,调用具体的视图。
②最终视图呈现给用户。
SpringMVC之HelloWorld
Spring整合Junit
-
导入 Spring 整合 Junit 的 jar ( 坐标 )
-
使用 Junit 提供的一个注解把原有的 main 方法替换了,替换成 Spring 提供的@Runwith
-
告知 Spring 的运行器, Spring 和 ioc 创建是基于 xml 还是注解的,并且说明位置,用到的注解如下
@ContextConfiguration
Locations : 指定 xml 文件的位置,加上 classpath 关键字,表示在类路径下
classes : 指定注解类所在地位置
-
使用@Autowired 给测试类中的变量注入数据
测试类
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class AccountTest {
@Autowired
private Account account;
@Test
public void testAccount(){
System.out.println(account);
}
}
Spring源码
怎么阅读Spring源码
阅读好项目源代码,有几个前提条件要做好:
1)知道该项目的用途,是干什么的
2)了解该项目的架构,包含什么模块,各模块是干什么的
3)先懂原理,后有针对性的看代码
回归正题:怎么阅读Spring源码?
建议还是多看看底层的知识。
1)Spring Framework 是一个开源框架,能帮助企业快速搭建一栈式(Full Stack)企业级项目应用框架。
2)Spring Framework 项目架构图:
Spring框架包含了非常多的功能,不能漫无目的,一股脑地阅读,这样很容易头晕。了解完Spring架构、模块以及模块对应的功能后,可以针对性阅读部分源码。逐一攻破。
找开始的地方:做什么事情都要知道从那里开始,读程序也不例外
分层次阅读:在阅读代码的时候不要一头就扎下去,这样往往容易只见树木不见森林,阅读代码比较好的方法有一点象二叉树的广度优先的遍历。
重复阅读:一次就可以将所有的代码都阅读明白的人是没有的。反复的去阅读同一段代码有助于得代码的理解。
3)基本原理其实就是通过反射解析类及其类的各种信息,包括构造器、方法及其参数,属性。然后将其封装成bean定义信息类、constructor信息类、method信息类、property信息类,最终放在一个map里,也就是所谓的container,池等等,其实就是个map。
Spring是一个开放源代码的设计层面框架,他解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用。Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson创建。简单来说,Spring是一个分层的JavaSE/EE full-stack(一站式) 轻量级开源框架。
架构

Spring框架是一个分层架构,它包含一系列的功能要素,并被分为大约20个模块,如下图所示:
从上图spring framework整体架构图可以看到,这些模块被总结为以下几个部分:
Core Container
Beans:所有应用都要用到的,它包含访问配置文件、创建和管理bean以及进行Inversion of Control/Dependency Injection(Ioc/DI)操作相关的所有类
Core:包含Spring框架基本的核心工具类
Context:为Spring核心提供了大量扩展,添加了对国际化(如资源绑定)、事件传播、资源加载和对Context的透明创建的支持。ApplicationContext接口是Context模块的关键
Spel:提供了一个强大的表达式语言用于在运行时查询和操纵对象,该语言支持设置/获取属性的值,属性的分配,方法的调用,访问数组上下文、容器和索引器、逻辑和算术运算符、命名变量以及从Spring的IoC容器中根据名称检索对象
Data Access/Integration
JDBC:提供了一个JDBC抽象层,包含了Spring对JDBC数据访问进行封装的所有类
ORM:为流行的对象-关系映射API,如JPA、JDO、Hibernate、iBatis等,提供了一个交互层,利用ORM封装包,可以混合使用所有Spring提供的特性进行O/R映射,如前边提到的简单声明性事务管理
OXM:提供了一个Object/XML映射实现的抽象层,Object/XML映射实现抽象层包括JAXB,Castor,XMLBeans,JiBX和XStream JMS(java Message Service):主要包含了一些制造和消费消息的特性 Transaction:模块支持编程和声明式事物管理,这些事务类必须实现特定的接口,并且对所有POJO都适用
Web
Web:提供了基础的面向Web的集成特性,例如,多文件上传、使用Servlet listeners初始化IoC容器以及一个面向Web的应用上下文,它还包含了Spring远程支持中Web的相关部分
Web-Servlet:该模块包含Spring的model-view-controller(MVC)实现,Spring的MVC框架使得模型范围内的代码和web forms之间能够清楚地分离开来,并与Spring框架的其他特性基础在一起
Web-Socket模块:主要是与web前端的全双工通讯协议
Web-Porlet模块:提供了用于Portlet环境和Web-Servlet模块的MVC的实现
AOP
AOP模块提供了一个符合AOP联盟标准的面向切面编程的实现,它让你可以定义例如方法拦截器和切点,从而将逻辑代码分开,降低它们之间的耦合性,利用source-level的元数据功能,还可以将各种行为信息合并到你的代码中 Spring AOP模块为基于Spring的应用程序中的对象提供了事务管理服务,通过使用Spring AOP,不用依赖EJB组件,就可以将声明性事务管理集成到应用程序中
Test
Spring 支持 Junit 和 TestNG 测试框架,而且还额外提供了一些基于 Spring 的测试功能,比如在测试 Web 框架时,模拟 Http 请求的功能。
源码链接获取
进入官网https://projects.spring.io/spring-framework/,进入github下载相应版本的spring源码。
IOC 之 容器的基本实现
bean是spring最核心的东西,spring就像是一个大水桶,而bean就是水桶中的水,水桶脱离了水也就没有什么用处了。接下来我们先了解下spring-bean最核心的两个类:DefaultListableBeanFactory和XmlBeanDefinitionReader。
核心类
DefaultListableBeanFactory
DefaultListableBeanFactory是整个bean加载的核心部分,是Spring注册及加载bean的默认实现
XmlBeanFactory继承自DefaultListableBeanFactory,使用了自定义的XML读取器XmlBeanDefinitionReader,实现了个性化的BeanDefinitionReader读取

上面类图中各个类及接口的作用如下:
- AliasRegistry:定义对alias的简单增删改等操作
- SimpleAliasRegistry:主要使用map作为alias的缓存,并对接口AliasRegistry进行实现
- SingletonBeanRegistry:定义对单例的注册及获取
- BeanFactory:定义获取bean及bean的各种属性
- DefaultSingletonBeanRegistry:默认对接口SingletonBeanRegistry各函数的实现
- HierarchicalBeanFactory:继承BeanFactory,也就是在BeanFactory定义的功能的基础上增加了对parentFactory的支持
- BeanDefinitionRegistry:定义对BeanDefinition的各种增删改操作
- FactoryBeanRegistrySupport:在DefaultSingletonBeanRegistry基础上增加了对FactoryBean的特殊处理功能
- ConfigurableBeanFactory:提供配置Factory的各种方法
- ListableBeanFactory:根据各种条件获取bean的配置清单
- AbstractBeanFactory:综合FactoryBeanRegistrySupport和ConfigurationBeanFactory的功能
- AutowireCapableBeanFactory:提供创建bean、自动注入、初始化以及应用bean的后处理器
- AbstractAutowireCapableBeanFactory:综合AbstractBeanFactory并对接口AutowireCapableBeanFactory进行实现
- ConfigurableListableBeanFactory:BeanFactory配置清单,指定忽略类型及接口等
- DefaultListableBeanFactory:综合上面所有功能,主要是对Bean注册后的处理
XmlBeanFactory对DefaultListableBeanFactory类进行了扩展,主要用于从XML文档中读取BeanDefinition,对于注册及获取Bean都是使用从父类DefaultListableBeanFactory继承的方法去实现,而唯独与父类不同的个性化实现就是增加了XmlBeanDefinitionReader类型的reader属性。在XmlBeanFactory中主要使用reader属性对资源文件进行读取和注册
XmlBeanDefinitionReader
XML配置文件的读取是Spring中重要的功能,因为Spring的大部分功能都是以配置作为切入点的,可以从XmlBeanDefinitionReader中梳理一下资源文件读取、解析及注册的大致脉络

- ResourceLoader: 定义资源加载器,主要用于根据给定的资源文件地址返回对应的 Resource。
- BeanDefinitionReader: 主要定义资源文件读取并转换为 BeanDefinition 的各个功能。
- EnvironmentCapable: 定义获取 Environment 方法。
- DocumentLoader: 定义从资源文件加载到转换为 Document 的功能。
- AbstractBeanDefinitionReader: 对 EnvironmentCapable 、BeanDefinitionReader 类定义的功能进行实现。
- BeanDefinitionDocumentReader: 定义读取 Document 并注册 BeanDefinition 功能
- BeanDefinitionParserDelegate: 定义解析 Element 的各种方法。
为了更清晰地说明DefaultListableBeanFactory的作用,列举一下DefaultListableBeanFactory中存储的一些重要对象及对象中的内容,DefaultListableBeanFactory基本就是操作这些对象,以表格形式说明:
| 对象名 | 类 型 | 作 用 | 归属类 |
|---|---|---|---|
| aliasMap | Map<String, String> | 存储Bean名称->Bean别名映射关系 | SimpleAliasRegistry |
| singletonObjects | Map<String, Object> | 存储单例Bean名称->单例Bean实现映射关系 | DefaultSingletonBeanRegistry |
| singletonFactories | Map<String, ObjectFactory> | 存储Bean名称->ObjectFactory实现映射关系 | DefaultSingletonBeanRegistry |
| earlySingletonObjects | Map<String, Object> | 存储Bean名称->预加载Bean实现映射关系 | DefaultSingletonBeanRegistry |
| registeredSingletons | Set |
存储注册过的Bean名 | DefaultSingletonBeanRegistry |
| singletonsCurrentlyInCreation | Set |
存储当前正在创建的Bean名 | DefaultSingletonBeanRegistry |
| disposableBeans | Map<String, Object> | 存储Bean名称->Disposable接口实现Bean实现映射关系 | DefaultSingletonBeanRegistry |
| factoryBeanObjectCache | Map<String, Object> | 存储Bean名称->FactoryBean接口Bean实现映射关系 | FactoryBeanRegistrySupport |
| propertyEditorRegistrars | Set |
存储PropertyEditorRegistrar接口实现集合 | AbstractBeanFactory |
| embeddedValueResolvers | List |
存储StringValueResolver(字符串解析器)接口实现列表 | AbstractBeanFactory |
| beanPostProcessors | List |
存储 BeanPostProcessor接口实现列表 | AbstractBeanFactory |
| mergedBeanDefinitions | Map<String, RootBeanDefinition> | 存储Bean名称->合并过的根Bean定义映射关系 | AbstractBeanFactory |
| alreadyCreated | Set |
存储至少被创建过一次的Bean名集合 | AbstractBeanFactory |
| ignoredDependencyInterfaces | Set |
存储不自动装配的接口Class对象集合 | AbstractAutowireCapableBeanFactory |
| resolvableDependencies | Map<Class, Object> | 存储修正过的依赖映射关系 | DefaultListableBeanFactory |
| beanDefinitionMap | Map<String, BeanDefinition> | 存储Bean名称–>Bean定义映射关系 | DefaultListableBeanFactory |
| beanDefinitionNames | List |
存储Bean定义名称列表 | DefaultListableBeanFactory |
读取配置并注册Bean流程
通过上面的内容我们对spring的容器已经有了大致的了解,接下来我们详细探索每个步骤的详细实现
BeanFactory beanFactory = new XmlBeanFactory( new ClassPathResource("application.xml"));
Spring从XML配置文件读取并加载Bean的流程主要包含以下几步处理
- 通过ClassPathResource读取资源文件并转为对应的Resource
- 通过DocumentLoader对Resource文件进行转换,将Resource文件转换为Document文件
- 通过实现接口BeanDefinitionDocumentReader的DefaultBeanDefinitionDocumentReader类对Document进行解析,并使用BeanDefinitionParserDelegate对Element进行解析
读取资源文件
Spring提供了Resource 接口对所有资源文件进行统一处理。以 ClassPathResource.getlnputStream 为例,实现方式便是通 class 或者 classLoader 提供的底层方法进行调用
public InputStream getInputStream() throws IOException {
InputStream is;
if (this.clazz != null) {
is = this.clazz.getResourceAsStream(this.path);
} else if (this.classLoader != null) {
is = this.classLoader.getResourceAsStream(this.path);
} else {
is = ClassLoader.getSystemResourceAsStream(this.path);
}
if (is == null) {
throw new FileNotFoundException(this.getDescription() + " cannot be opened because it does not exist");
} else {
return is;
}
}
Bean加载
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader;
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, (BeanFactory)null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader = new XmlBeanDefinitionReader(this);
this.reader.loadBeanDefinitions(resource);
}
}
上面函数中的代码this.reader.loadBeanDefinitions(resource)才是资源加载的真正实现。
获取Document
对于文档的读取委托给了DocumentLoader去执行,这里的DocumentLoader是个接口,而真正调用的是DefaultDocumentLoader,解析代码如下:
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
分析代码,首选创建DocumentBuildFactory,再通过DocumentBuilderFactory创建DocumentBuilder,进而解析InputSource来返回Document对象。
解析BeanDefinitions
当把文件转换成Document后,接下来就是对bean的提取及注册,当程序已经拥有了XML文档文件的Document实例对象时,就会被引入到XmlBeanDefinitionReader.registerBeanDefinitions这个方法:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
其中的doc参数即为上节读取的document,而BeanDefinitionDocumentReader是一个接口,而实例化的工作是在createBeanDefinitionDocumentReader()中完成的,而通过此方法,BeanDefinitionDocumentReader真正的类型其实已经是DefaultBeanDefinitionDocumentReader了,进入DefaultBeanDefinitionDocumentReader后,发现这个方法的重要目的之一就是提取root,以便于再次将root作为参数继续BeanDefinition的注册,如下代码:
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
通过这里我们看到终于到了解析逻辑的核心方法doRegisterBeanDefinitions
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
我们看到首先要解析profile属性,然后才开始XML的读取,具体的代码如下:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
最终解析动作落地在两个方法处:parseDefaultElement(ele, delegate) 和 delegate.parseCustomElement(root)。我们知道在 Spring 有两种 Bean 声明方式:
-
配置文件式声明:
<!--bean就是java对象 , 由Spring创建和管理--> <bean id="helloWorld" class="com.demo.HeloWorld"> <property name="name" value="Spring"/> </bean> -
自定义注解方式:
<tx:annotation-driven>``` <tx:annotation-driven> ```
两种方式的读取和解析都存在较大的差异,所以采用不同的解析方法,如果根节点或者子节点采用默认命名空间的话,则调用 parseDefaultElement() 进行解析,否则调用 delegate.parseCustomElement() 方法进行自定义解析。
而判断是否默认命名空间还是自定义命名空间的办法其实是使用node.getNamespaceURI()获取命名空间,并与Spring中固定的命名空间http://www.springframework.org/schema/beans进行对比,如果一致则认为是默认,否则就认为是自定义。
注册解析的BeanDefinition
对于配置文件,解析和装饰完成之后,对于得到的beanDefinition已经可以满足后续的使用要求了,还剩下注册,也就是processBeanDefinition函数中的BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder,getReaderContext().getRegistry())代码的解析了。进入方法体:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
//使用beanName做唯一标识注册
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
//注册所有的别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
从上面的代码我们看到是用了beanName作为唯一标示进行注册的,然后注册了所有的别名aliase。而beanDefinition最终都是注册到BeanDefinitionRegistry中。
详细分析
Resource接口
Spring的配置文件读取是通过ClassPathResource进行封装的,Spring对其内部使用到的资源实现了自己的抽象结构。Resource接口抽象了所有Spring内部使用到的底层资源:File、URL、Classpath等。如下源码:
/**
* InputStreamSource封装任何能返回InputStream的类,比如File、Classpath下的资源和Byte Array等, * 它只有一个方法定义:getInputStream(),该方法返回一个新的InputStream对象 。
*/
public interface InputStreamSource {
InputStream getInputStream() throws IOException;
}
public interface Resource extends InputStreamSource {
boolean exists();
default boolean isReadable() {
return true;
}
default boolean isOpen() {
return false;
}
default boolean isFile() {
return false;
}
URL getURL() throws IOException;
URI getURI() throws IOException;
File getFile() throws IOException;
default ReadableByteChannel readableChannel() throws IOException {
return Channels.newChannel(getInputStream());
}
long contentLength() throws IOException;
long lastModified() throws IOException;
Resource createRelative(String relativePath) throws IOException;
String getFilename();
String getDescription();
}
- getInputStream(): 找到并打开资源,返回一个InputStream以从资源中读取。预计每次调用都会返回一个新的InputStream(),调用者有责任关闭每个流
- exists(): 返回一个布尔值,表明某个资源是否以物理形式存在
- isOpen: 返回一个布尔值,指示此资源是否具有开放流的句柄。如果为true,InputStream就不能够多次读取,只能够读取一次并且及时关闭以避免内存泄漏。对于所有常规资源实现,返回false,但是InputStreamResource除外。
-
getDescription(): 返回资源的描述,用来输出错误的日志。这通常是完全限定的文件名或资源的实际URL。
- isReadable(): 表明资源的目录读取是否通过getInputStream()进行读取。
- isFile(): 表明这个资源是否代表了一个文件系统的文件。
- getURL(): 返回一个URL句柄,如果资源不能够被解析为URL,将抛出IOException
- getURI(): 返回一个资源的URI句柄
- getFile(): 返回某个文件,如果资源不能够被解析称为绝对路径,将会抛出FileNotFoundException
- lastModified(): 资源最后一次修改的时间戳
- createRelative(): 创建此资源的相关资源
- getFilename(): 资源的文件名是什么 例如:最后一部分的文件名 myfile.txt
Resource实现类
对不同来源的资源文件都有相应的Resource实现:文件(FileSystemResource)、Classpath资源(ClassPathResource)、URL资源(UrlResource)、InputStream资源(InputStreamResource)、Byte数组(ByteArrayResource)、Servlet资源(ServletContextResource)等

在日常开发中我们可以直接使用spring提供的类来加载资源文件,比如在希望加载资源文件时可以使用下面的代码:
package com.demo;
import org.junit.Test;
import org.springframework.core.io.*;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
public class ResourceTest {
/**使用ClassPathResource获取资源**/
@Test
public void TestClassPath() throws IOException {
Resource resource = new ClassPathResource("test.txt");
//判断文件是否存在:
if (resource.exists()) {
System.out.println("文件存在");
}
//判断资源文件是否可读
if (resource.isReadable()) {
System.out.println("文件可读");
}
//判断当前Resource代表的底层资源是否已经打开
if (resource.isOpen()) {
System.out.println("资源文件已打开");
}
System.out.println(resource.getURL());//获取资源所在的URL
System.out.println(resource.getURI());//获取资源所在的URI
resource.getFile();//返回当前资源对应的File。
System.out.println(resource.contentLength());//输出内容长度
System.out.println(resource.lastModified());//返回当前Resource代表的底层资源的最后修改时间。
resource.createRelative("MyFile");//根据资源的相对路径创建新资源。[默认不支持创建相对路径资源]
System.out.println(resource.getFilename());//获取资源文件名
System.out.println(resource.getDescription());
//获取当前资源代表的输入流
if (resource.isReadable()) {
InputStream is = resource.getInputStream();
System.out.println(is);
is.close();
}
}
/**使用FileSystemResource获取资源**/
@Test
public void TestFileSystem() throws IOException {
Resource resource = new FileSystemResource("D:\\test.txt");
System.out.println(resource.getFilename());
}
/**使用UrlResource获取资源**/
@Test
public void TestUrl() throws MalformedURLException {
Resource resource = new UrlResource("http://docs.spring.io/spring/docs/4.0.0.M1/spring-framework-reference/pdf/spring-framework-reference.pdf");
System.out.println(resource.getFilename());
}
/**使用ByteArrayResource获取字节数组封装的资源**/
@Test
public void testByteArray() throws IOException {
ByteArrayResource resource = new ByteArrayResource("Hello".getBytes());
System.out.println(resource.getInputStream());
}
/**使用InputStreamResource获取输入流封装的资源。针对于输入流的Resource,其getInputStream()方法只能被调用一次。**/
@Test
public void testInputStream() throws Exception {
InputStream is = new FileInputStream("D\\test.txt");
InputStreamResource resource = new InputStreamResource(is);
//对于InputStreamResource而言,其getInputStream()方法只能调用一次,继续调用将抛出异常。
InputStream is2 = resource.getInputStream(); //返回的就是构件时的那个InputStream
System.out.println(is2);
is.close();
}
}
Resource 接口是 Spring 资源访问策略的抽象,它本身并不提供任何资源访问实现,具体的资源访问由该接口的实现类完成——每个实现类代表一种资源访问策略。
- 使用UrlResource访问网络资源。Resource的一个实现类用来定位URL中的资源。
- file:-该前缀用于访问本地资源。
- http:-该前缀用于访问基于 HTTP 协议的网络资源。
- ftp:-该前缀用于访问基于 FTP 协议的网络资源。
- 使用ClassPathResource 访问类加载路径下的资源。 可自动搜索位于 WEB-INF/classes 下的资源文件,无须使用绝对路径访问。
- 使用FileSystemResource 访问文件资源系统。接受一个代表资源路径的字符串参数,当 Spring 识别该字符串参数中包含 file: 前缀后,系统将会自动创建 FileSystemResource 对象。
- ServletContextResource解释相关Web应用程序根目录中的相对路径。
- InputStreamResource是给定的输入流(InputStream)的Resource实现。与其他Resource实现相比,这是已打开资源的描述符。 因此,它的isOpen()方法返回true。如果需要将资源描述符保留在某处或者需要多次读取流,请不要使用它。
- ByteArrayResource字节数组的Resource实现类。通过给定的数组创建了一个ByteArrayInputStream。
ResourceLoader 接口
ResourceLoader接口旨在由可以返回(即加载)Resource实例的对象实现,该接口实现类的实例将获得一个 ResourceLoader 的引用。下面是ResourceLoader的定义
public interface ResourceLoader {
//该接口仅包含这个方法,该方法用于返回一个 Resource 实例。ApplicationContext 的实现类都实现 ResourceLoader 接口,因此 ApplicationContext 可用于直接获取 Resource 实例
Resource getResource(String location);
}
ResourceLoader在进行加载资源时需要使用前缀来指定需要加载:“classpath:path”表示返回ClasspathResource,“http://path”和“file:path”表示返回UrlResource资源,如果不加前缀则需要根据当前上下文来决定,DefaultResourceLoader默认实现是加载classpath资源。
@Test
public void testResourceLoader() {
ResourceLoader loader = new DefaultResourceLoader();
Resource resource = loader.getResource("http://www.baidu.com");
System.out.println(resource instanceof UrlResource); //true
resource = loader.getResource("classpath:test.txt");
System.out.println(resource instanceof ClassPathResource); //true
resource = loader.getResource("test.txt");
System.out.println(resource instanceof ClassPathResource); //true
}
下列表格对资源类型和前缀进行更好的汇总:
| Prefix | Example | Explanation |
|---|---|---|
| classpath: | classpath:com/myapp/config.xml | 从类路径加载 |
| file: | file:///data/config.xml | 从文件系统加载作为URL,查阅FileSystemResource |
| http: | https://myserver/logo.png | 加载作为URL |
| (none) | /data/config.xml | 依赖于ApplicationContext |
ResourceLoaderAware 接口
这个ResourceLoaderAware接口是一个特殊的回调接口,用于标识希望随ResourceLoader引用提供的组件,下面是ResourceLoaderAware 接口的定义
public interface ResourceLoaderAware extends Aware {
void setResourceLoader(ResourceLoader resourceLoader);
}
ResourceLoaderAware 接口用于指定该接口的实现类必须持有一个 ResourceLoader 实例。
一个 bean 若想加载指定路径下的资源,除了刚才提到的实现 ResourcesLoaderAware 接口之外(将 ApplicationContext 作为一个 ResourceLoader 对象注入),bean 也可以实现 ApplicationContextAware 接口,这样可以直接使用应用上下文来加载资源。也可采取另外一种替代方案——依赖于 ResourceLoader 的自动装配。使用注解 @Autowiring 标记 ResourceLoader 变量,便可将其注入到成员属性、构造参数或方法参数中。
XmlBeanFactory
XmlBeanFactory继承自DefaultListableBeanFactory,扩展了从xml文档中读取bean definition的能力。从本质上讲,XmlBeanFactory等同于DefaultListableBeanFactory+XmlBeanDefinitionReader
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader;
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, (BeanFactory)null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader = new XmlBeanDefinitionReader(this);
this.reader.loadBeanDefinitions(resource);
}
}
上面函数中的代码this.reader.loadBeanDefinitions(resource)才是资源加载的真正实现。
XmlBeanDefinitionReader
在XmlBeanFactory构造函数中调用了XmlBeanDefinitionReader类型的reader属性提供的方法this.reader.loadBeanDefinitions(resource),而这句代码则是整个资源加载的切入点

我们来梳理下上述时序图的处理过程:
- 封装资源文件。当进入XmlBeanDefinitionReader后首先对参数Resource使用EncodedResource类进行封装
- 获取输入流。从Resource中获取对应的InputStream并构造InputSource
- 通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions,loadBeanDefinitions
源码如下
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isTraceEnabled()) {
logger.trace("Loading XML bean definitions from " + encodedResource);
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
...
}
EncodedResource的作用是对资源文件的编码进行处理的,其中的主要逻辑体现在getReader()方法中,当设置了编码属性的时候Spring会使用相应的编码作为输入流的编码,在构造好了encodeResource对象后,再次转入了可复用方法loadBeanDefinitions(new EncodedResource(resource)),这个方法内部才是真正的数据准备阶段,代码如下:
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 获取 Document 实例
Document doc = doLoadDocument(inputSource, resource);
// 根据 Document 实例****注册 Bean信息
return registerBeanDefinitions(doc, resource);
}
...
}
核心部分就是 try 块的两行代码。
- 调用
doLoadDocument()方法,根据 xml 文件获取 Document 实例。 - 根据获取的 Document 实例注册 Bean 信息
ignoreDependencylnterface
在XmlBeanFactory还有一个调用父类构造函数初始化的过程:super(parentBeanFactory)
跟踪代码到父类AbstractAutowireCapableBeanFactory的构造函数中
public AbstractAutowireCapableBeanFactory(@Nullable BeanFactory parentBeanFactory) {
this();
setParentBeanFactory(parentBeanFactory);
}
public AbstractAutowireCapableBeanFactory() {
super();
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
}
这里有必要提及 ignoreDependencylnterface方法,ignoreDependencylnterface 的主要功能是 忽略给定接口的向动装配功能,那么,这样做的目的是什么呢?会产生什么样的效果呢?
举例来说,当 A 中有属性 B ,那么当 Spring 在获取 A的 Bean 的时候如果其属性 B 还没有 初始化,那么 Spring 会自动初始化 B,这也是 Spring 提供的一个重要特性 。但是,某些情况 下, B不会被初始化,其中的一种情况就是B 实现了 BeanNameAware 接口 。Spring 中是这样介绍的:自动装配时忽略给定的依赖接口,典型应用是边过其他方式解析 Application 上下文注册依赖,类似于 BeanFactor 通过 BeanFactoryAware 进行注入或者 ApplicationContext 通过 ApplicationContextAware 进行注入。
调用ignoreDependencyInterface方法后,被忽略的接口会存储在BeanFactory的名为ignoredDependencyInterfaces的Set集合中:
public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory
implements AutowireCapableBeanFactory {
private final Set<Class<?>> ignoredDependencyInterfaces = new HashSet<>();
public void ignoreDependencyInterface(Class<?> ifc) {
this.ignoredDependencyInterfaces.add(ifc);
}
...
}
ignoredDependencyInterfaces集合在同类中被使用仅在一处——isExcludedFromDependencyCheck方法中:
protected boolean isExcludedFromDependencyCheck(PropertyDescriptor pd) {
return (AutowireUtils.isExcludedFromDependencyCheck(pd) || this.ignoredDependencyTypes.contains(pd.getPropertyType()) || AutowireUtils.isSetterDefinedInInterface(pd, this.ignoredDependencyInterfaces));
}
而ignoredDependencyInterface的真正作用还得看AutowireUtils类的isSetterDefinedInInterface方法。
public static boolean isSetterDefinedInInterface(PropertyDescriptor pd, Set<Class<?>> interfaces) {
//获取bean中某个属性对象在bean类中的setter方法
Method setter = pd.getWriteMethod();
if (setter != null) {
// 获取bean的类型
Class<?> targetClass = setter.getDeclaringClass();
for (Class<?> ifc : interfaces) {
if (ifc.isAssignableFrom(targetClass) && // bean类型是否接口的实现类
ClassUtils.hasMethod(ifc, setter.getName(), setter.getParameterTypes())) { // 接口是否有入参和bean类型完全相同的setter方法
return true;
}
}
}
return false;
}
ignoredDependencyInterface方法并不是让我们在自动装配时直接忽略实现了该接口的依赖。这个方法的真正意思是忽略该接口的实现类中和接口setter方法入参类型相同的依赖。 举个例子。首先定义一个要被忽略的接口。
public interface IgnoreInterface {
void setList(List<String> list);
void setSet(Set<String> set);
}
然后需要实现该接口,在实现类中注意要有setter方法入参相同类型的域对象,在例子中就是List
public class IgnoreInterfaceImpl implements IgnoreInterface {
private List<String> list;
private Set<String> set;
@Override
public void setList(List<String> list) {
this.list = list;
}
@Override
public void setSet(Set<String> set) {
this.set = set;
}
public List<String> getList() {
return list;
}
public Set<String> getSet() {
return set;
}
}
定义xml配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd"
default-autowire="byType">
<bean id="list" class="java.util.ArrayList">
<constructor-arg>
<list>
<value>foo</value>
<value>bar</value>
</list>
</constructor-arg>
</bean>
<bean id="set" class="java.util.HashSet">
<constructor-arg>
<list>
<value>foo</value>
<value>bar</value>
</list>
</constructor-arg>
</bean>
<bean id="ii" class="com.demo.ignoreDependency.IgnoreInterfaceImpl"/>
<bean class="com.demo.autowire.IgnoreAutowiringProcessor"/>
</beans>
最后调用ignoreDependencyInterface:
beanFactory.ignoreDependencyInterface(IgnoreInterface.class);
运行结果: null null 而如果不调用ignoreDependencyInterface,则是: [foo, bar] [bar, foo]
我们最初理解是在自动装配时忽略该接口的实现,实际上是在自动装配时忽略该接口实现类中和setter方法入参相同的类型,也就是忽略该接口实现类中存在依赖外部的bean属性注入。
典型应用就是BeanFactoryAware和ApplicationContextAware接口。 首先看该两个接口的源码:
public interface BeanFactoryAware extends Aware {
void setBeanFactory(BeanFactory beanFactory) throws BeansException;
}
public interface ApplicationContextAware extends Aware {
void setApplicationContext(ApplicationContext applicationContext) throws BeansException;
}
在Spring源码中在不同的地方忽略了该两个接口:
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
使得我们的BeanFactoryAware接口实现类在自动装配时不能被注入BeanFactory对象的依赖:
public class MyBeanFactoryAware implements BeanFactoryAware {
private BeanFactory beanFactory; // 自动装配时忽略注入
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
}
public BeanFactory getBeanFactory() {
return beanFactory;
}
}
ApplicationContextAware接口实现类中的ApplicationContext对象的依赖同理:
public class MyApplicationContextAware implements ApplicationContextAware {
private ApplicationContext applicationContext; // 自动装配时被忽略注入
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
public ApplicationContext getApplicationContext() {
return applicationContext;
}
}
这样的做法使得ApplicationContextAware和BeanFactoryAware中的ApplicationContext或BeanFactory依赖在自动装配时被忽略,而统一由框架设置依赖,如ApplicationContextAware接口的设置会在ApplicationContextAwareProcessor类中完成:
private void invokeAwareInterfaces(Object bean) {
if (bean instanceof Aware) {
if (bean instanceof EnvironmentAware) {
((EnvironmentAware) bean).setEnvironment(this.applicationContext.getEnvironment());
}
if (bean instanceof EmbeddedValueResolverAware) {
((EmbeddedValueResolverAware) bean).setEmbeddedValueResolver(this.embeddedValueResolver);
}
if (bean instanceof ResourceLoaderAware) {
((ResourceLoaderAware) bean).setResourceLoader(this.applicationContext);
}
if (bean instanceof ApplicationEventPublisherAware) {
((ApplicationEventPublisherAware) bean).setApplicationEventPublisher(this.applicationContext);
}
if (bean instanceof MessageSourceAware) {
((MessageSourceAware) bean).setMessageSource(this.applicationContext);
}
if (bean instanceof ApplicationContextAware) {
((ApplicationContextAware) bean).setApplicationContext(this.applicationContext);
}
}
}
通过这种方式保证了ApplicationContextAware和BeanFactoryAware中的容器保证是生成该bean的容器。
profile的用法
IOC 之 默认标签解析
Spring的标签中有默认标签和自定义标签,两者的解析有着很大的不同,这次重点说默认标签的解析过程。
默认标签的解析过程
默认标签的解析是在DefaultBeanDefinitionDocumentReader.parseDefaultElement函数中进行的,分别对4种不同的标签(import,alias,bean和beans)做了不同处理。我们先看下此函数的源码:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
Bean标签的解析及注册
在4种标签中对bean标签的解析最为复杂也最为重要,所以从此标签开始深入分析,如果能理解这个标签的解析过程,其他标签的解析就迎刃而解了。对于bean标签的解析用的是processBeanDefinition函数,首先看看函数processBeanDefinition(ele,delegate),其代码如下:
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
我们细致的理下逻辑,大致流程如下:
- 首先委托BeanDefinitionDelegate类的parseBeanDefinitionElement方法进行元素的解析,返回BeanDefinitionHolder类型的实例bdHolder,经过这个方法后bdHolder实例已经包含了我们配置文件中的各种属性了,例如class,name,id,alias等。
- 当返回的dbHolder不为空的情况下若存在默认标签的子节点下再有自定义属性,还需要再次对自定义标签进行解析。
- 当解析完成后,需要对解析后的bdHolder进行注册,注册过程委托给了BeanDefinitionReaderUtils的registerBeanDefinition方法。
- 最后发出响应事件,通知相关的监听器已经加载完这个Bean了。
解析BeanDefinition
接下来我们就针对具体的方法进行分析,首先我们从元素解析及信息提取开始,也就是BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele),进入 BeanDefinitionDelegate 类的 parseBeanDefinitionElement 方法。我们看下源码:
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 解析 ID 属性
String id = ele.getAttribute(ID_ATTRIBUTE);
// 解析 name 属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 分割 name 属性
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
// 检查 name 的唯一性
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 解析 属性,构造 AbstractBeanDefinition
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
// 如果 beanName 不存在,则根据条件构造一个 beanName
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
// 封装 BeanDefinitionHolder
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
上述方法就是对默认标签解析的全过程了,我们分析下当前层完成的工作:
- 提取元素中的id和name属性
- 进一步解析其他所有属性并统一封装到GenericBeanDefinition类型的实例中
- 如果检测到bean没有指定beanName,那么使用默认规则为此bean生成beanName。
- 将获取到的信息封装到BeanDefinitionHolder的实例中。 代码:AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);是用来对标签中的其他属性进行解析,我们详细看下源码:
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
//解析class属性
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
//解析parent属性
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
//创建用于承载属性的AbstractBeanDefinition类型的GenericBeanDefinition实例
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//硬编码解析bean的各种属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
//设置description属性
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
//解析元素
parseMetaElements(ele, bd);
//解析lookup-method属性
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//解析replace-method属性
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析构造函数的参数
parseConstructorArgElements(ele, bd);
//解析properties子元素
parsePropertyElements(ele, bd);
//解析qualifier子元素
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
Bean详细解析过程
BeanDefinition
BeanDefinition是一个接口,在spring中此接口有三种实现:RootBeanDefinition、ChildBeanDefinition、GenericBeanDefinition。而三种实现都继承了AbstractBeanDefinition,其中BeanDefinition是配置文件元素标签在容器中的内部表示形式。元素标签拥有class、scope、lazy-init等属性,BeanDefinition则提供了相应的beanClass、scope、lazyInit属性,BeanDefinition和
Spring通过BeanDefinition将配置文件中的配置信息转换为容器的内部表示,并将这些BeanDefinition注册到BeanDefinitionRegistry中。Spring容器的BeanDefinitionRegistry就像是Spring配置信息的内存数据库,主要是以map的形式保存,后续操作直接从BeanDefinitionResistry中读取配置信息。它们之间的关系如下图所示:

因此,要解析属性首先要创建用于承载属性的实例,也就是创建GenericBeanDefinition类型的实例。而代码createBeanDefinition(className,parent)的作用就是实现此功能。我们详细看下方法体,代码如下:
protected AbstractBeanDefinition createBeanDefinition(@Nullable String className, @Nullable String parentName)
throws ClassNotFoundException {
return BeanDefinitionReaderUtils.createBeanDefinition(
parentName, className, this.readerContext.getBeanClassLoader());
}
public static AbstractBeanDefinition createBeanDefinition(
@Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader) throws ClassNotFoundException {
GenericBeanDefinition bd = new GenericBeanDefinition();
bd.setParentName(parentName);
if (className != null) {
if (classLoader != null) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
}
else {
bd.setBeanClassName(className);
}
}
return bd;
}
各种属性的解析
当创建好了承载bean信息的实例后,接下来就是解析各种属性了,首先我们看下parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);方法,代码如下:
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
@Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {
//解析singleton属性
if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
}
//解析scope属性
else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
}
else if (containingBean != null) {
// Take default from containing bean in case of an inner bean definition.
bd.setScope(containingBean.getScope());
}
//解析abstract属性
if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
}
//解析lazy_init属性
String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
if (DEFAULT_VALUE.equals(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit(TRUE_VALUE.equals(lazyInit));
//解析autowire属性
String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
bd.setAutowireMode(getAutowireMode(autowire));
//解析dependsOn属性
if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
}
//解析autowireCandidate属性
String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
if ("".equals(autowireCandidate) || DEFAULT_VALUE.equals(autowireCandidate)) {
String candidatePattern = this.defaults.getAutowireCandidates();
if (candidatePattern != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
}
else {
bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
}
//解析primary属性
if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
}
//解析init_method属性
if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {
String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);
bd.setInitMethodName(initMethodName);
}
else if (this.defaults.getInitMethod() != null) {
bd.setInitMethodName(this.defaults.getInitMethod());
bd.setEnforceInitMethod(false);
}
//解析destroy_method属性
if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {
String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);
bd.setDestroyMethodName(destroyMethodName);
}
else if (this.defaults.getDestroyMethod() != null) {
bd.setDestroyMethodName(this.defaults.getDestroyMethod());
bd.setEnforceDestroyMethod(false);
}
//解析factory_method属性
if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {
bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));
}
//解析factory_bean属性
if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {
bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));
}
return bd;
}
解析meta元素
在开始对meta元素解析分析前我们先简单回顾下meta属性的使用,简单的示例代码如下:
<bean id="demo" class="com.yhl.myspring.demo.bean.MyBeanDemo">
<property name="beanName" value="bean demo1"/>
<meta key="demo" value="demo"/>
</bean>
这段代码并不会提现在demo的属性中,而是一个额外的声明,如果需要用到这里面的信息时可以通过BeanDefinition的getAttribute(key)方法获取,对meta属性的解析用的是:parseMetaElements(ele, bd);具体的方法体如下:
// 元数据,当需要使用里面的信息时可以通过key获取。
public void parseMetaElements(Element ele, BeanMetadataAttributeAccessor attributeAccessor) {
NodeList nl = ele.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, META_ELEMENT)) {
Element metaElement = (Element) node;
String key = metaElement.getAttribute(KEY_ATTRIBUTE);
String value = metaElement.getAttribute(VALUE_ATTRIBUTE);
BeanMetadataAttribute attribute = new BeanMetadataAttribute(key, value);
attribute.setSource(extractSource(metaElement));
attributeAccessor.addMetadataAttribute(attribute);
}
}
}
解析replaced-method属性
在分析代码前我们还是先简单的了解下replaced-method的用法,其主要功能是方法替换:即在运行时用新的方法替换旧的方法。与之前的lookup-method不同的是此方法不仅可以替换返回的bean,还可以动态的更改原有方法的运行逻辑,我们看下使用:
//原有的changeMe方法
public class TestChangeMethod {
public void changeMe()
{
System.out.println("ChangeMe");
}
}
//新的实现方法
public class ReplacerChangeMethod implements MethodReplacer {
public Object reimplement(Object o, Method method, Object[] objects) throws Throwable {
System.out.println("I Replace Method");
return null;
}
}
//新的配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="changeMe" class="com.chenhao.spring.TestChangeMethod">
<replaced-method name="changeMe" replacer="replacer"/>
</bean>
<bean id="replacer" class="com.chenhao.spring.ReplacerChangeMethod"></bean>
</beans>
//测试方法
public class TestDemo {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("replaced-method.xml");
TestChangeMethod test =(TestChangeMethod) context.getBean("changeMe");
test.changeMe();
}
}
接下来我们看下解析replaced-method的方法代码:
// 可以在运行时调用新的方法替换现有的方法,还能动态的更新原有方法的逻辑。
//无论是 look-up 还是 replaced-method 是构造了 MethodOverride ,
// 并最终记录在了 AbstractBeanDefinition 中的 methodOverrides 属性中
public void parseReplacedMethodSubElements(Element beanEle, MethodOverrides overrides) {
NodeList nl = beanEle.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, REPLACED_METHOD_ELEMENT)) {
Element replacedMethodEle = (Element) node;
String name = replacedMethodEle.getAttribute(NAME_ATTRIBUTE);
String callback = replacedMethodEle.getAttribute(REPLACER_ATTRIBUTE);
ReplaceOverride replaceOverride = new ReplaceOverride(name, callback);
// Look for arg-type match elements.
List<Element> argTypeEles = DomUtils.getChildElementsByTagName(replacedMethodEle, ARG_TYPE_ELEMENT);
for (Element argTypeEle : argTypeEles) {
String match = argTypeEle.getAttribute(ARG_TYPE_MATCH_ATTRIBUTE);
match = (StringUtils.hasText(match) ? match : DomUtils.getTextValue(argTypeEle));
if (StringUtils.hasText(match)) {
replaceOverride.addTypeIdentifier(match);
}
}
replaceOverride.setSource(extractSource(replacedMethodEle));
overrides.addOverride(replaceOverride);
}
}
}
我们可以看到无论是 look-up 还是 replaced-method 是构造了 MethodOverride ,并最终记录在了 AbstractBeanDefinition 中的 methodOverrides 属性中
解析constructor-arg
对构造函数的解析式非常常用,也是非常复杂的,我们先从一个简单配置构造函数的例子开始分析,代码如下:
public void parseConstructorArgElement(Element ele, BeanDefinition bd) {
//提前index属性
String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);
//提前type属性
String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);
//提取name属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
if (StringUtils.hasLength(indexAttr)) {
try {
int index = Integer.parseInt(indexAttr);
if (index < 0) {
error("'index' cannot be lower than 0", ele);
}
else {
try {
this.parseState.push(new ConstructorArgumentEntry(index));
//解析ele对应的元素属性
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
if (StringUtils.hasLength(typeAttr)) {
valueHolder.setType(typeAttr);
}
if (StringUtils.hasLength(nameAttr)) {
valueHolder.setName(nameAttr);
}
valueHolder.setSource(extractSource(ele));
if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) {
error("Ambiguous constructor-arg entries for index " + index, ele);
}
else {
bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);
}
}
finally {
this.parseState.pop();
}
}
}
catch (NumberFormatException ex) {
error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele);
}
}
else {
try {
this.parseState.push(new ConstructorArgumentEntry());
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
if (StringUtils.hasLength(typeAttr)) {
valueHolder.setType(typeAttr);
}
if (StringUtils.hasLength(nameAttr)) {
valueHolder.setName(nameAttr);
}
valueHolder.setSource(extractSource(ele));
bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);
}
finally {
this.parseState.pop();
}
}
}
上述代码的流程可以简单的总结为如下: (1)首先提取index、type、name等属性 (2)根据是否配置了index属性解析流程不同 如果配置了index属性,解析流程如下: (1)使用parsePropertyValue(ele, bd, null)方法读取constructor-arg的子元素 (2)使用ConstructorArgumentValues.ValueHolder封装解析出来的元素 (3)将index、type、name属性也封装进ValueHolder中,然后将ValueHoder添加到当前beanDefinition的ConstructorArgumentValues的indexedArgumentValues,而indexedArgumentValues是一个map类型
如果没有配置index属性,将index、type、name属性也封装进ValueHolder中,然后将ValueHoder添加到当前beanDefinition的ConstructorArgumentValues的genericArgumentValues中
public Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {
String elementName = (propertyName != null) ?
"<property> element for property '" + propertyName + "'" :
"<constructor-arg> element";
// Should only have one child element: ref, value, list, etc.
NodeList nl = ele.getChildNodes();
Element subElement = null;
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//略过description和meta属性
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
!nodeNameEquals(node, META_ELEMENT)) {
// Child element is what we're looking for.
if (subElement != null) {
error(elementName + " must not contain more than one sub-element", ele);
}
else {
subElement = (Element) node;
}
}
}
//解析ref属性
boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
//解析value属性
boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
if ((hasRefAttribute && hasValueAttribute) ||
((hasRefAttribute || hasValueAttribute) && subElement != null)) {
error(elementName +
" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
}
if (hasRefAttribute) {
String refName = ele.getAttribute(REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error(elementName + " contains empty 'ref' attribute", ele);
}
//使用RuntimeBeanReference来封装ref对应的bean
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
ref.setSource(extractSource(ele));
return ref;
}
else if (hasValueAttribute) {
//使用TypedStringValue 来封装value属性
TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
valueHolder.setSource(extractSource(ele));
return valueHolder;
}
else if (subElement != null) {
//解析子元素
return parsePropertySubElement(subElement, bd);
}
else {
// Neither child element nor "ref" or "value" attribute found.
error(elementName + " must specify a ref or value", ele);
return null;
}
}
上述代码的执行逻辑简单总结为: (1)首先略过decription和meta属性 (2)提取constructor-arg上的ref和value属性,并验证是否存在 (3)存在ref属性时,用RuntimeBeanReference来封装ref (4)存在value属性时,用TypedStringValue来封装 (5)存在子元素时,对于子元素的处理使用了方法parsePropertySubElement(subElement, bd);,其代码如下:
public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd) {
return parsePropertySubElement(ele, bd, null);
}
public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd, @Nullable String defaultValueType) {
//判断是否是默认标签处理
if (!isDefaultNamespace(ele)) {
return parseNestedCustomElement(ele, bd);
}
//对于bean标签的处理
else if (nodeNameEquals(ele, BEAN_ELEMENT)) {
BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);
if (nestedBd != null) {
nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);
}
return nestedBd;
}
else if (nodeNameEquals(ele, REF_ELEMENT)) {
// A generic reference to any name of any bean.
String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE);
boolean toParent = false;
if (!StringUtils.hasLength(refName)) {
// A reference to the id of another bean in a parent context.
refName = ele.getAttribute(PARENT_REF_ATTRIBUTE);
toParent = true;
if (!StringUtils.hasLength(refName)) {
error("'bean' or 'parent' is required for <ref> element", ele);
return null;
}
}
if (!StringUtils.hasText(refName)) {
error("<ref> element contains empty target attribute", ele);
return null;
}
RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);
ref.setSource(extractSource(ele));
return ref;
}
//idref元素处理
else if (nodeNameEquals(ele, IDREF_ELEMENT)) {
return parseIdRefElement(ele);
}
//value元素处理
else if (nodeNameEquals(ele, VALUE_ELEMENT)) {
return parseValueElement(ele, defaultValueType);
}
//null元素处理
else if (nodeNameEquals(ele, NULL_ELEMENT)) {
// It's a distinguished null value. Let's wrap it in a TypedStringValue
// object in order to preserve the source location.
TypedStringValue nullHolder = new TypedStringValue(null);
nullHolder.setSource(extractSource(ele));
return nullHolder;
}
//array元素处理
else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {
return parseArrayElement(ele, bd);
}
//list元素处理
else if (nodeNameEquals(ele, LIST_ELEMENT)) {
return parseListElement(ele, bd);
}
//set元素处理
else if (nodeNameEquals(ele, SET_ELEMENT)) {
return parseSetElement(ele, bd);
}
//map元素处理
else if (nodeNameEquals(ele, MAP_ELEMENT)) {
return parseMapElement(ele, bd);
}
//props元素处理
else if (nodeNameEquals(ele, PROPS_ELEMENT)) {
return parsePropsElement(ele);
}
else {
error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele);
return null;
}
}
解析子元素properties
对于propertie元素的解析是使用的parsePropertyElements(ele, bd);方法,我们看下其源码如下:
public void parsePropertyElements(Element beanEle, BeanDefinition bd) {
NodeList nl = beanEle.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {
parsePropertyElement((Element) node, bd);
}
}
}
里面实际的解析是用的parsePropertyElement((Element) node, bd);方法,继续跟踪代码:
public void parsePropertyElement(Element ele, BeanDefinition bd) {
String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
if (!StringUtils.hasLength(propertyName)) {
error("Tag 'property' must have a 'name' attribute", ele);
return;
}
this.parseState.push(new PropertyEntry(propertyName));
try {
//不允许多次对同一属性配置
if (bd.getPropertyValues().contains(propertyName)) {
error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
return;
}
Object val = parsePropertyValue(ele, bd, propertyName);
PropertyValue pv = new PropertyValue(propertyName, val);
parseMetaElements(ele, pv);
pv.setSource(extractSource(ele));
bd.getPropertyValues().addPropertyValue(pv);
}
finally {
this.parseState.pop();
}
}
我们看到代码的逻辑非常简单,在获取了propertie的属性后使用PropertyValue 进行封装,然后将其添加到BeanDefinition的propertyValueList中
解析子元素 qualifier
对于 qualifier 元素的获取,我们接触更多的是注解的形式,在使用 Spring 架中进行自动注入时,Spring 器中匹配的候选 Bean 数目必须有且仅有一个,当找不到一个匹配的 Bean 时, Spring容器将抛出 BeanCreationException 异常, 并指出必须至少拥有一个匹配的 Bean。
Spring 允许我们通过Qualifier 指定注入 Bean的名称,这样歧义就消除了,而对于配置方式使用如:
<bean id="myTestBean" class="com.chenhao.spring.MyTestBean"> <qualifier type="org.Springframework.beans.factory.annotation.Qualifier" value="gf" />
</bean>
其解析过程与之前大同小异 这里不再重复叙述
至此我们便完成了对 XML 文档到 GenericBeanDefinition 的转换, 就是说到这里, XML 中所有的配置都可以在 GenericBeanDefinition的实例类中应找到对应的配置。
GenericBeanDefinition 只是子类实现,而大部分的通用属性都保存在了 bstractBeanDefinition 中,那么我们再次通过 AbstractBeanDefinition 的属性来回顾一 下我们都解析了哪些对应的配置。
public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessor
implements BeanDefinition, Cloneable {
// 此处省略静态变量以及final变量
@Nullable
private volatile Object beanClass;
/**
* bean的作用范围,对应bean属性scope
*/
@Nullable
private String scope = SCOPE_DEFAULT;
/**
* 是否是抽象,对应bean属性abstract
*/
private boolean abstractFlag = false;
/**
* 是否延迟加载,对应bean属性lazy-init
*/
private boolean lazyInit = false;
/**
* 自动注入模式,对应bean属性autowire
*/
private int autowireMode = AUTOWIRE_NO;
/**
* 依赖检查,Spring 3.0后弃用这个属性
*/
private int dependencyCheck = DEPENDENCY_CHECK_NONE;
/**
* 用来表示一个bean的实例化依靠另一个bean先实例化,对应bean属性depend-on
*/
@Nullable
private String[] dependsOn;
/**
* autowire-candidate属性设置为false,这样容器在查找自动装配对象时,
* 将不考虑该bean,即它不会被考虑作为其他bean自动装配的候选者,
* 但是该bean本身还是可以使用自动装配来注入其他bean的
*/
private boolean autowireCandidate = true;
/**
* 自动装配时出现多个bean候选者时,将作为首选者,对应bean属性primary
*/
private boolean primary = false;
/**
* 用于记录Qualifier,对应子元素qualifier
*/
private final Map<String, AutowireCandidateQualifier> qualifiers = new LinkedHashMap<>(0);
@Nullable
private Supplier<?> instanceSupplier;
/**
* 允许访问非公开的构造器和方法,程序设置
*/
private boolean nonPublicAccessAllowed = true;
/**
* 是否以一种宽松的模式解析构造函数,默认为true,
* 如果为false,则在以下情况
* interface ITest{}
* class ITestImpl implements ITest{};
* class Main {
* Main(ITest i) {}
* Main(ITestImpl i) {}
* }
* 抛出异常,因为Spring无法准确定位哪个构造函数程序设置
*/
private boolean lenientConstructorResolution = true;
/**
* 对应bean属性factory-bean,用法:
* <bean id = "instanceFactoryBean" class = "example.chapter3.InstanceFactoryBean" />
* <bean id = "currentTime" factory-bean = "instanceFactoryBean" factory-method = "createTime" />
*/
@Nullable
private String factoryBeanName;
/**
* 对应bean属性factory-method
*/
@Nullable
private String factoryMethodName;
/**
* 记录构造函数注入属性,对应bean属性constructor-arg
*/
@Nullable
private ConstructorArgumentValues constructorArgumentValues;
/**
* 普通属性集合
*/
@Nullable
private MutablePropertyValues propertyValues;
/**
* 方法重写的持有者,记录lookup-method、replaced-method元素
*/
@Nullable
private MethodOverrides methodOverrides;
/**
* 初始化方法,对应bean属性init-method
*/
@Nullable
private String initMethodName;
/**
* 销毁方法,对应bean属性destroy-method
*/
@Nullable
private String destroyMethodName;
/**
* 是否执行init-method,程序设置
*/
private boolean enforceInitMethod = true;
/**
* 是否执行destroy-method,程序设置
*/
private boolean enforceDestroyMethod = true;
/**
* 是否是用户定义的而不是应用程序本身定义的,创建AOP时候为true,程序设置
*/
private boolean synthetic = false;
/**
* 定义这个bean的应用,APPLICATION:用户,INFRASTRUCTURE:完全内部使用,与用户无关,
* SUPPORT:某些复杂配置的一部分
* 程序设置
*/
private int role = BeanDefinition.ROLE_APPLICATION;
/**
* bean的描述信息
*/
@Nullable
private String description;
/**
* 这个bean定义的资源
*/
@Nullable
private Resource resource;
}
默认标签中的自定义标签解析
delegate.decorateBeanDefinitionIfRequired(ele, bdHolder)
这个方法的作用是什么呢?首先我们看下这种场景,如下配置文件:
<bean id="demo" class="com.demo.spring.MyTestBean">
<property name="beanName" value="bean demo1"/>
<meta key="demo" value="demo"/>
<mybean:username="mybean"/>
</bean>
这个配置文件中有个自定义的标签,decorateBeanDefinitionIfRequired方法就是用来处理这种情况的,其中的null是用来传递父级BeanDefinition的,我们进入到其方法体:
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder definitionHolder) {
return decorateBeanDefinitionIfRequired(ele, definitionHolder, null);
}
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(
Element ele, BeanDefinitionHolder definitionHolder, @Nullable BeanDefinition containingBd) {
BeanDefinitionHolder finalDefinition = definitionHolder;
// Decorate based on custom attributes first.
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node node = attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
// Decorate based on custom nested elements.
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node node = children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}
return finalDefinition;
}
我们看到上面的代码有两个遍历操作,一个是用于对所有的属性进行遍历处理,另一个是对所有的子节点进行处理,两个遍历操作都用到了decorateIfRequired(node, finalDefinition, containingBd);方法,我们继续跟踪代码,进入方法体:
public BeanDefinitionHolder decorateIfRequired(
Node node, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) {
// 获取自定义标签的命名空间
String namespaceUri = getNamespaceURI(node);
// 过滤掉默认命名标签
if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) {
// 获取相应的处理器
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler != null) {
// 进行装饰处理
BeanDefinitionHolder decorated =
handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
if (decorated != null) {
return decorated;
}
}
else if (namespaceUri.startsWith("http://www.springframework.org/")) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node);
}
else {
if (logger.isDebugEnabled()) {
logger.debug("No Spring NamespaceHandler found for XML schema namespace [" + namespaceUri + "]");
}
}
}
return originalDef;
}
public String getNamespaceURI(Node node) {
return node.getNamespaceURI();
}
public boolean isDefaultNamespace(@Nullable String namespaceUri) {
//BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";
return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
}
首先获取自定义标签的命名空间,如果不是默认的命名空间则根据该命名空间获取相应的处理器,最后调用处理器的 decorate() 进行装饰处理。具体的装饰过程这里不进行讲述,在后面分析自定义标签时会做详细说明。
alias标签的解析
对应bean标签的解析是最核心的功能,对于alias、import、beans标签的解析都是基于bean标签解析的,接下来我就分析下alias标签的解析。我们回到 parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate)方法,继续看下方法体,如下图所示:
对bean进行定义时,除了用id来 指定名称外,为了提供多个名称,可以使用alias标签来指定。而所有这些名称都指向同一个bean。在XML配置文件中,可用单独的元素来完成bean别名的定义。我们可以直接使用bean标签中的name属性,如下:
<bean id="demo" class="com.demo.spring.MyTestBean" name="demo1,demo2">
<property name="beanName" value="bean demo1"/>
</bean>
在Spring还有另外一种声明别名的方式:
<bean id="myTestBean" class="com.demo.spring.MyTestBean"/>
<alias name="myTestBean" alias="testBean1,testBean2"/>
我们具体看下alias标签的解析过程,解析使用的方法processAliasRegistration(ele),方法体如下:
protected void processAliasRegistration(Element ele) {
//获取beanName
String name = ele.getAttribute(NAME_ATTRIBUTE);
//获取alias
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
boolean valid = true;
if (!StringUtils.hasText(name)) {
getReaderContext().error("Name must not be empty", ele);
valid = false;
}
if (!StringUtils.hasText(alias)) {
getReaderContext().error("Alias must not be empty", ele);
valid = false;
}
if (valid) {
try {
//注册alias
getReaderContext().getRegistry().registerAlias(name, alias);
}
catch (Exception ex) {
getReaderContext().error("Failed to register alias '" + alias +
"' for bean with name '" + name + "'", ele, ex);
}
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}
通过代码可以发现解析流程与bean中的alias解析大同小异,都是将beanName与别名alias组成一对注册到registry中。跟踪代码最终使用了SimpleAliasRegistry中的registerAlias(String name, String alias)方法
import标签的解析
对于Spring配置文件的编写,经历过大型项目的人都知道,里面有太多的配置文件了。基本采用的方式都是分模块,分模块的方式很多,使用import就是其中一种,例如我们可以构造这样的Spring配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="demo" class="com.demo.spring.MyTestBean" name="demo1,demo2">
<property name="beanName" value="bean demo1"/>
</bean>
<import resource="lookup-method.xml"/>
<import resource="replaced-method.xml"/>
</beans>
applicationContext.xml文件中使用import方式导入有模块配置文件,以后若有新模块的加入,那就可以简单修改这个文件了。这样大大简化了配置后期维护的复杂度,并使配置模块化,易于管理。我们来看看Spring是如何解析import配置文件的呢。解析import标签使用的是importBeanDefinitionResource(ele),进入方法体:
protected void importBeanDefinitionResource(Element ele) {
// 获取 resource 的属性值
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
// 为空,直接退出
if (!StringUtils.hasText(location)) {
getReaderContext().error("Resource location must not be empty", ele);
return;
}
// 解析系统属性,格式如 :"${user.dir}"
location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
Set<Resource> actualResources = new LinkedHashSet<>(4);
// 判断 location 是相对路径还是绝对路径
boolean absoluteLocation = false;
try {
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
}
catch (URISyntaxException ex) {
// cannot convert to an URI, considering the location relative
// unless it is the well-known Spring prefix "classpath*:"
}
// 绝对路径
if (absoluteLocation) {
try {
// 直接根据地址加载相应的配置文件
int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]");
}
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error(
"Failed to import bean definitions from URL location [" + location + "]", ele, ex);
}
}
else {
// 相对路径则根据相应的地址计算出绝对路径地址
try {
int importCount;
Resource relativeResource = getReaderContext().getResource().createRelative(location);
if (relativeResource.exists()) {
importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
actualResources.add(relativeResource);
}
else {
String baseLocation = getReaderContext().getResource().getURL().toString();
importCount = getReaderContext().getReader().loadBeanDefinitions(
StringUtils.applyRelativePath(baseLocation, location), actualResources);
}
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]");
}
}
catch (IOException ex) {
getReaderContext().error("Failed to resolve current resource location", ele, ex);
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]",
ele, ex);
}
}
// 解析成功后,进行监听器激活处理
Resource[] actResArray = actualResources.toArray(new Resource[0]);
getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
}
解析 import 过程较为清晰,整个过程如下:
- 获取 source 属性的值,该值表示资源的路径
- 解析路径中的系统属性,如”${user.dir}”
- 判断资源路径 location 是绝对路径还是相对路径
- 如果是绝对路径,则调递归调用 Bean 的解析过程,进行另一次的解析
- 如果是相对路径,则先计算出绝对路径得到 Resource,然后进行解析
- 通知监听器,完成解析
判断路径
方法通过以下方法来判断 location 是为相对路径还是绝对路径:
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
判断绝对路径的规则如下:
- 以 classpath*: 或者 classpath: 开头为绝对路径
- 能够通过该 location 构建出
java.net.URL为绝对路径 - 根据 location 构造
java.net.URI判断调用isAbsolute()判断是否为绝对路径
如果 location 为绝对路径则调用 loadBeanDefinitions(),该方法在 AbstractBeanDefinitionReader 中定义。
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int loadCount = loadBeanDefinitions(resources);
if (actualResources != null) {
for (Resource resource : resources) {
actualResources.add(resource);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
}
return loadCount;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int loadCount = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
}
return loadCount;
}
}
整个逻辑比较简单,首先获取 ResourceLoader,然后根据不同的 ResourceLoader 执行不同的逻辑,主要是可能存在多个 Resource,但是最终都会回归到 XmlBeanDefinitionReader.loadBeanDefinitions() ,所以这是一个递归的过程。
至此,import 标签解析完毕,整个过程比较清晰明了:获取 source 属性值,得到正确的资源路径,然后调用 loadBeanDefinitions() 方法进行递归的 BeanDefinition 加载。
通过beanName注册BeanDefinition
在spring中除了使用beanName作为key将BeanDefinition放入Map中还做了其他一些事情,我们看下方法registerBeanDefinition代码,BeanDefinitionRegistry是一个接口,他有三个实现类,DefaultListableBeanFactory、SimpleBeanDefinitionRegistry、GenericApplicationContext,其中SimpleBeanDefinitionRegistry非常简单,而GenericApplicationContext最终也是使用的DefaultListableBeanFactory中的实现方法,我们看下代码:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
// 校验 beanName 与 beanDefinition
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
// 校验 BeanDefinition
// 这是注册前的最后一次校验了,主要是对属性 methodOverrides 进行校验
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
// 从缓存中获取指定 beanName 的 BeanDefinition
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
/**
* 如果存在
*/
if (oldBeanDefinition != null) {
// 如果存在但是不允许覆盖,抛出异常
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
//
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (this.logger.isWarnEnabled()) {
this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
// 覆盖 beanDefinition 与 被覆盖的 beanDefinition 不是同类
else if (!beanDefinition.equals(oldBeanDefinition)) {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
// 允许覆盖,直接覆盖原有的 BeanDefinition
this.beanDefinitionMap.put(beanName, beanDefinition);
}
/**
* 不存在
*/
else {
// 检测创建 Bean 阶段是否已经开启,如果开启了则需要对 beanDefinitionMap 进行并发控制
if (hasBeanCreationStarted()) {
// beanDefinitionMap 为全局变量,避免并发情况
synchronized (this.beanDefinitionMap) {
//
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
// 不会存在并发情况,直接设置
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
// 重新设置 beanName 对应的缓存
resetBeanDefinition(beanName);
}
}
处理过程如下:
- 首先 BeanDefinition 进行校验,该校验也是注册过程中的最后一次校验了,主要是对 AbstractBeanDefinition 的 methodOverrides 属性进行校验
- 根据 beanName 从缓存中获取 BeanDefinition,如果缓存中存在,则根据 allowBeanDefinitionOverriding 标志来判断是否允许覆盖,如果允许则直接覆盖,否则抛出 BeanDefinitionStoreException 异常
- 若缓存中没有指定 beanName 的 BeanDefinition,则判断当前阶段是否已经开始了 Bean 的创建阶段(),如果是,则需要对 beanDefinitionMap 进行加锁控制并发问题,否则直接设置即可。对于
hasBeanCreationStarted()方法后续做详细介绍,这里不过多阐述。 - 若缓存中存在该 beanName 或者 单利 bean 集合中存在该 beanName,则调用
resetBeanDefinition()重置 BeanDefinition 缓存。
其实整段代码的核心就在于 this.beanDefinitionMap.put(beanName, beanDefinition); 。BeanDefinition 的缓存也不是神奇的东西,就是定义 一个 ConcurrentHashMap,key 为 beanName,value 为 BeanDefinition。
通过别名注册BeanDefinition
通过别名注册BeanDefinition最终是在SimpleAliasRegistry中实现的,我们看下代码:
public void registerAlias(String name, String alias) {
Assert.hasText(name, "'name' must not be empty");
Assert.hasText(alias, "'alias' must not be empty");
synchronized (this.aliasMap) {
if (alias.equals(name)) {
this.aliasMap.remove(alias);
}
else {
String registeredName = this.aliasMap.get(alias);
if (registeredName != null) {
if (registeredName.equals(name)) {
// An existing alias - no need to re-register
return;
}
if (!allowAliasOverriding()) {
throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" +
name + "': It is already registered for name '" + registeredName + "'.");
}
}
//当A->B存在时,若再次出现A->C->B时候则会抛出异常。
checkForAliasCircle(name, alias);
this.aliasMap.put(alias, name);
}
}
}
上述代码的流程总结如下: (1)alias与beanName相同情况处理,若alias与beanName并名称相同则不需要处理并删除原有的alias (2)alias覆盖处理。若aliasName已经使用并已经指向了另一beanName则需要用户的设置进行处理 (3)alias循环检查,当A->B存在时,若再次出现A->C->B时候则会抛出异常。
IOC 之 自定义标签解析
自定义标签的解析是通过BeanDefinitionParserDelegate.parseCustomElement(ele)进行的,我们进行详细分析。
自定义标签的解析过程
自定义标签解析用的是方法:parseCustomElement(Element ele, @Nullable BeanDefinition containingBd),源码如下:
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
// 获取 标签对应的命名空间
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
// 根据 命名空间找到相应的 NamespaceHandler
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
// 调用自定义的 Handler 处理
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
大概流程如下:
- 获取标签对应的命名空间
- 根据命名空间找到相应的 NamespaceHandler
- 调用自定义的 Handler 处理
标签的解析是从命名空间的提起开始的,至于如何提取对应元素的命名空间其实并不需要我们亲内去实现,在 org.w3c.dom.Node 中已经提供了方法供我们直接调用
String namespaceUri = getNamespaceURI(ele);
@Nullable
public String getNamespaceURI(Node node) {
return node.getNamespaceURI();
}
根据 namespaceUri 获取 Handler,这个映射关系我们在 Spring.handlers 中已经定义了,所以只需要找到该类,然后初始化返回,最后调用该 Handler 对象的 parse() 方法处理,该方法我们也提供了实现。所以上面的核心就在于怎么找到该 Handler 类。调用方法为:
this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri)
源码如下
public NamespaceHandler resolve(String namespaceUri) {
// 获取所有已经配置的 Handler 映射
Map<String, Object> handlerMappings = getHandlerMappings();
// 根据 namespaceUri 获取 handler的信息:这里一般都是类路径
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
else if (handlerOrClassName instanceof NamespaceHandler) {
// 如果已经做过解析,直接返回
return (NamespaceHandler) handlerOrClassName;
}
else {
String className = (String) handlerOrClassName;
try {
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
// 初始化类
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
// 调用 自定义NamespaceHandler 的init() 方法
namespaceHandler.init();
// 记录在缓存
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}
catch (ClassNotFoundException ex) {
throw new FatalBeanException("Could not find NamespaceHandler class [" + className +
"] for namespace [" + namespaceUri + "]", ex);
}
catch (LinkageError err) {
throw new FatalBeanException("Unresolvable class definition for NamespaceHandler class [" +
className + "] for namespace [" + namespaceUri + "]", err);
}
}
}
首先调用 getHandlerMappings() 获取所有配置文件中的映射关系 handlerMappings ,其实就是将映射关系放在一个 Map 结构的 parsers 对象中。就是我们在 Spring.handlers 文件中配置 命名空间与命名空间处理器的映射关系,该关系为 <命名空间,类路径>,
http\://www.springframework.org/schema/aop=org.springframework.aop.config.AopNamespaceHandler
然后根据命名空间 namespaceUri 从映射关系中获取相应的信息,如果为空或者已经初始化了就直接返回,否则根据反射对其进行初始化,同时调用其 init()方法,最后将该 Handler 对象缓存。例如AOP就是使用自定义标签实现的
package org.springframework.aop.config;
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
public class AopNamespaceHandler extends NamespaceHandlerSupport {
public AopNamespaceHandler() {
}
public void init() {
this.registerBeanDefinitionParser("config", new ConfigBeanDefinitionParser());
this.registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser());
this.registerBeanDefinitionDecorator("scoped-proxy", new ScopedProxyBeanDefinitionDecorator());
this.registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
}
}
当得到自定义命名空间处理后会马上执行 namespaceHandler.init() 来进行自定义 BeanDefinitionParser的注册。
得到了解析器和分析的元素后,Spring就可以将解析工作委托给自定义解析器去解析了,对于标签的解析使用的是:NamespaceHandler.parse(ele, new ParserContext(this.readerContext, this, containingBd))方法,进入到方法体内:
class AspectJAutoProxyBeanDefinitionParser implements BeanDefinitionParser {
AspectJAutoProxyBeanDefinitionParser() {
}
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
AopNamespaceUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(parserContext, element);
this.extendBeanDefinition(element, parserContext);
return null;
}
private void extendBeanDefinition(Element element, ParserContext parserContext) {
BeanDefinition beanDef = parserContext.getRegistry().getBeanDefinition("org.springframework.aop.config.internalAutoProxyCreator");
if (element.hasChildNodes()) {
this.addIncludePatterns(element, parserContext, beanDef);
}
}
private void addIncludePatterns(Element element, ParserContext parserContext, BeanDefinition beanDef) {
ManagedList<TypedStringValue> includePatterns = new ManagedList();
NodeList childNodes = element.getChildNodes();
for(int i = 0; i < childNodes.getLength(); ++i) {
Node node = childNodes.item(i);
if (node instanceof Element) {
Element includeElement = (Element)node;
TypedStringValue valueHolder = new TypedStringValue(includeElement.getAttribute("name"));
valueHolder.setSource(parserContext.extractSource(includeElement));
includePatterns.add(valueHolder);
}
}
if (!includePatterns.isEmpty()) {
includePatterns.setSource(parserContext.extractSource(element));
beanDef.getPropertyValues().add("includePatterns", includePatterns);
}
}
}
调用 findParserForElement() 方法获取 BeanDefinitionParser 实例,其实就是获取在 init() 方法里面注册的实例对象。接下来我们看看 parser.parse (element, parserContext),该方法在 AbstractBeanDefinitionParser 中实现:
public final BeanDefinition parse(Element element, ParserContext parserContext) {
AbstractBeanDefinition definition = parseInternal(element, parserContext);
if (definition != null && !parserContext.isNested()) {
try {
String id = resolveId(element, definition, parserContext);
if (!StringUtils.hasText(id)) {
parserContext.getReaderContext().error(
"Id is required for element '" + parserContext.getDelegate().getLocalName(element)
+ "' when used as a top-level tag", element);
}
String[] aliases = null;
if (shouldParseNameAsAliases()) {
String name = element.getAttribute(NAME_ATTRIBUTE);
if (StringUtils.hasLength(name)) {
aliases = StringUtils.trimArrayElements(StringUtils.commaDelimitedListToStringArray(name));
}
}
BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases);
//将 AbstractBeanDefinition 转换为 BeanDefinitionHolder 并注册
registerBeanDefinition(holder, parserContext.getRegistry());
if (shouldFireEvents()) {
BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder);
postProcessComponentDefinition(componentDefinition);
parserContext.registerComponent(componentDefinition);
}
}
catch (BeanDefinitionStoreException ex) {
String msg = ex.getMessage();
parserContext.getReaderContext().error((msg != null ? msg : ex.toString()), element);
return null;
}
}
return definition;
}
自定义标签的解析整个过程:首先会加载 handlers 文件,将其中内容进行一个解析,形成 <namespaceUri,类路径> 这样的一个映射,然后根据获取的 namespaceUri 就可以得到相应的类路径,对其进行初始化等到相应的 Handler 对象,调用 parse() 方法,在该方法中根据标签的 localName 得到相应的 BeanDefinitionParser 实例对象,调用 parse() ,该方法定义在 AbstractBeanDefinitionParser 抽象类中,核心逻辑封装在其 parseInternal() 中,该方法返回一个 AbstractBeanDefinition 实例对象,其主要是在 AbstractSingleBeanDefinitionParser 中实现,对于自定义的 Parser 类,其需要实现 getBeanClass() 或者 getBeanClassName() 和 doParse()。最后将 AbstractBeanDefinition 转换为 BeanDefinitionHolder 并注册。
IOC 之开启bean的加载
当我们显示或者隐式地调用 getBean() 时,则会触发加载 bean 阶段。如下:
HeloWorld helloWorld =(HeloWorld)beanFactory.getBean("helloWorld");
获取bean
接下来我们回到加载bean的阶段,当我们显示或者隐式地调用 getBean() 时,则会触发加载 bean 阶段。如下:
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
内部调用 doGetBean() 方法,这个方法的代码比较长,各位耐心看下:
@SuppressWarnings("unchecked")
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
//获取 beanName,这里是一个转换动作,将 name 转换为 beanName
final String beanName = transformedBeanName(name);
Object bean;
/*
*检查缓存中的实例工程是否存在对应的实例
*为何要优先使用这段代码呢?
*因为在创建单例bean的时候会存在依赖注入的情况,而在创建依赖的时候为了避免循环依赖
*spring创建bean的原则是在不等bean创建完就会将创建bean的objectFactory提前曝光,即将其加入到缓存中,一旦下个bean创建时依赖上个bean则直接使用objectFactory
*直接从缓存中或singletonFactories中获取objectFactory
*就算没有循环依赖,只是单纯的依赖注入,如B依赖A,如果A已经初始化完成,B进行初始化时,需要递归调用getBean获取A,这是A已经在缓存里了,直接可以从这里取到
*/
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
if (logger.isDebugEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.debug("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.debug("Returning cached instance of singleton bean '" + beanName + "'");
}
}
//返回对应的实例,有些时候并不是直接返回实例,而是返回某些方法返回的实例
//这里涉及到我们上面讲的FactoryBean,如果此Bean是FactoryBean的实现类,如果name前缀为"&",则直接返回此实现类的bean,如果没有前缀"&",则需要调用此实现类的getObject方法,返回getObject里面真是的返回对象
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
//只有在单例的情况下才会解决循环依赖
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
//尝试从parentBeanFactory中查找bean
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// Not found -> check parent.
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
// Delegation to parent with explicit args.
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
}
//如果不是仅仅做类型检查,则这里需要创建bean,并做记录
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
//将存储XML配置文件的GenericBeanDefinition转换为RootBeanDefinition,同时如果存在父bean的话则合并父bean的相关属性
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
//如果存在依赖则需要递归实例化依赖的bean
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
registerDependentBean(dep, beanName);
try {
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 单例模式
// 实例化依赖的bean后对bean本身进行实例化
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 原型模式
else if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
// 从指定的 scope 下创建 bean
else {
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
Object scopedInstance = scope.get(beanName, () -> {
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
});
bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName,
"Scope '" + scopeName + "' is not active for the current thread; consider " +
"defining a scoped proxy for this bean if you intend to refer to it from a singleton",
ex);
}
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// Check if required type matches the type of the actual bean instance.
if (requiredType != null && !requiredType.isInstance(bean)) {
try {
T convertedBean = getTypeConverter().convertIfNecessary(bean, requiredType);
if (convertedBean == null) {
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
return convertedBean;
}
catch (TypeMismatchException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to convert bean '" + name + "' to required type '" +
ClassUtils.getQualifiedName(requiredType) + "'", ex);
}
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
}
return (T) bean;
}
代码是相当长,处理逻辑也是相当复杂,下面将其进行拆分讲解。
获取 beanName
final String beanName = transformedBeanName(name);
这里传递的是 name,不一定就是 beanName,可能是 aliasName,也有可能是 FactoryBean(带“&”前缀),所以这里需要调用 transformedBeanName() 方法对 name 进行一番转换,主要如下:
protected String transformedBeanName(String name) {
return canonicalName(BeanFactoryUtils.transformedBeanName(name));
}
// 去除 FactoryBean 的修饰符
public static String transformedBeanName(String name) {
Assert.notNull(name, "'name' must not be null");
String beanName = name;
while (beanName.startsWith(BeanFactory.FACTORY_BEAN_PREFIX)) {
beanName = beanName.substring(BeanFactory.FACTORY_BEAN_PREFIX.length());
}
return beanName;
}
// 转换 aliasName
public String canonicalName(String name) {
String canonicalName = name;
// Handle aliasing...
String resolvedName;
do {
resolvedName = this.aliasMap.get(canonicalName);
if (resolvedName != null) {
canonicalName = resolvedName;
}
}
while (resolvedName != null);
return canonicalName;
}
主要处理过程包括两步:
- 去除 FactoryBean 的修饰符。如果 name 以 “&” 为前缀,那么会去掉该 “&”,例如,
name = "&studentService",则会是name = "studentService"。 - 取指定的 alias 所表示的最终 beanName。主要是一个循环获取 beanName 的过程,例如别名 A 指向名称为 B 的 bean 则返回 B,若 别名 A 指向别名 B,别名 B 指向名称为 C 的 bean,则返回 C。
缓存中获取单例bean
单例在Spring的同一个容器内只会被创建一次,后续再获取bean直接从单例缓存中获取,当然这里也只是尝试加载,首先尝试从缓存中加载,然后再次尝试从singletonFactory加载因为在创建单例bean的时候会存在依赖注入的情况,而在创建依赖的时候为了避免循环依赖,Spring创建bean的原则不等bean创建完成就会创建bean的ObjectFactory提早曝光加入到缓存中,一旦下一个bean创建时需要依赖上个bean,则直接使用ObjectFactory;就算没有循环依赖,只是单纯的依赖注入,如B依赖A,如果A已经初始化完成,B进行初始化时,需要递归调用getBean获取A,这是A已经在缓存里了,直接可以从这里取到。接下来我们看下获取单例bean的方法getSingleton(beanName),进入方法体:
@Override
@Nullable
public Object getSingleton(String beanName) {
//参数true是允许早期依赖
return getSingleton(beanName, true);
}
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//检查缓存中是否存在实例,这里就是上面说的单纯的依赖注入,如B依赖A,如果A已经初始化完成,B进行初始化时,需要递归调用getBean获取A,这是A已经在缓存里了,直接可以从这里取到
Object singletonObject = this.singletonObjects.get(beanName);
//如果缓存为空且单例bean正在创建中,则锁定全局变量,为什么要判断bean在创建中呢?这里就是可以判断是否循环依赖了。
//A依赖B,B也依赖A,A实例化的时候,发现依赖B,则递归去实例化B,B发现依赖A,则递归实例化A,此时会走到原点A的实例化,第一次A的实例化还没完成,只不过把实例化的对象加入到缓存中,但是状态还是正在创建中,由此回到原点发现A正在创建中,由此可以判断是循环依赖了
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//如果此bean正在加载,则不处理
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//当某些方法需要提前初始化的时候会直接调用addSingletonFactory把对应的ObjectFactory初始化策略存储在singletonFactory中
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//使用预先设定的getObject方法
singletonObject = singletonFactory.getObject();
记录在缓存中,注意earlySingletonObjects和singletonFactories是互斥的
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
接下来我们根据源码再来梳理下这个方法,这样更易于理解,这个方法先尝试从singletonObjects里面获取实例,如果如果获取不到再从earlySingletonObjects里面获取,如果还获取不到,再尝试从singletonFactories里面获取beanName对应的ObjectFactory,然后再调用这个ObjectFactory的getObject方法创建bean,并放到earlySingletonObjects里面去,并且从singletonFactoryes里面remove调这个ObjectFactory,而对于后续所有的内存操作都只为了循环依赖检测时候使用,即allowEarlyReference为true的时候才会使用。 这里涉及到很多个存储bean的不同map,简单解释下: singletonObjects:用于保存BeanName和创建bean实例之间的关系,beanName–>bean Instance singletonFactories:用于保存BeanName和创建bean的工厂之间的关系,banName–>ObjectFactory earlySingletonObjects:也是保存BeanName和创建bean实例之间的关系,与singletonObjects的不同之处在于,当一个单例bean被放到这里面后,那么当bean还在创建过程中,就可以通过getBean方法获取到了,其目的是用来检测循环引用。 registeredSingletons:用来保存当前所有已注册的bean.
从bean的实例中获取对象
获取到bean以后就要获取实例对象了,这里用到的是getObjectForBeanInstance方法。getObjectForBeanInstance是个频繁使用的方法,无论是从缓存中获得bean还是根据不同的scope策略加载bean.总之,我们得到bean的实例后,要做的第一步就是调用这个方法来检测一下正确性,其实就是检测获得Bean是不是FactoryBean类型的bean,如果是,那么需要调用该bean对应的FactoryBean实例中的getObject()作为返回值。接下来我们看下此方法的源码:
protected Object getObjectForBeanInstance(
Object beanInstance, String name, String beanName, @Nullable RootBeanDefinition mbd) {
//如果指定的name是工厂相关的(以&开头的)
if (BeanFactoryUtils.isFactoryDereference(name)) {
//如果是NullBean则直接返回此bean
if (beanInstance instanceof NullBean) {
return beanInstance;
}
//如果不是FactoryBean类型,则验证不通过抛出异常
if (!(beanInstance instanceof FactoryBean)) {
throw new BeanIsNotAFactoryException(transformedBeanName(name), beanInstance.getClass());
}
}
// Now we have the bean instance, which may be a normal bean or a FactoryBean.
// If it's a FactoryBean, we use it to create a bean instance, unless the
// caller actually wants a reference to the factory.
//如果获取的beanInstance不是FactoryBean类型,则说明是普通的Bean,可直接返回
//如果获取的beanInstance是FactoryBean类型,但是是以(以&开头的),也直接返回,此时返回的是FactoryBean的实例
if (!(beanInstance instanceof FactoryBean) || BeanFactoryUtils.isFactoryDereference(name)) {
return beanInstance;
}
Object object = null;
if (mbd == null) {
object = getCachedObjectForFactoryBean(beanName);
}
if (object == null) {
// Return bean instance from factory.
FactoryBean<?> factory = (FactoryBean<?>) beanInstance;
// Caches object obtained from FactoryBean if it is a singleton.
if (mbd == null && containsBeanDefinition(beanName)) {
mbd = getMergedLocalBeanDefinition(beanName);
}
boolean synthetic = (mbd != null && mbd.isSynthetic());
//到了这里说明获取的beanInstance是FactoryBean类型,但没有以"&"开头,此时就要返回factory内部getObject里面的对象了
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}
return object;
}
接着我们来看看真正的核心功能getObjectFromFactoryBean(factory, beanName, !synthetic)方法中实现的,继续跟进代码:
protected Object getObjectFromFactoryBean(FactoryBean<?> factory, String beanName, boolean shouldPostProcess) {
// 为单例模式且缓存中存在
if (factory.isSingleton() && containsSingleton(beanName)) {
synchronized (getSingletonMutex()) {
// 从缓存中获取指定的 factoryBean
Object object = this.factoryBeanObjectCache.get(beanName);
if (object == null) {
// 为空,则从 FactoryBean 中获取对象
object = doGetObjectFromFactoryBean(factory, beanName);
// 从缓存中获取
Object alreadyThere = this.factoryBeanObjectCache.get(beanName);
if (alreadyThere != null) {
object = alreadyThere;
}
else {
// 需要后续处理
if (shouldPostProcess) {
// 若该 bean 处于创建中,则返回非处理对象,而不是存储它
if (isSingletonCurrentlyInCreation(beanName)) {
return object;
}
// 前置处理
beforeSingletonCreation(beanName);
try {
// 对从 FactoryBean 获取的对象进行后处理
// 生成的对象将暴露给bean引用
object = postProcessObjectFromFactoryBean(object, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName,
"Post-processing of FactoryBean's singleton object failed", ex);
}
finally {
// 后置处理
afterSingletonCreation(beanName);
}
}
// 缓存
if (containsSingleton(beanName)) {
this.factoryBeanObjectCache.put(beanName, object);
}
}
}
return object;
}
}
else {
// 非单例
Object object = doGetObjectFromFactoryBean(factory, beanName);
if (shouldPostProcess) {
try {
object = postProcessObjectFromFactoryBean(object, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Post-processing of FactoryBean's object failed", ex);
}
}
return object;
}
}
该方法应该就是创建 bean 实例对象中的核心方法之一了。这里我们关注三个方法:beforeSingletonCreation() 、 afterSingletonCreation() 、 postProcessObjectFromFactoryBean()。可能有小伙伴觉得前面两个方法不是很重要,LZ 可以肯定告诉你,这两方法是非常重要的操作,因为他们记录着 bean 的加载状态,是检测当前 bean 是否处于创建中的关键之处,对解决 bean 循环依赖起着关键作用。before 方法用于标志当前 bean 处于创建中,after 则是移除。其实在这篇博客刚刚开始就已经提到了 isSingletonCurrentlyInCreation() 是用于检测当前 bean 是否处于创建之中,如下:
public boolean isSingletonCurrentlyInCreation(String beanName) {
return this.singletonsCurrentlyInCreation.contains(beanName);
}
是根据 singletonsCurrentlyInCreation 集合中是否包含了 beanName,集合的元素则一定是在 beforeSingletonCreation() 中添加的,如下:
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
afterSingletonCreation() 为移除,则一定就是对 singletonsCurrentlyInCreation 集合 remove 了,如下:
protected void afterSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.remove(beanName)) {
throw new IllegalStateException("Singleton '" + beanName + "' isn't currently in creation");
}
}
我们再来看看真正的核心方法 doGetObjectFromFactoryBean
private Object doGetObjectFromFactoryBean(final FactoryBean<?> factory, final String beanName)
throws BeanCreationException {
Object object;
try {
if (System.getSecurityManager() != null) {
AccessControlContext acc = getAccessControlContext();
try {
object = AccessController.doPrivileged((PrivilegedExceptionAction<Object>) factory::getObject, acc);
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
object = factory.getObject();
}
}
catch (FactoryBeanNotInitializedException ex) {
throw new BeanCurrentlyInCreationException(beanName, ex.toString());
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "FactoryBean threw exception on object creation", ex);
}
// Do not accept a null value for a FactoryBean that's not fully
// initialized yet: Many FactoryBeans just return null then.
if (object == null) {
if (isSingletonCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(
beanName, "FactoryBean which is currently in creation returned null from getObject");
}
object = new NullBean();
}
return object;
}
以前我们曾经介绍过FactoryBean的调用方法,如果bean声明为FactoryBean类型,则当提取bean时候提取的不是FactoryBean,而是FactoryBean中对应的getObject方法返回的bean,而doGetObjectFromFactoryBean真是实现这个功能。
而调用完doGetObjectFromFactoryBean方法后,并没有直接返回,getObjectFromFactoryBean方法中还调用了object = postProcessObjectFromFactoryBean(object, beanName);方法,在子类AbstractAutowireCapableBeanFactory,有这个方法的实现:
@Override
protected Object postProcessObjectFromFactoryBean(Object object, String beanName) {
return applyBeanPostProcessorsAfterInitialization(object, beanName);
}
@Override
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
Object current = beanProcessor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
对于后处理器的使用,我们目前还没接触,后续会有大量篇幅介绍,这里我们只需要了解在Spring获取bean的规则中有这样一条:尽可能保证所有bean初始化后都会调用注册的BeanPostProcessor的postProcessAfterInitialization方法进行处理,在实际开发过程中大可以针对此特性设计自己的业务处理。
详细分析
BeanFactory
BeanFactory,以Factory结尾,表示它是一个工厂类(接口), 它负责生产和管理bean的一个工厂。在Spring中,BeanFactory是IOC容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。BeanFactory只是个接口,并不是IOC容器的具体实现,但是Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,其中XmlBeanFactory就是常用的一个,该实现将以XML方式描述组成应用的对象及对象间的依赖关系。XmlBeanFactory类将持有此XML配置元数据,并用它来构建一个完全可配置的系统或应用。
BeanFactory是Spring IOC容器的鼻祖,是IOC容器的基础接口,所有的容器都是从它这里继承实现而来。可见其地位。BeanFactory提供了最基本的IOC容器的功能,即所有的容器至少需要实现的标准。
XmlBeanFactory,只是提供了最基本的IOC容器的功能。而且XMLBeanFactory,继承自DefaultListableBeanFactory。DefaultListableBeanFactory实际包含了基本IOC容器所具有的所有重要功能,是一个完整的IOC容器。
ApplicationContext包含BeanFactory的所有功能,通常建议比BeanFactory优先。 BeanFactory体系结构是典型的工厂方法模式,即什么样的工厂生产什么样的产品。BeanFactory是最基本的抽象工厂,而其他的IOC容器只不过是具体的工厂,对应着各自的Bean定义方法。但同时,其他容器也针对具体场景不同,进行了扩充,提供具体的服务。 如下:
Resource resource = new FileSystemResource("beans.xml");
BeanFactory factory = new XmlBeanFactory(resource);
ClassPathResource resource = new ClassPathResource("beans.xml");
BeanFactory factory = new XmlBeanFactory(resource);
ApplicationContext context = new ClassPathXmlApplicationContext(new String[] {"applicationContext.xml"});
BeanFactory factory = (BeanFactory) context;
基本就是这些了,接着使用getBean(String beanName)方法就可以取得bean的实例;BeanFactory提供的方法及其简单,仅提供了六种方法供客户调用:
- boolean containsBean(String beanName) 判断工厂中是否包含给定名称的bean定义,若有则返回true
- Object getBean(String) 返回给定名称注册的bean实例。根据bean的配置情况,如果是singleton模式将返回一个共享实例,否则将返回一个新建的实例,如果没有找到指定bean,该方法可能会抛出异常
- Object getBean(String, Class) 返回以给定名称注册的bean实例,并转换为给定class类型
- Class getType(String name) 返回给定名称的bean的Class,如果没有找到指定的bean实例,则排除NoSuchBeanDefinitionException异常
- boolean isSingleton(String) 判断给定名称的bean定义是否为单例模式
- String[] getAliases(String name) 返回给定bean名称的所有别名
/**
* The root interface for accessing a Spring bean container.
*
* <p>This is the basic client view of a bean container;
* further interfaces such as {@link ListableBeanFactory} and
* {@link org.springframework.beans.factory.config.ConfigurableBeanFactory}
* are available for specific purposes.
*
* <p>This interface is implemented by objects that hold a number of bean definitions,
* each uniquely identified by a String name. Depending on the bean definition,
* the factory will return either an independent instance of a contained object
* (the Prototype design pattern), or a single shared instance (a superior
* alternative to the Singleton design pattern, in which the instance is a
* singleton in the scope of the factory). Which type of instance will be returned
* depends on the bean factory configuration: the API is the same. Since Spring
* 2.0, further scopes are available depending on the concrete application
* context (e.g. "request" and "session" scopes in a web environment).
*
* <p>The point of this approach is that the BeanFactory is a central registry
* of application components, and centralizes configuration of application
* components (no more do individual objects need to read properties files,
* for example). See chapters 4 and 11 of "Expert One-on-One J2EE Design and
* Development" for a discussion of the benefits of this approach.
*
* <p>Note that it is generally better to rely on Dependency Injection
* ("push" configuration) to configure application objects through setters
* or constructors, rather than use any form of "pull" configuration like a
* BeanFactory lookup. Spring's Dependency Injection functionality is
* implemented using this BeanFactory interface and its subinterfaces.
*
* <p>Normally a BeanFactory will load bean definitions stored in a configuration
* source (such as an XML document), and use the {@code org.springframework.beans}
* package to configure the beans. However, an implementation could simply return
* Java objects it creates as necessary directly in Java code. There are no
* constraints on how the definitions could be stored: LDAP, RDBMS, XML,
* properties file, etc. Implementations are encouraged to support references
* amongst beans (Dependency Injection).
*
* <p>In contrast to the methods in {@link ListableBeanFactory}, all of the
* operations in this interface will also check parent factories if this is a
* {@link HierarchicalBeanFactory}. If a bean is not found in this factory instance,
* the immediate parent factory will be asked. Beans in this factory instance
* are supposed to override beans of the same name in any parent factory.
*
* <p>Bean factory implementations should support the standard bean lifecycle interfaces
* as far as possible. The full set of initialization methods and their standard order is:
* <ol>
* <li>BeanNameAware's {@code setBeanName}
* <li>BeanClassLoaderAware's {@code setBeanClassLoader}
* <li>BeanFactoryAware's {@code setBeanFactory}
* <li>EnvironmentAware's {@code setEnvironment}
* <li>EmbeddedValueResolverAware's {@code setEmbeddedValueResolver}
* <li>ResourceLoaderAware's {@code setResourceLoader}
* (only applicable when running in an application context)
* <li>ApplicationEventPublisherAware's {@code setApplicationEventPublisher}
* (only applicable when running in an application context)
* <li>MessageSourceAware's {@code setMessageSource}
* (only applicable when running in an application context)
* <li>ApplicationContextAware's {@code setApplicationContext}
* (only applicable when running in an application context)
* <li>ServletContextAware's {@code setServletContext}
* (only applicable when running in a web application context)
* <li>{@code postProcessBeforeInitialization} methods of BeanPostProcessors
* <li>InitializingBean's {@code afterPropertiesSet}
* <li>a custom {@code init-method} definition
* <li>{@code postProcessAfterInitialization} methods of BeanPostProcessors
* </ol>
*
* <p>On shutdown of a bean factory, the following lifecycle methods apply:
* <ol>
* <li>{@code postProcessBeforeDestruction} methods of DestructionAwareBeanPostProcessors
* <li>DisposableBean's {@code destroy}
* <li>a custom {@code destroy-method} definition
* </ol>
*
* @author Rod Johnson
* @author Juergen Hoeller
* @author Chris Beams
* @since 13 April 2001
* @see BeanNameAware#setBeanName
* @see BeanClassLoaderAware#setBeanClassLoader
* @see BeanFactoryAware#setBeanFactory
* @see org.springframework.context.EnvironmentAware#setEnvironment
* @see org.springframework.context.EmbeddedValueResolverAware#setEmbeddedValueResolver
* @see org.springframework.context.ResourceLoaderAware#setResourceLoader
* @see org.springframework.context.ApplicationEventPublisherAware#setApplicationEventPublisher
* @see org.springframework.context.MessageSourceAware#setMessageSource
* @see org.springframework.context.ApplicationContextAware#setApplicationContext
* @see org.springframework.web.context.ServletContextAware#setServletContext
* @see org.springframework.beans.factory.config.BeanPostProcessor#postProcessBeforeInitialization
* @see InitializingBean#afterPropertiesSet
* @see org.springframework.beans.factory.support.RootBeanDefinition#getInitMethodName
* @see org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization
* @see org.springframework.beans.factory.config.DestructionAwareBeanPostProcessor#postProcessBeforeDestruction
* @see DisposableBean#destroy
* @see org.springframework.beans.factory.support.RootBeanDefinition#getDestroyMethodName
*/
package org.springframework.beans.factory;
import org.springframework.beans.BeansException;
public interface BeanFactory {
String FACTORY_BEAN_PREFIX = "&";
Object getBean(String name) throws BeansException;
<T> T getBean(String name, Class<T> requiredType) throws BeansException;
<T> T getBean(Class<T> requiredType) throws BeansException;
Object getBean(String name, Object... args) throws BeansException;
boolean containsBean(String name);
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String name, Class<?> targetType) throws NoSuchBeanDefinitionException;
Class<?> getType(String name) throws NoSuchBeanDefinitionException;
String[] getAliases(String name);
}
FactoryBean
**一般情况下,Spring通过反射机制利用
以Bean结尾,表示它是一个Bean,不同于普通Bean的是:**它是实现了FactoryBean
package org.springframework.beans.factory;
public interface FactoryBean<T> {
T getObject() throws Exception;
Class<?> getObjectType();
boolean isSingleton();
}
在该接口中还定义了以下3个方法:
- T getObject():返回由FactoryBean创建的Bean实例,如果isSingleton()返回true,则该实例会放到Spring容器中单实例缓存池中;
- boolean isSingleton():返回由FactoryBean创建的Bean实例的作用域是singleton还是prototype;
- **Class
getObjectType()**:返回FactoryBean创建的Bean类型。
当配置文件中
public class Car {
private int maxSpeed ;
private String brand ;
private double price ;
//get//set 方法
}
如果用FactoryBean的方式实现就灵活点,下例通过逗号分割符的方式一次性的为Car的所有属性指定配置值:
import org.springframework.beans.factory.FactoryBean;
public class CarFactoryBean implements FactoryBean<Car> {
private String carInfo ;
public Car getObject() throws Exception {
Car car = new Car();
String[] infos = carInfo.split(",");
car.setBrand(infos[0]);
car.setMaxSpeed(Integer.valueOf(infos[1]));
car.setPrice(Double.valueOf(infos[2]));
return car;
}
public Class<Car> getObjectType(){
return Car.class ;
}
public boolean isSingleton(){
return false ;
}
public String getCarInfo(){
return this.carInfo;
}
//接受逗号分割符设置属性信息
public void setCarInfo (String carInfo){
this.carInfo = carInfo;
}
}
有了这个CarFactoryBean后,就可以在配置文件中使用下面这种自定义的配置方式配置CarBean了:
<bean d="car"class="com.demo.spring.CarFactoryBean" P:carInfo="大奔,600,1000000"/>
当调用getBean(“car”)时,Spring通过反射机制发现CarFactoryBean实现了FactoryBean的接口,这时Spring容器就调用接口方法CarFactoryBean#getObject()方法返回。如果希望获取CarFactoryBean的实例,则需要在使用getBean(beanName)方法时在beanName前显示的加上”&”前缀:如getBean(“&car”);
IOC 之 bean 创建
在 Spring 中存在着不同的 scope,默认是 singleton ,还有 prototype、request 等等其他的 scope,他们的初始化步骤是怎样的呢?最重要的方法,是 createBean(),也就是核心创建bean的过程,下面我们来具体看看。
准备创建bean
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
如上所示,createBean是真正创建bean的地方,此方法是定义在AbstractAutowireCapableBeanFactory中,我们看下其源码:
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
if (logger.isDebugEnabled()) {
logger.debug("Creating instance of bean '" + beanName + "'");
}
RootBeanDefinition mbdToUse = mbd;
// 确保此时的 bean 已经被解析了
// 如果获取的class 属性不为null,则克隆该 BeanDefinition
// 主要是因为该动态解析的 class 无法保存到到共享的 BeanDefinition
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
try {
// 验证和准备覆盖方法
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// 给 BeanPostProcessors 一个机会用来返回一个代理类而不是真正的类实例
// AOP 的功能就是基于这个地方
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
try {
// 执行真正创建 bean 的过程
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex);
}
}
实例化的前置处理
resolveBeforeInstantiation() 的作用是给 BeanPostProcessors 后置处理器返回一个代理对象的机会,其实在调用该方法之前 Spring 一直都没有创建 bean ,那么这里返回一个 bean 的代理类有什么作用呢?作用体现在后面的 if 判断:
if (bean != null) {
return bean;
}
如果代理对象不为空,则直接返回代理对象,这一步骤有非常重要的作用,Spring 后续实现 AOP 就是基于这个地方判断的。
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class<?> targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}
这个方法核心就在于 applyBeanPostProcessorsBeforeInstantiation() 和 applyBeanPostProcessorsAfterInitialization() 两个方法,before 为实例化前的后处理器应用,after 为实例化后的后处理器应用,由于本文的主题是创建 bean,关于 Bean 的增强处理后续 LZ 会单独出博文来做详细说明。
创建 bean
如果没有代理对象,就只能走常规的路线进行 bean 的创建了,该过程有 doCreateBean() 实现,如下:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// BeanWrapper是对Bean的包装,其接口中所定义的功能很简单包括设置获取被包装的对象,获取被包装bean的属性描述器
BeanWrapper instanceWrapper = null;
// 单例模型,则从未完成的 FactoryBean 缓存中删除
if (mbd.isSingleton()) {anceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
// 使用合适的实例化策略来创建新的实例:工厂方法、构造函数自动注入、简单初始化
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 包装的实例对象
final Object bean = instanceWrapper.getWrappedInstance();
// 包装的实例对象的类型
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// 检测是否有后置处理
// 如果有后置处理,则允许后置处理修改 BeanDefinition
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
// applyMergedBeanDefinitionPostProcessors
// 后置处理修改 BeanDefinition
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// 解决单例模式的循环依赖
// 单例模式 & 允许循环依赖&当前单例 bean 是否正在被创建
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 提前将创建的 bean 实例加入到ObjectFactory 中
// 这里是为了后期避免循环依赖
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
/*
* 开始初始化 bean 实例对象
*/
Object exposedObject = bean;
try {
// 对 bean 进行填充,将各个属性值注入,其中,可能存在依赖于其他 bean 的属性
// 则会递归初始依赖 bean
populateBean(beanName, mbd, instanceWrapper);
// 调用初始化方法,比如 init-method
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
/**
* 循环依赖处理
*/
if (earlySingletonExposure) {
// 获取 earlySingletonReference
Object earlySingletonReference = getSingleton(beanName, false);
// 只有在存在循环依赖的情况下,earlySingletonReference 才不会为空
if (earlySingletonReference != null) {
// 如果 exposedObject 没有在初始化方法中被改变,也就是没有被增强
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
// 处理依赖
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
try {
// 注册 bean
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
大概流程如下:
createBeanInstance()实例化 beanpopulateBean()属性填充- 循环依赖的处理
initializeBean()初始化 bean
详细
singleton
Spring 的 scope 默认为 singleton,第一部分分析了从缓存中获取单例模式的 bean,但是如果缓存中不存在呢?则需要从头开始加载 bean,这个过程由 getSingleton() 实现。其初始化的代码如下:
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
这里我们看到了 java8的新特性lambda表达式 () -> , getSingleton方法的第二个参数为 ObjectFactory<?> singletonFactory,() ->相当于创建了一个ObjectFactory类型的匿名内部类,去实现ObjectFactory接口中的getObject()方法,其中{}中的代码相当于写在匿名内部类中getObject()的代码片段,等着getSingleton方法里面通过ObjectFactory<?> singletonFactory去显示调用,如singletonFactory.getObject()。上述代码可以反推成如下代码:
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() {
try {
return createBean(beanName, mbd, args);
} catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
下面我们进入到 getSingleton方法中
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
// 全局加锁
synchronized (this.singletonObjects) {
// 从缓存中检查一遍
// 因为 singleton 模式其实就是复用已经创建的 bean 所以这步骤必须检查
Object singletonObject = this.singletonObjects.get(beanName);
// 为空,开始加载过程
if (singletonObject == null) {
// 省略 部分代码
// 加载前置处理
beforeSingletonCreation(beanName);
boolean newSingleton = false;
// 省略代码
try {
// 初始化 bean
// 这个过程就是我上面讲的调用匿名内部类的方法,其实是调用 createBean() 方法
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// 省略 catch 部分
}
finally {
// 后置处理
afterSingletonCreation(beanName);
}
// 加入缓存中
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
// 直接返回
return singletonObject;
}
}
上述代码中其实,使用了回调方法,使得程序可以在单例创建的前后做一些准备及处理操作,而真正获取单例bean的方法其实并不是在此方法中实现的,其实现逻辑是在ObjectFactory类型的实例singletonFactory中实现的(即上图贴上的第一段代码)。而这些准备及处理操作包括如下内容。
(1)检查缓存是否已经加载过
(2)如果没有加载,则记录beanName的正在加载状态
(3)加载单例前记录加载状态。 可能你会觉得beforeSingletonCreation方法是个空实现,里面没有任何逻辑,但其实这个函数中做了一个很重要的操作:记录加载状态,也就是通过this.singletonsCurrentlyInCreation.add(beanName)将当前正要创建的bean记录在缓存中,这样便可以对循环依赖进行检测。 我们上一篇文章已经讲过,可以去看看。
(4)通过调用参数传入的ObjectFactory的个体Object方法实例化bean.
(5)加载单例后的处理方法调用。 同步骤3的记录加载状态相似,当bean加载结束后需要移除缓存中对该bean的正在加载状态的记录。
(6)将结果记录至缓存并删除加载bean过程中所记录的各种辅助状态。
(7)返回处理结果
我们看另外一个方法 addSingleton()。
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
一个 put、一个 add、两个 remove。singletonObjects 单例 bean 的缓存,singletonFactories 单例 bean Factory 的缓存,earlySingletonObjects “早期”创建的单例 bean 的缓存,registeredSingletons 已经注册的单例缓存。
加载了单例 bean 后,调用 getObjectForBeanInstance() 从 bean 实例中获取对象。该方法我们在上一篇中已经讲过。
原型模式
else if (mbd.isPrototype()) {
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
原型模式的初始化过程很简单:直接创建一个新的实例就可以了。过程如下:
- 调用
beforeSingletonCreation()记录加载原型模式 bean 之前的加载状态,即前置处理。 - 调用
createBean()创建一个 bean 实例对象。 - 调用
afterSingletonCreation()进行加载原型模式 bean 后的后置处理。 - 调用
getObjectForBeanInstance()从 bean 实例中获取对象。
其他作用域
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
Object scopedInstance = scope.get(beanName, () -> {
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
});
bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName,
"Scope '" + scopeName + "' is not active for the current thread; consider " +
"defining a scoped proxy for this bean if you intend to refer to it from a singleton",
ex);
}
核心流程和原型模式一样,只不过获取 bean 实例是由 scope.get() 实现,如下:
public Object get(String name, ObjectFactory<?> objectFactory) {
// 获取 scope 缓存
Map<String, Object> scope = this.threadScope.get();
Object scopedObject = scope.get(name);
if (scopedObject == null) {
scopedObject = objectFactory.getObject();
// 加入缓存
scope.put(name, scopedObject);
}
return scopedObject;
}
对于上面三个模块,其中最重要的方法,是 createBean(),也就是核心创建bean的过程,下面我们来具体看看。
createBeanInstance
我们首先从createBeanInstance方法开始。方法代码如下:
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// 解析 bean,将 bean 类名解析为 class 引用
Class<?> beanClass = resolveBeanClass(mbd, beanName);
if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());
}
// 如果存在 Supplier 回调,则使用给定的回调方法初始化策略
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
// 如果工厂方法不为空,则使用工厂方法初始化策略,这里推荐看Factory-Method实例化Bean
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
// constructorArgumentLock 构造函数的常用锁
synchronized (mbd.constructorArgumentLock) {
// 如果已缓存的解析的构造函数或者工厂方法不为空,则可以利用构造函数解析
// 因为需要根据参数确认到底使用哪个构造函数,该过程比较消耗性能,所有采用缓存机制
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
// 已经解析好了,直接注入即可
if (resolved) {
// 自动注入,调用构造函数自动注入
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 使用默认构造函数构造
return instantiateBean(beanName, mbd);
}
}
// 确定解析的构造函数
// 主要是检查已经注册的 SmartInstantiationAwareBeanPostProcessor
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
// 构造函数自动注入
return autowireConstructor(beanName, mbd, ctors, args);
}
//使用默认构造函数注入
return instantiateBean(beanName, mbd);
}
实例化 bean 是一个复杂的过程,其主要的逻辑为:
- 如果存在 Supplier 回调,则调用
obtainFromSupplier()进行初始化 - 如果存在工厂方法,则使用工厂方法进行初始化
- 首先判断缓存,如果缓存中存在,即已经解析过了,则直接使用已经解析了的,根据 constructorArgumentsResolved 参数来判断是使用构造函数自动注入还是默认构造函数
- 如果缓存中没有,则需要先确定到底使用哪个构造函数来完成解析工作,因为一个类有多个构造函数,每个构造函数都有不同的构造参数,所以需要根据参数来锁定构造函数并完成初始化,如果存在参数则使用相应的带有参数的构造函数,否则使用默认构造函数。
instantiateBean
不带参数的构造函数的实例化过程使用的方法是instantiateBean(beanName, mbd),我们看下源码:
protected BeanWrapper instantiateBean(final String beanName, final RootBeanDefinition mbd) {
try {
Object beanInstance;
final BeanFactory parent = this;
if (System.getSecurityManager() != null) {
beanInstance = AccessController.doPrivileged((PrivilegedAction<Object>) () ->
getInstantiationStrategy().instantiate(mbd, beanName, parent),
getAccessControlContext());
}
else {
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
实例化策略
实例化过程中,反复提到了实例化策略,这是做什么的呢?其实,经过前面的分析,我们已经得到了足以实例化的相关信息,完全可以使用最简单的反射方法来构造实例对象,但Spring却没有这么做。 接下来我们看下Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner)方法,具体的实现是在SimpleInstantiationStrategy中,具体代码如下:
public Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) {
// 没有覆盖
// 直接使用反射实例化即可
if (!bd.hasMethodOverrides()) {
// 重新检测获取下构造函数
// 该构造函数是经过前面 N 多复杂过程确认的构造函数
Constructor<?> constructorToUse;
synchronized (bd.constructorArgumentLock) {
// 获取已经解析的构造函数
constructorToUse = (Constructor<?>) bd.resolvedConstructorOrFactoryMethod;
// 如果为 null,从 class 中解析获取,并设置
if (constructorToUse == null) {
final Class<?> clazz = bd.getBeanClass();
if (clazz.isInterface()) {
throw new BeanInstantiationException(clazz, "Specified class is an interface");
}
try {
if (System.getSecurityManager() != null) {
constructorToUse = AccessController.doPrivileged(
(PrivilegedExceptionAction<Constructor<?>>) clazz::getDeclaredConstructor);
}
else {
//利用反射获取构造器
constructorToUse = clazz.getDeclaredConstructor();
}
bd.resolvedConstructorOrFactoryMethod = constructorToUse;
}
catch (Throwable ex) {
throw new BeanInstantiationException(clazz, "No default constructor found", ex);
}
}
}
// 通过BeanUtils直接使用构造器对象实例化bean
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// 生成CGLIB创建的子类对象
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
如果该 bean 没有配置 lookup-method、replaced-method 标签或者 @Lookup 注解,则直接通过反射的方式实例化 bean 即可,方便快捷,但是如果存在需要覆盖的方法或者动态替换的方法则需要使用 CGLIB 进行动态代理,因为可以在创建代理的同时将动态方法织入类中。
调用工具类 BeanUtils 的 instantiateClass() 方法完成反射工作:
public static <T> T instantiateClass(Constructor<T> ctor, Object... args) throws BeanInstantiationException {
Assert.notNull(ctor, "Constructor must not be null");
try {
ReflectionUtils.makeAccessible(ctor);
return (KotlinDetector.isKotlinType(ctor.getDeclaringClass()) ?
KotlinDelegate.instantiateClass(ctor, args) : ctor.newInstance(args));
}
// 省略一些 catch
}
CGLIB
protected Object instantiateWithMethodInjection(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) {
throw new UnsupportedOperationException("Method Injection not supported in SimpleInstantiationStrategy");
}
方法默认是没有实现的,具体过程由其子类 CglibSubclassingInstantiationStrategy 实现:
protected Object instantiateWithMethodInjection(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) {
return instantiateWithMethodInjection(bd, beanName, owner, null);
}
protected Object instantiateWithMethodInjection(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner,
@Nullable Constructor<?> ctor, @Nullable Object... args) {
// 通过CGLIB生成一个子类对象
return new CglibSubclassCreator(bd, owner).instantiate(ctor, args);
}
创建一个 CglibSubclassCreator 对象,调用其 instantiate() 方法生成其子类对象:
public Object instantiate(@Nullable Constructor<?> ctor, @Nullable Object... args) {
// 通过 Cglib 创建一个代理类
Class<?> subclass = createEnhancedSubclass(this.beanDefinition);
Object instance;
// 没有构造器,通过 BeanUtils 使用默认构造器创建一个bean实例
if (ctor == null) {
instance = BeanUtils.instantiateClass(subclass);
}
else {
try {
// 获取代理类对应的构造器对象,并实例化 bean
Constructor<?> enhancedSubclassConstructor = subclass.getConstructor(ctor.getParameterTypes());
instance = enhancedSubclassConstructor.newInstance(args);
}
catch (Exception ex) {
throw new BeanInstantiationException(this.beanDefinition.getBeanClass(),
"Failed to invoke constructor for CGLIB enhanced subclass [" + subclass.getName() + "]", ex);
}
}
// 为了避免memory leaks异常,直接在bean实例上设置回调对象
Factory factory = (Factory) instance;
factory.setCallbacks(new Callback[] {NoOp.INSTANCE,
new CglibSubclassingInstantiationStrategy.LookupOverrideMethodInterceptor(this.beanDefinition, this.owner),
new CglibSubclassingInstantiationStrategy.ReplaceOverrideMethodInterceptor(this.beanDefinition, this.owner)});
return instance;
}
当然这里还没有具体分析 CGLIB 生成子类的详细过程,具体的过程等后续分析 AOP 的时候再详细地介绍。
记录创建bean的ObjectFactory
在刚刚创建完Bean的实例后,也就是刚刚执行完构造器实例化后,doCreateBean方法中有下面一段代码:
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//为避免后期循环依赖,可以在bean初始化完成前将创建实例的ObjectFactory加入工厂
//依赖处理:在Spring中会有循环依赖的情况,例如,当A中含有B的属性,而B中又含有A的属性时就会
//构成一个循环依赖,此时如果A和B都是单例,那么在Spring中的处理方式就是当创建B的时候,涉及
//自动注入A的步骤时,并不是直接去再次创建A,而是通过放入缓存中的ObjectFactory来创建实例,
//这样就解决了循环依赖的问题。
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
isSingletonCurrentlyInCreation(beanName):该bean是否在创建中。在Spring中,会有个专门的属性默认为DefaultSingletonBeanRegistry的singletonsCurrentlyInCreation来记录bean的加载状态,在bean开始创建前会将beanName记录在属性中,在bean创建结束后会将beanName移除。那么我们跟随代码一路走下来可以对这个属性的记录并没有多少印象,这个状态是在哪里记录的呢?不同scope的记录位置不一样,我们以singleton为例,在singleton下记录属性的函数是在DefaultSingletonBeanRegistry类的public Object getSingleton(String beanName,ObjectFactory singletonFactory)函数的beforeSingletonCreation(beanName)和afterSingletonCreation(beanName)中,在这两段函数中分别this.singletonsCurrentlyInCreation.add(beanName)与this.singletonsCurrentlyInCreation.remove(beanName)来进行状态的记录与移除。
变量earlySingletonExposure是否是单例,是否允许循环依赖,是否对应的bean正在创建的条件的综合。当这3个条件都满足时会执行addSingletonFactory操作,那么加入SingletonFactory的作用是什么?又是在什么时候调用的? 我们还是以最简单AB循环为例,类A中含有属性B,而类B中又会含有属性A,那么初始化beanA的过程如下:
上图展示了创建BeanA的流程,在创建A的时候首先会记录类A所对应额beanName,并将beanA的创建工厂加入缓存中,而在对A的属性填充也就是调用pupulateBean方法的时候又会再一次的对B进行递归创建。同样的,因为在B中同样存在A属性,因此在实例化B的populateBean方法中又会再次地初始化B,也就是图形的最后,调用getBean(A).关键是在这里,我们之前分析过,在这个函数中并不是直接去实例化A,而是先去检测缓存中是否有已经创建好的对应的bean,或者是否已经创建的ObjectFactory,而此时对于A的ObjectFactory我们早已经创建,所以便不会再去向后执行,而是直接调用ObjectFactory去创建A.这里最关键的是ObjectFactory的实现。
其中getEarlyBeanReference的代码如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (bean != null && !mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
if (exposedObject == null) {
return exposedObject;
}
}
}
}
return exposedObject;
}
在getEarlyBeanReference函数中除了后处理的调用外没有别的处理工作,根据分析,基本可以理清Spring处理循环依赖的解决办法,在B中创建依赖A时通过ObjectFactory提供的实例化方法来获取原始A,使B中持有的A仅仅是刚刚初始化并没有填充任何属性的A,而这初始化A的步骤还是刚刚创建A时进行的,但是因为A与B中的A所表示的属性地址是一样的所以在A中创建好的属性填充自然可以通过B中的A获取,这样就解决了循环依赖的问题。
IOC 之 属性填充
doCreateBean() 主要用于完成 bean 的创建和初始化工作,我们可以将其分为四个过程:
createBeanInstance()实例化 beanpopulateBean()属性填充- 循环依赖的处理
initializeBean()初始化 bean
第一个过程实例化 bean在前面一篇博客中已经分析完了,这篇博客开始分析 属性填充,也就是 populateBean()
protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
PropertyValues pvs = mbd.getPropertyValues();
if (bw == null) {
if (!pvs.isEmpty()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
// state of the bean before properties are set. This can be used, for example,
// to support styles of field injection.
boolean continueWithPropertyPopulation = true;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
//返回值为是否继续填充bean
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
}
//如果后处理器发出停止填充命令则终止后续的执行
if (!continueWithPropertyPopulation) {
return;
}
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
//根据名称自动注入
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
//根据类型自动注入
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
//后处理器已经初始化
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
//需要依赖检查
boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
if (hasInstAwareBpps || needsDepCheck) {
PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
if (hasInstAwareBpps) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
//对所有需要依赖检查的属性进行后处理
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
}
if (needsDepCheck) {
//依赖检查,对应depends-on属性,3.0已经弃用此属性
checkDependencies(beanName, mbd, filteredPds, pvs);
}
}
//将属性应用到bean中
//将所有ProtertyValues中的属性填充至BeanWrapper中。
applyPropertyValues(beanName, mbd, bw, pvs);
}
我们详细分析下populateBean的流程: (1)首先进行属性是否为空的判断 (2)通过调用InstantiationAwareBeanPostProcessor的postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)方法来控制程序是否继续进行属性填充 (3)根据注入类型(byName/byType)提取依赖的bean,并统一存入PropertyValues中 (4)应用InstantiationAwareBeanPostProcessor的postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName)方法,对属性获取完毕填充前的再次处理,典型的应用是RequiredAnnotationBeanPostProcesser类中对属性的验证 (5)将所有的PropertyValues中的属性填充至BeanWrapper中 上面步骤中有几个地方是我们比较感兴趣的,它们分别是依赖注入(autowireByName/autowireByType)以及属性填充,接下来进一步分析这几个功能的实现细节
自动注入
Spring 会根据注入类型( byName / byType )的不同,调用不同的方法(autowireByName() / autowireByType())来注入属性值。
autowireByName()
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
// 获取 Bean 对象中非简单属性
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
// 如果容器中包含指定名称的 bean,则将该 bean 注入到 bean中
if (containsBean(propertyName)) {
// 递归初始化相关 bean
Object bean = getBean(propertyName);
// 为指定名称的属性赋予属性值
pvs.add(propertyName, bean);
// 属性依赖注入
registerDependentBean(propertyName, beanName);
if (logger.isDebugEnabled()) {
logger.debug("Added autowiring by name from bean name '" + beanName +
"' via property '" + propertyName + "' to bean named '" + propertyName + "'");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Not autowiring property '" + propertyName + "' of bean '" + beanName +
"' by name: no matching bean found");
}
}
}
}
该方法逻辑很简单,获取该 bean 的非简单属性,什么叫做非简单属性呢?就是类型为对象类型的属性,但是这里并不是将所有的对象类型都都会找到,比如 8 个原始类型,String 类型 ,Number类型、Date类型、URL类型、URI类型等都会被忽略,如下:
protected String[] unsatisfiedNonSimpleProperties(AbstractBeanDefinition mbd, BeanWrapper bw) {
Set<String> result = new TreeSet<>();
PropertyValues pvs = mbd.getPropertyValues();
PropertyDescriptor[] pds = bw.getPropertyDescriptors();
for (PropertyDescriptor pd : pds) {
if (pd.getWriteMethod() != null && !isExcludedFromDependencyCheck(pd) && !pvs.contains(pd.getName()) &&
!BeanUtils.isSimpleProperty(pd.getPropertyType())) {
result.add(pd.getName());
}
}
return StringUtils.toStringArray(result);
}
这里获取的就是需要依赖注入的属性。
autowireByName()函数的功能就是根据传入的参数中的pvs中找出已经加载的bean,并递归实例化,然后加入到pvs中
autowireByType
autowireByType与autowireByName对于我们理解与使用来说复杂程度相似,但是实现功能的复杂度却不一样,我们看下方法代码:
protected void autowireByType(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
Set<String> autowiredBeanNames = new LinkedHashSet<String>(4);
//寻找bw中需要依赖注入的属性
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
try {
PropertyDescriptor pd = bw.getPropertyDescriptor(propertyName);
// Don't try autowiring by type for type Object: never makes sense,
// even if it technically is a unsatisfied, non-simple property.
if (!Object.class.equals(pd.getPropertyType())) {
//探测指定属性的set方法
MethodParameter methodParam = BeanUtils.getWriteMethodParameter(pd);
// Do not allow eager init for type matching in case of a prioritized post-processor.
boolean eager = !PriorityOrdered.class.isAssignableFrom(bw.getWrappedClass());
DependencyDescriptor desc = new AutowireByTypeDependencyDescriptor(methodParam, eager);
//解析指定beanName的属性所匹配的值,并把解析到的属性名称存储在autowiredBeanNames中,
Object autowiredArgument = resolveDependency(desc, beanName, autowiredBeanNames, converter);
if (autowiredArgument != null) {
pvs.add(propertyName, autowiredArgument);
}
for (String autowiredBeanName : autowiredBeanNames) {
//注册依赖
registerDependentBean(autowiredBeanName, beanName);
if (logger.isDebugEnabled()) {
logger.debug("Autowiring by type from bean name '" + beanName + "' via property '" +
propertyName + "' to bean named '" + autowiredBeanName + "'");
}
}
autowiredBeanNames.clear();
}
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(mbd.getResourceDescription(), beanName, propertyName, ex);
}
}
}
根据名称第一步与根据属性第一步都是寻找bw中需要依赖注入的属性,然后遍历这些属性并寻找类型匹配的bean,其中最复杂就是寻找类型匹配的bean。spring中提供了对集合的类型注入支持,如使用如下注解方式:
@Autowired
private List<Test> tests;
这种方式spring会把所有与Test匹配的类型找出来并注入到tests属性中,正是由于这一因素,所以在autowireByType函数,新建了局部遍历autowireBeanNames,用于存储所有依赖的bean,如果只是对非集合类的属性注入来说,此属性并无用处。 对于寻找类型匹配的逻辑实现是封装在了resolveDependency函数中,其实现如下:
public Object resolveDependency(DependencyDescriptor descriptor, String beanName, Set<String> autowiredBeanNames, TypeConverter typeConverter) throws BeansException {
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
if (descriptor.getDependencyType().equals(ObjectFactory.class)) {
//ObjectFactory类注入的特殊处理
return new DependencyObjectFactory(descriptor, beanName);
}
else if (descriptor.getDependencyType().equals(javaxInjectProviderClass)) {
//javaxInjectProviderClass类注入的特殊处理
return new DependencyProviderFactory().createDependencyProvider(descriptor, beanName);
}
else {
//通用处理逻辑
return doResolveDependency(descriptor, descriptor.getDependencyType(), beanName, autowiredBeanNames, typeConverter);
}
}
protected Object doResolveDependency(DependencyDescriptor descriptor, Class<?> type, String beanName,
Set<String> autowiredBeanNames, TypeConverter typeConverter) throws BeansException {
/*
* 用于支持Spring中新增的注解@Value
*/
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ? getMergedBeanDefinition(beanName) : null);
value = evaluateBeanDefinitionString(strVal, bd);
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
//如果解析器没有成功解析,则需要考虑各种情况
//属性是数组类型
if (type.isArray()) {
Class<?> componentType = type.getComponentType();
//根据属性类型找到beanFactory中所有类型的匹配bean,
//返回值的构成为:key=匹配的beanName,value=beanName对应的实例化后的bean(通过getBean(beanName)返回)
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, componentType, descriptor);
if (matchingBeans.isEmpty()) {
//如果autowire的require属性为true而找到的匹配项却为空则只能抛出异常
if (descriptor.isRequired()) {
raiseNoSuchBeanDefinitionException(componentType, "array of " + componentType.getName(), descriptor);
}
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
//通过转换器将bean的值转换为对应的type类型
return converter.convertIfNecessary(matchingBeans.values(), type);
}
//属性是Collection类型
else if (Collection.class.isAssignableFrom(type) && type.isInterface()) {
Class<?> elementType = descriptor.getCollectionType();
if (elementType == null) {
if (descriptor.isRequired()) {
throw new FatalBeanException("No element type declared for collection [" + type.getName() + "]");
}
return null;
}
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, elementType, descriptor);
if (matchingBeans.isEmpty()) {
if (descriptor.isRequired()) {
raiseNoSuchBeanDefinitionException(elementType, "collection of " + elementType.getName(), descriptor);
}
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
return converter.convertIfNecessary(matchingBeans.values(), type);
}
//属性是Map类型
else if (Map.class.isAssignableFrom(type) && type.isInterface()) {
Class<?> keyType = descriptor.getMapKeyType();
if (keyType == null || !String.class.isAssignableFrom(keyType)) {
if (descriptor.isRequired()) {
throw new FatalBeanException("Key type [" + keyType + "] of map [" + type.getName() +
"] must be assignable to [java.lang.String]");
}
return null;
}
Class<?> valueType = descriptor.getMapValueType();
if (valueType == null) {
if (descriptor.isRequired()) {
throw new FatalBeanException("No value type declared for map [" + type.getName() + "]");
}
return null;
}
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, valueType, descriptor);
if (matchingBeans.isEmpty()) {
if (descriptor.isRequired()) {
raiseNoSuchBeanDefinitionException(valueType, "map with value type " + valueType.getName(), descriptor);
}
return null;
}
if (autowiredBeanNames != null) {
autowiredBeanNames.addAll(matchingBeans.keySet());
}
return matchingBeans;
}
else {
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (descriptor.isRequired()) {
raiseNoSuchBeanDefinitionException(type, "", descriptor);
}
return null;
}
if (matchingBeans.size() > 1) {
String primaryBeanName = determinePrimaryCandidate(matchingBeans, descriptor);
if (primaryBeanName == null) {
throw new NoUniqueBeanDefinitionException(type, matchingBeans.keySet());
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(primaryBeanName);
}
return matchingBeans.get(primaryBeanName);
}
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
if (autowiredBeanNames != null) {
autowiredBeanNames.add(entry.getKey());
}
//已经确定只有一个匹配项
return entry.getValue();
}
}
主要就是通过Type从BeanFactory中找到对应的benaName,然后通过getBean获取实例
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
//在BeanFactory找到所有Type类型的beanName
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = new LinkedHashMap<>(candidateNames.length);
//遍历所有的beanName,通过getBean获取
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
//
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
return result;
}
private void addCandidateEntry(Map<String, Object> candidates, String candidateName,
DependencyDescriptor descriptor, Class<?> requiredType) {
Object beanInstance = descriptor.resolveCandidate(candidateName, requiredType, this);
if (!(beanInstance instanceof NullBean)) {
candidates.put(candidateName, beanInstance);
}
}
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory)
throws BeansException {
//通过类型找到beanName,然后再找到其实例
return beanFactory.getBean(beanName);
}
applyPropertyValues
程序运行到这里,已经完成了对所有注入属性的获取,但是获取的属性是以PropertyValues形式存在的,还并没有应用到已经实例化的bean中,这一工作是在applyPropertyValues中。继续跟踪到方法体中:
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
if (pvs == null || pvs.isEmpty()) {
return;
}
MutablePropertyValues mpvs = null;
List<PropertyValue> original;
if (System.getSecurityManager() != null) {
if (bw instanceof BeanWrapperImpl) {
((BeanWrapperImpl) bw).setSecurityContext(getAccessControlContext());
}
}
if (pvs instanceof MutablePropertyValues) {
mpvs = (MutablePropertyValues) pvs;
//如果mpvs中的值已经被转换为对应的类型那么可以直接设置到beanwapper中
if (mpvs.isConverted()) {
// Shortcut: use the pre-converted values as-is.
try {
bw.setPropertyValues(mpvs);
return;
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
original = mpvs.getPropertyValueList();
}
else {
//如果pvs并不是使用MutablePropertyValues封装的类型,那么直接使用原始的属性获取方法
original = Arrays.asList(pvs.getPropertyValues());
}
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
//获取对应的解析器
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
// Create a deep copy, resolving any references for values.
List<PropertyValue> deepCopy = new ArrayList<PropertyValue>(original.size());
boolean resolveNecessary = false;
//遍历属性,将属性转换为对应类的对应属性的类型
for (PropertyValue pv : original) {
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
String propertyName = pv.getName();
Object originalValue = pv.getValue();
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
// Possibly store converted value in merged bean definition,
// in order to avoid re-conversion for every created bean instance.
if (resolvedValue == originalValue) {
if (convertible) {
pv.setConvertedValue(convertedValue);
}
deepCopy.add(pv);
}
else if (convertible && originalValue instanceof TypedStringValue &&
!((TypedStringValue) originalValue).isDynamic() &&
!(convertedValue instanceof Collection || ObjectUtils.isArray(convertedValue))) {
pv.setConvertedValue(convertedValue);
deepCopy.add(pv);
}
else {
resolveNecessary = true;
deepCopy.add(new PropertyValue(pv, convertedValue));
}
}
}
if (mpvs != null && !resolveNecessary) {
mpvs.setConverted();
}
// Set our (possibly massaged) deep copy.
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
我们来看看具体的属性赋值过程
public class MyTestBean {
private String name ;
public MyTestBean(String name) {
this.name = name;
}
public MyTestBean() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
<bean id="myTestBean" class="chenhao.spring01.MyTestBean">
<property name="name" value="chenhao"></property>
</bean>
如上 bw.setPropertyValues 最终都会走到如下方法
@Override
public void setValue(final @Nullable Object value) throws Exception {
//获取writeMethod,也就是我们MyTestBean的setName方法
final Method writeMethod = (this.pd instanceof GenericTypeAwarePropertyDescriptor ?
((GenericTypeAwarePropertyDescriptor) this.pd).getWriteMethodForActualAccess() :
this.pd.getWriteMethod());
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
ReflectionUtils.makeAccessible(writeMethod);
return null;
});
try {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () ->
writeMethod.invoke(getWrappedInstance(), value), acc);
}
catch (PrivilegedActionException ex) {
throw ex.getException();
}
}
else {
ReflectionUtils.makeAccessible(writeMethod);
//通过反射调用方法进行赋值
writeMethod.invoke(getWrappedInstance(), value);
}
}
Debug如下
就是利用反射进行调用对象的set方法赋值
至此,doCreateBean() 第二个过程:属性填充 已经分析完成了,下篇分析第三个过程:循环依赖的处理,其实循环依赖并不仅仅只是在 doCreateBean() 中处理,其实在整个加载 bean 的过程中都有涉及,所以下篇内容并不仅仅只局限于 doCreateBean()。
IOC 之 循环依赖处理
什么是循环依赖
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图所示:
注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。 Spring中循环依赖场景有: (1)构造器的循环依赖 (2)field属性的循环依赖。
对于构造器的循环依赖,Spring 是无法解决的,只能抛出 BeanCurrentlyInCreationException 异常表示循环依赖,所以下面我们分析的都是基于 field 属性的循环依赖。
Spring 只解决 scope 为 singleton 的循环依赖,对于scope 为 prototype 的 bean Spring 无法解决,直接抛出 BeanCurrentlyInCreationException 异常。
如何检测循环依赖
检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
解决循环依赖
我们先从加载 bean 最初始的方法 doGetBean() 开始。
在 doGetBean() 中,首先会根据 beanName 从单例 bean 缓存中获取,如果不为空则直接返回。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
这个方法主要是从三个缓存中获取,分别是:singletonObjects、earlySingletonObjects、singletonFactories,三者定义如下:
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
这三级缓存分别指: (1)singletonFactories : 单例对象工厂的cache (2)earlySingletonObjects :提前暴光的单例对象的Cache (3)singletonObjects:单例对象的cache
他们就是 Spring 解决 singleton bean 的关键因素所在,我称他们为三级缓存,第一级为 singletonObjects,第二级为 earlySingletonObjects,第三级为 singletonFactories。这里我们可以通过 getSingleton() 看到他们是如何配合的,这分析该方法之前,提下其中的 isSingletonCurrentlyInCreation() 和 allowEarlyReference。
isSingletonCurrentlyInCreation():判断当前 singleton bean 是否处于创建中。bean 处于创建中也就是说 bean 在初始化但是没有完成初始化,有一个这样的过程其实和 Spring 解决 bean 循环依赖的理念相辅相成,因为 Spring 解决 singleton bean 的核心就在于提前曝光 bean。- allowEarlyReference:从字面意思上面理解就是允许提前拿到引用。其实真正的意思是是否允许从 singletonFactories 缓存中通过
getObject()拿到对象,为什么会有这样一个字段呢?原因就在于 singletonFactories 才是 Spring 解决 singleton bean 的诀窍所在,这个我们后续分析。
getSingleton() 整个过程如下:首先从一级缓存 singletonObjects 获取,如果没有且当前指定的 beanName 正在创建,就再从二级缓存中 earlySingletonObjects 获取,如果还是没有获取到且运行 singletonFactories 通过 getObject() 获取,则从三级缓存 singletonFactories 获取,如果获取到则,通过其 getObject() 获取对象,并将其加入到二级缓存 earlySingletonObjects 中 从三级缓存 singletonFactories 删除,如下:
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
这样就从三级缓存升级到二级缓存了。
上面是从缓存中获取,但是缓存中的数据从哪里添加进来的呢?一直往下跟会发现在 doCreateBean() ( AbstractAutowireCapableBeanFactory ) 中,有这么一段代码:
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
也就是我们上一篇文章中讲的最后一部分,提前将创建好但还未进行属性赋值的的Bean放入缓存中。
如果 earlySingletonExposure == true 的话,则调用 addSingletonFactory() 将他们添加到缓存中,但是一个 bean 要具备如下条件才会添加至缓存中:
- 单例
- 运行提前暴露 bean
- 当前 bean 正在创建中
addSingletonFactory() 代码如下:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
从这段代码我们可以看出 singletonFactories 这个三级缓存才是解决 Spring Bean 循环依赖的诀窍所在。同时这段代码发生在 createBeanInstance() 方法之后,也就是说这个 bean 其实已经被创建出来了,但是它还不是很完美(没有进行属性填充和初始化),但是对于其他依赖它的对象而言已经足够了(可以根据对象引用定位到堆中对象),能够被认出来了,所以 Spring 在这个时候选择将该对象提前曝光出来让大家认识认识。
介绍到这里我们发现三级缓存 singletonFactories 和 二级缓存 earlySingletonObjects 中的值都有出处了,那一级缓存在哪里设置的呢?在类 DefaultSingletonBeanRegistry 中可以发现这个 addSingleton() 方法,源码如下:
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
添加至一级缓存,同时从二级、三级缓存中删除。这个方法在我们创建 bean 的链路中有哪个地方引用呢?其实在前面博客 LZ 已经提到过了,在 doGetBean() 处理不同 scope 时,如果是 singleton,则调用 getSingleton(),如下:
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//....
try {
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
//.....
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
至此,Spring 关于 singleton bean 循环依赖已经分析完毕了。所以我们基本上可以确定 Spring 解决循环依赖的方案了:Spring 在创建 bean 的时候并不是等它完全完成,而是在创建过程中将创建中的 bean 的 ObjectFactory 提前曝光(即加入到 singletonFactories 缓存中),这样一旦下一个 bean 创建的时候需要依赖 bean ,则直接使用 ObjectFactory 的 getObject() 获取了,也就是 getSingleton()中的代码片段了。
到这里,关于 Spring 解决 bean 循环依赖就已经分析完毕了。最后来描述下就上面那个循环依赖 Spring 解决的过程:首先 A 完成初始化第一步并将自己提前曝光出来(通过 ObjectFactory 将自己提前曝光),在初始化的时候,发现自己依赖对象 B,此时就会去尝试 get(B),这个时候发现 B 还没有被创建出来,然后 B 就走创建流程,在 B 初始化的时候,同样发现自己依赖 C,C 也没有被创建出来,这个时候 C 又开始初始化进程,但是在初始化的过程中发现自己依赖 A,于是尝试 get(A),这个时候由于 A 已经添加至缓存中(一般都是添加至三级缓存 singletonFactories ),通过 ObjectFactory 提前曝光,所以可以通过 ObjectFactory.getObject() 拿到 A 对象,C 拿到 A 对象后顺利完成初始化,然后将自己添加到一级缓存中,回到 B ,B 也可以拿到 C 对象,完成初始化,A 可以顺利拿到 B 完成初始化。到这里整个链路就已经完成了初始化过程了。
IOC 之 bean 的初始化
一个 bean 经历了 createBeanInstance() 被创建出来,然后又经过一番属性注入,依赖处理,历经千辛万苦,千锤百炼,终于有点儿 bean 实例的样子,能堪大任了,只需要经历最后一步就破茧成蝶了。这最后一步就是初始化,也就是 initializeBean(),所以这篇文章我们分析 doCreateBean() 中最后一步:初始化 bean。
我回到之前的doCreateBean方法中,如下
在populateBean方法下面有一个initializeBean(beanName, exposedObject, mbd)方法,这个就是用来执行用户设定的初始化操作。我们看下方法体:
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
// 激活 Aware 方法
invokeAwareMethods(beanName, bean);
return null;
}, getAccessControlContext());
}
else {
// 对特殊的 bean 处理:Aware、BeanClassLoaderAware、BeanFactoryAware
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 后处理器
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
// 激活用户自定义的 init 方法
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
// 后处理器
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
初始化 bean 的方法其实就是三个步骤的处理,而这三个步骤主要还是根据用户设定的来进行初始化,这三个过程为:
- 激活 Aware 方法
- 后置处理器的应用
- 激活自定义的 init 方法
激活Aware方法
我们先了解一下Aware方法的使用。Spring中提供了一些Aware接口,比如BeanFactoryAware,ApplicationContextAware,ResourceLoaderAware,ServletContextAware等,实现这些Aware接口的bean在被初始化后,可以取得一些相对应的资源,例如实现BeanFactoryAware的bean在初始化之后,Spring容器将会注入BeanFactory实例,而实现ApplicationContextAware的bean,在bean被初始化后,将会被注入ApplicationContext实例等。我们先通过示例方法了解下Aware的使用。 定义普通bean,如下代码:
public class HelloBean {
public void say()
{
System.out.println("Hello");
}
}
定义beanFactoryAware类型的bean
public class MyBeanAware implements BeanFactoryAware {
private BeanFactory beanFactory;
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
}
public void testAware()
{
//通过hello这个bean id从beanFactory获取实例
HelloBean hello = (HelloBean)beanFactory.getBean("hello");
hello.say();
}
}
进行测试
public class Test {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
MyBeanAware test = (MyBeanAware)ctx.getBean("myBeanAware");
test.testAware();
}
}
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="myBeanAware" class="com.demo.spring.MyBeanAware">
</bean>
<bean id="hello" class="com.chenhao.spring.HelloBean">
</bean>
</beans>
输出
Hello
上面的方法我们获取到Spring中BeanFactory,并且可以根据BeanFactory获取所有的bean,以及进行相关设置。还有其他Aware的使用都是大同小异,看一下Spring的实现方式:
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
((BeanClassLoaderAware) bean).setBeanClassLoader(getBeanClassLoader());
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
处理器的应用
BeanPostPrecessor我们经常看到Spring中使用,这是Spring开放式架构的一个必不可少的亮点,给用户充足的权限去更改或者扩展Spring,而除了BeanPostProcessor外还有很多其他的PostProcessor,当然大部分都以此为基础,集成自BeanPostProcessor。BeanPostProcessor在调用用户自定义初始化方法前或者调用自定义初始化方法后分别会调用BeanPostProcessor的postProcessBeforeInitialization和postProcessAfterinitialization方法,使用户可以根据自己的业务需求就行相应的处理。
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
result = beanProcessor.postProcessBeforeInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
result = beanProcessor.postProcessAfterInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
激活自定义的init方法
客户定制的初始化方法除了我们熟知的使用配置init-method外,还有使自定义的bean实现InitializingBean接口,并在afterPropertiesSet中实现自己的初始化业务逻辑。 init-method与afterPropertiesSet都是在初始化bean时执行,执行顺序是afterPropertiesSet先执行,而init-method后执行。 在invokeInitMethods方法中就实现了这两个步骤的初始化调用。
protected void invokeInitMethods(String beanName, final Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
// 是否实现 InitializingBean
// 如果实现了 InitializingBean 接口,则只掉调用bean的 afterPropertiesSet()
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isDebugEnabled()) {
logger.debug("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {
((InitializingBean) bean).afterPropertiesSet();
return null;
}, getAccessControlContext());
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
// 直接调用 afterPropertiesSet()
((InitializingBean) bean).afterPropertiesSet();
}
}
if (mbd != null && bean.getClass() != NullBean.class) {
// 判断是否指定了 init-method(),
// 如果指定了 init-method(),则再调用制定的init-method
String initMethodName = mbd.getInitMethodName();
if (StringUtils.hasLength(initMethodName) &&
!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
// 利用反射机制执行
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
首先检测当前 bean 是否实现了 InitializingBean 接口,如果实现了则调用其 afterPropertiesSet(),然后再检查是否也指定了 init-method(),如果指定了则通过反射机制调用指定的 init-method()。
init-method()
public class InitializingBeanTest {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void setOtherName(){
System.out.println("InitializingBeanTest setOtherName...");
this.name = "hello";
}
}
// 配置文件
<bean id="initializingBeanTest" class="com.demo.spring.InitializingBeanTest"
init-method="setOtherName">
<property name="name" value="hello123"/>
</bean>
执行结果:
hello
我们可以使用 <beans> 标签的 default-init-method 属性来统一指定初始化方法,这样就省了需要在每个 <bean> 标签中都设置 init-method 这样的繁琐工作了。比如在 default-init-method 规定所有初始化操作全部以 initBean() 命名。如下:
我们看看 invokeCustomInitMethod 方法:
protected void invokeCustomInitMethod(String beanName, final Object bean, RootBeanDefinition mbd)
throws Throwable {
String initMethodName = mbd.getInitMethodName();
Assert.state(initMethodName != null, "No init method set");
Method initMethod = (mbd.isNonPublicAccessAllowed() ?
BeanUtils.findMethod(bean.getClass(), initMethodName) :
ClassUtils.getMethodIfAvailable(bean.getClass(), initMethodName));
if (initMethod == null) {
if (mbd.isEnforceInitMethod()) {
throw new BeanDefinitionValidationException("Could not find an init method named '" +
initMethodName + "' on bean with name '" + beanName + "'");
}
else {
if (logger.isTraceEnabled()) {
logger.trace("No default init method named '" + initMethodName +
"' found on bean with name '" + beanName + "'");
}
// Ignore non-existent default lifecycle methods.
return;
}
}
if (logger.isTraceEnabled()) {
logger.trace("Invoking init method '" + initMethodName + "' on bean with name '" + beanName + "'");
}
Method methodToInvoke = ClassUtils.getInterfaceMethodIfPossible(initMethod);
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
ReflectionUtils.makeAccessible(methodToInvoke);
return null;
});
try {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () ->
methodToInvoke.invoke(bean), getAccessControlContext());
}
catch (PrivilegedActionException pae) {
InvocationTargetException ex = (InvocationTargetException) pae.getException();
throw ex.getTargetException();
}
}
else {
try {
ReflectionUtils.makeAccessible(initMethod);
initMethod.invoke(bean);
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
}
我们看出最后是使用反射的方式来执行初始化方法。
ApplicationContext容器refresh过程
在之前的博文中我们一直以BeanFactory接口以及它的默认实现类XmlBeanFactory为例进行分析,但是Spring中还提供了另一个接口ApplicationContext,用于扩展BeanFactory中现有的功能。 ApplicationContext和BeanFactory两者都是用于加载Bean的,但是相比之下,ApplicationContext提供了更多的扩展功能,简而言之:ApplicationContext包含BeanFactory的所有功能。通常建议比优先使用ApplicationContext,除非在一些限制的场合,比如字节长度对内存有很大的影响时(Applet),绝大多数“典型的”企业应用系统,ApplicationContext就是需要使用的。 那么究竟ApplicationContext比BeanFactory多了哪些功能?首先我们来看看使用两个不同的类去加载配置文件在写法上的不同如下代码:
//使用BeanFactory方式加载XML.
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("beanFactoryTest.xml"));
//使用ApplicationContext方式加载XML.
ApplicationContext bf = new ClassPathXmlApplicationContext("beanFactoryTest.xml");
接下来我们就以ClassPathXmlApplicationContext作为切入点,开始对整体功能进行分析。首先看下其构造函数:
public ClassPathXmlApplicationContext() {
}
public ClassPathXmlApplicationContext(ApplicationContext parent) {
super(parent);
}
public ClassPathXmlApplicationContext(String configLocation) throws BeansException {
this(new String[] {configLocation}, true, null);
}
public ClassPathXmlApplicationContext(String... configLocations) throws BeansException {
this(configLocations, true, null);
}
public ClassPathXmlApplicationContext(String[] configLocations, @Nullable ApplicationContext parent)
throws BeansException {
this(configLocations, true, parent);
}
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh) throws BeansException {
this(configLocations, refresh, null);
}
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
super(parent);
setConfigLocations(configLocations);
if (refresh) {
refresh();
}
}
设置路径是必不可少的步骤,ClassPathXmlApplicationContext中可以将配置文件路径以数组的方式传入,ClassPathXmlApplicationContext可以对数组进行解析并进行加载。而对于解析及功能实现都在refresh()中实现。
设置配置路径
在ClassPathXmlApplicationContext中支持多个配置文件以数组方式同时传入,以下是设置配置路径方法代码:
public void setConfigLocations(@Nullable String... locations) {
if (locations != null) {
Assert.noNullElements(locations, "Config locations must not be null");
this.configLocations = new String[locations.length];
for (int i = 0; i < locations.length; i++) {
this.configLocations[i] = resolvePath(locations[i]).trim();
}
}
else {
this.configLocations = null;
}
}
其中如果给定的路径中包含特殊符号,如${var},那么会在方法resolvePath中解析系统变量并替换
refresh功能
设置了路径之后,便可以根据路径做配置文件的解析以及各种功能的实现了。可以说refresh函数中包含了几乎ApplicationContext中提供的全部功能,而且此函数中逻辑非常清晰明了,使我们很容易分析对应的层次及逻辑,我们看下方法代码:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//准备刷新的上下文 环境
prepareRefresh();
//初始化BeanFactory,并进行XML文件读取
/*
* ClassPathXMLApplicationContext包含着BeanFactory所提供的一切特征,在这一步骤中将会复用
* BeanFactory中的配置文件读取解析及其他功能,这一步之后,ClassPathXmlApplicationContext
* 实际上就已经包含了BeanFactory所提供的功能,也就是可以进行Bean的提取等基础操作了。
*/
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//对beanFactory进行各种功能填充
prepareBeanFactory(beanFactory);
try {
//子类覆盖方法做额外处理
/*
* Spring之所以强大,为世人所推崇,除了它功能上为大家提供了便利外,还有一方面是它的
* 完美架构,开放式的架构让使用它的程序员很容易根据业务需要扩展已经存在的功能。这种开放式
* 的设计在Spring中随处可见,例如在本例中就提供了一个空的函数实现postProcessBeanFactory来
* 方便程序猿在业务上做进一步扩展
*/
postProcessBeanFactory(beanFactory);
//激活各种beanFactory处理器
invokeBeanFactoryPostProcessors(beanFactory);
//注册拦截Bean创建的Bean处理器,这里只是注册,真正的调用实在getBean时候
registerBeanPostProcessors(beanFactory);
//为上下文初始化Message源,即不同语言的消息体,国际化处理
initMessageSource();
//初始化应用消息广播器,并放入“applicationEventMulticaster”bean中
initApplicationEventMulticaster();
//留给子类来初始化其它的Bean
onRefresh();
//在所有注册的bean中查找Listener bean,注册到消息广播器中
registerListeners();
//初始化剩下的单实例(非惰性的)
finishBeanFactoryInitialization(beanFactory);
//完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程,同时发出ContextRefreshEvent通知别人
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
destroyBeans();
cancelRefresh(ex);
throw ex;
}
finally {
resetCommonCaches();
}
}
}
我们简单的分析下代码的步骤:
- 初始化前的准备工作,例如对系统属性或者环境变量进行准备及验证。 在某种情况下项目的使用需要读取某些系统变量,而这个变量的设置很可能会影响着系统的正确性,那么ClassPathXmlApplicationContext为我们提供的这个准备函数就显得非常必要,他可以在spring启动的时候提前对必须的环境变量进行存在性验证。
- 初始化BeanFactory,并进行XML文件读取。 之前提到ClassPathXmlApplicationContext包含着对BeanFactory所提供的一切特征,那么这一步中将会复用BeanFactory中的配置文件读取解析其他功能,这一步之后ClassPathXmlApplicationContext实际上就已经包含了BeanFactory所提供的功能,也就是可以进行Bean的提取等基本操作了。
- 对BeanFactory进行各种功能填充 @Qualifier和@Autowired应该是大家非常熟悉的注解了,那么这两个注解正是在这一步骤中增加支持的。
- 子类覆盖方法做额外处理。 spring之所以强大,为世人所推崇,除了它功能上为大家提供了遍历外,还有一方面是它完美的架构,开放式的架构让使用它的程序员很容易根据业务需要扩展已经存在的功能。这种开放式的设计在spring中随处可见,例如本利中就提供了一个空的函数实现postProcessBeanFactory来方便程序员在业务上做进一步的扩展。
- 激活各种BeanFactory处理器
- 注册拦截bean创建的bean处理器,这里只是注册,真正的调用是在getBean时候
- 为上下文初始化Message源,及对不同语言的小西天进行国际化处理
- 初始化应用消息广播器,并放入“applicationEventMulticaster”bean中
- 留给子类来初始化其他的bean
- 在所有注册的bean中查找listener bean,注册到消息广播器中
- 初始化剩下的单实例(非惰性的)
- 完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程,同时发出ContextRefreshEvent通知别人。
详细过程源码解析
prepareRefresh刷新上下文的准备工作
/**
* 准备刷新上下文环境,设置它的启动日期和活动标志,以及执行任何属性源的初始化。
* Prepare this context for refreshing, setting its startup date and
* active flag as well as performing any initialization of property sources.
*/
protected void prepareRefresh() {
this.startupDate = System.currentTimeMillis();
this.closed.set(false);
this.active.set(true);
// 在上下文环境中初始化任何占位符属性源。(空的方法,留给子类覆盖)
initPropertySources();
// 验证需要的属性文件是否都已放入环境中
getEnvironment().validateRequiredProperties();
// 允许收集早期的应用程序事件,一旦有了多播器,就可以发布……
this.earlyApplicationEvents = new LinkedHashSet<>();
}
obtainFreshBeanFactory读取xml并初始化BeanFactory
obtainFreshBeanFactory方法从字面理解是获取beanFactory.ApplicationContext是对BeanFactory的扩展,在其基础上添加了大量的基础应用,obtainFreshBeanFactory正式实现beanFactory的地方,经过这个函数后ApplicationContext就有了BeanFactory的全部功能。我们看下此方法的代码:
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
//初始化BeanFactory,并进行XML文件读取,并将得到的BeanFactory记录在当前实体的属性中
refreshBeanFactory();
//返回当前实体的beanFactory属性
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
继续深入到refreshBeanFactory方法中,方法的实现是在AbstractRefreshableApplicationContext中:
@Override
protected final void refreshBeanFactory() throws BeansException {
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//创建DefaultListableBeanFactory
/*
* 以前我们分析BeanFactory的时候,不知道是否还有印象,声明方式为:BeanFactory bf =
* new XmlBeanFactory("beanFactoryTest.xml"),其中的XmlBeanFactory继承自DefaulltListableBeanFactory;
* 并提供了XmlBeanDefinitionReader类型的reader属性,也就是说DefaultListableBeanFactory是容器的基础。必须
* 首先要实例化。
*/
DefaultListableBeanFactory beanFactory = createBeanFactory();
//为了序列化指定id,如果需要的话,让这个BeanFactory从id反序列化到BeanFactory对象
beanFactory.setSerializationId(getId());
//定制beanFactory,设置相关属性,包括是否允许覆盖同名称的不同定义的对象以及循环依赖以及设置
//@Autowired和Qualifier注解解析器QualifierAnnotationAutowireCandidateResolver
customizeBeanFactory(beanFactory);
//加载BeanDefiniton
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
//使用全局变量记录BeanFactory实例。
//因为DefaultListableBeanFactory类型的变量beanFactory是函数内部的局部变量,
//所以要使用全局变量记录解析结果
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
加载BeanDefinition
在第一步中提到了将ClassPathXmlApplicationContext与XMLBeanFactory创建的对比,除了初始化DefaultListableBeanFactory外,还需要XmlBeanDefinitionReader来读取XML,那么在loadBeanDefinitions方法中首先要做的就是初始化XmlBeanDefinitonReader,我们跟着到loadBeanDefinitions(beanFactory)方法体中,我们看到的是在AbstractXmlApplicationContext中实现的,具体代码如下:
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
loadBeanDefinitions(beanDefinitionReader);
}
在初始化了DefaultListableBeanFactory和XmlBeanDefinitionReader后,就可以进行配置文件的读取了。继续进入到loadBeanDefinitions(beanDefinitionReader)方法体中,代码如下:
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
因为在XmlBeanDefinitionReader中已经将之前初始化的DefaultListableBeanFactory注册进去了,所以XmlBeanDefinitionReader所读取的BeanDefinitionHolder都会注册到DefinitionListableBeanFactory中,也就是经过这个步骤,DefaultListableBeanFactory的变量beanFactory已经包含了所有解析好的配置。
prepareBeanFactory(beanFactory)
如上图所示prepareBeanFactory(beanFactory)就是在功能上扩展的方法,而在进入这个方法前spring已经完成了对配置的解析,接下来我们详细分析下次函数,进入方法体:
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
// Tell the internal bean factory to use the context's class loader etc.
//设置beanFactory的classLoader为当前context的classloader
beanFactory.setBeanClassLoader(getClassLoader());
//设置beanFactory的表达式语言处理器,Spring3增加了表达式语言的支持,
//默认可以使用#{bean.xxx}的形式来调用相关属性值
beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader()));
//为beanFactory增加了一个的propertyEditor,这个主要是对bean的属性等设置管理的一个工具
beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this, getEnvironment()));
// Configure the bean factory with context callbacks.
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
//设置了几个忽略自动装配的接口
beanFactory.ignoreDependencyInterface(EnvironmentAware.class);
beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class);
beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class);
beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class);
beanFactory.ignoreDependencyInterface(MessageSourceAware.class);
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
// BeanFactory interface not registered as resolvable type in a plain factory.
// MessageSource registered (and found for autowiring) as a bean.
//设置了几个自动装配的特殊规则
beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
// Register early post-processor for detecting inner beans as ApplicationListeners.
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this));
// Detect a LoadTimeWeaver and prepare for weaving, if found.
//增加对AspectJ的支持
if (beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
// Set a temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
// Register default environment beans.
//添加默认的系统环境bean
if (!beanFactory.containsLocalBean(ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment());
}
if (!beanFactory.containsLocalBean(SYSTEM_PROPERTIES_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_PROPERTIES_BEAN_NAME, getEnvironment().getSystemProperties());
}
if (!beanFactory.containsLocalBean(SYSTEM_ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_ENVIRONMENT_BEAN_NAME, getEnvironment().getSystemEnvironment());
}
}
详细分析下代码发现上面函数主要是在以下方法进行了扩展: (1)对SPEL语言的支持 (2)增加对属性编辑器的支持 (3)增加对一些内置类的支持,如EnvironmentAware、MessageSourceAware的注入 (4)设置了依赖功能可忽略的接口 (5)注册一些固定依赖的属性 (6)增加了AspectJ的支持 (7)将相关环境变量及属性以单例模式注册
注册BeanPostProcessor
在上文中提到了BeanFactoryPostProcessor的调用,接下来我们就探索下BeanPostProcessor。但这里并不是调用,而是注册,真正的调用其实是在bean的实例化阶段进行的,这是一个很重要的步骤,也是很多功能BeanFactory不知道的重要原因。spring中大部分功能都是通过后处理器的方式进行扩展的,这是spring框架的一个特写,但是在BeanFactory中其实并没有实现后处理器的自动注册,所以在调用的时候如果没有进行手动注册其实是不能使用的。但是ApplicationContext中却添加了自动注册功能,如自定义一个后处理器:
public class MyInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("befor");
return null;
}
}
然后在配置文件中添加bean的配置:
<bean class="com.demo.myspring.demo.applicationcontext.MyInstantiationAwareBeanPostProcessor"/>
激活BeanFactoryPostProcessor
在了解BeanFactoryPostProcessor的用法后我们便可以深入的研究BeanFactoryPostProcessor的调用过程了,其是在方法invokeBeanFactoryPostProcessors(beanFactory)中实现的,进入到方法内部:
public static void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
// 1、首先调用BeanDefinitionRegistryPostProcessors
Set<String> processedBeans = new HashSet<>();
// beanFactory是BeanDefinitionRegistry类型
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
// 定义BeanFactoryPostProcessor
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
// 定义BeanDefinitionRegistryPostProcessor集合
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
// 循环手动注册的beanFactoryPostProcessors
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
// 如果是BeanDefinitionRegistryPostProcessor的实例话,则调用其postProcessBeanDefinitionRegistry方法,对bean进行注册操作
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
// 如果是BeanDefinitionRegistryPostProcessor类型,则直接调用其postProcessBeanDefinitionRegistry
BeanDefinitionRegistryPostProcessor registryProcessor = (BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
// 否则则将其当做普通的BeanFactoryPostProcessor处理,直接加入regularPostProcessors集合,以备后续处理
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
// 首先调用实现了PriorityOrdered(有限排序接口)的BeanDefinitionRegistryPostProcessors
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
// 排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 加入registryProcessors集合
registryProcessors.addAll(currentRegistryProcessors);
// 调用所有实现了PriorityOrdered的的BeanDefinitionRegistryPostProcessors的postProcessBeanDefinitionRegistry方法,注册bean
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
// 清空currentRegistryProcessors,以备下次使用
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
// 其次,调用实现了Ordered(普通排序接口)的BeanDefinitionRegistryPostProcessors
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
// 排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 加入registryProcessors集合
registryProcessors.addAll(currentRegistryProcessors);
// 调用所有实现了PriorityOrdered的的BeanDefinitionRegistryPostProcessors的postProcessBeanDefinitionRegistry方法,注册bean
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
// 清空currentRegistryProcessors,以备下次使用
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
// 最后,调用其他的BeanDefinitionRegistryPostProcessors
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
// 排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 加入registryProcessors集合
registryProcessors.addAll(currentRegistryProcessors);
// 调用其他的BeanDefinitionRegistryPostProcessors的postProcessBeanDefinitionRegistry方法,注册bean
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
// 清空currentRegistryProcessors,以备下次使用
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
// 调用所有BeanDefinitionRegistryPostProcessor(包括手动注册和通过配置文件注册)
// 和BeanFactoryPostProcessor(只有手动注册)的回调函数-->postProcessBeanFactory
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
// 2、如果不是BeanDefinitionRegistry的实例,那么直接调用其回调函数即可-->postProcessBeanFactory
else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// 3、上面的代码已经处理完了所有的BeanDefinitionRegistryPostProcessors和手动注册的BeanFactoryPostProcessor
// 接下来要处理通过配置文件注册的BeanFactoryPostProcessor
// 首先获取所有的BeanFactoryPostProcessor(注意:这里获取的集合会包含BeanDefinitionRegistryPostProcessors)
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered, Ordered, and the rest.
// 这里,将实现了PriorityOrdered,Ordered的处理器和其他的处理器区分开来,分别进行处理
// PriorityOrdered有序处理器
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
// Ordered有序处理器
List<String> orderedPostProcessorNames = new ArrayList<>();
// 无序处理器
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
// 判断processedBeans是否包含当前处理器(processedBeans中的处理器已经被处理过);如果包含,则不做任何处理
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
// 加入到PriorityOrdered有序处理器集合
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
// 加入到Ordered有序处理器集合
orderedPostProcessorNames.add(ppName);
}
else {
// 加入到无序处理器集合
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
// 首先调用实现了PriorityOrdered接口的处理器
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
// 其次,调用实现了Ordered接口的处理器
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
// 最后,调用无序处理器
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
// 清理元数据
beanFactory.clearMetadataCache();
}
循环遍历 BeanFactoryPostProcessor 中的 postProcessBeanFactory 方法
private static void invokeBeanFactoryPostProcessors(
Collection<? extends BeanFactoryPostProcessor> postProcessors, ConfigurableListableBeanFactory beanFactory) {
for (BeanFactoryPostProcessor postProcessor : postProcessors) {
postProcessor.postProcessBeanFactory(beanFactory);
}
}
注册BeanPostProcessor
在上文中提到了BeanFactoryPostProcessor的调用,接下来我们就探索下BeanPostProcessor。但这里并不是调用,而是注册,真正的调用其实是在bean的实例化阶段进行的,这是一个很重要的步骤,也是很多功能BeanFactory不知道的重要原因。spring中大部分功能都是通过后处理器的方式进行扩展的,这是spring框架的一个特写,但是在BeanFactory中其实并没有实现后处理器的自动注册,所以在调用的时候如果没有进行手动注册其实是不能使用的。但是ApplicationContext中却添加了自动注册功能,如自定义一个后处理器:
public class MyInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("befor");
return null;
}
}
然后在配置文件中添加bean的配置:
<bean class="com.demo.myspring.demo.applicationcontext.MyInstantiationAwareBeanPostProcessor"/>
这样的话再使用BeanFactory的方式进行加载的bean在加载时不会有任何改变的,而在使用ApplicationContext方式获取的bean时就会打印出“before”,而这个特性就是咋registryBeanPostProcessor方法中完成的。 我们继续深入分析registryBeanPostProcessors的方法实现:
protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory) {
PostProcessorRegistrationDelegate.registerBeanPostProcessors(beanFactory, this);
}
public static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, AbstractApplicationContext applicationContext) {
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanPostProcessor.class, true, false);
/*
* BeanPostProcessorChecker是一个普通的信息打印,可能会有些情况当spring的配置中的后
* 处理器还没有被注册就已经开了bean的初始化,这时就会打印出BeanPostProcessorChecker中
* 设定的信息
*/
int beanProcessorTargetCount = beanFactory.getBeanPostProcessorCount() + 1 + postProcessorNames.length;
beanFactory.addBeanPostProcessor(new BeanPostProcessorChecker(beanFactory, beanProcessorTargetCount));
//使用PriorityOrdered来保证顺序
List<BeanPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<BeanPostProcessor> internalPostProcessors = new ArrayList<>();
//使用Ordered来保证顺序
List<String> orderedPostProcessorNames = new ArrayList<>();
//无序BeanPostProcessor
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
priorityOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
//第一步,注册所有实现了PriorityOrdered的BeanPostProcessor
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors);
//注册实现了Ordered的BeanPostProcessor
List<BeanPostProcessor> orderedPostProcessors = new ArrayList<>();
for (String ppName : orderedPostProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
orderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
sortPostProcessors(orderedPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, orderedPostProcessors);
//注册所有的无序的BeanPostProcessor
List<BeanPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String ppName : nonOrderedPostProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
nonOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors);
//注册所有的内部BeanFactoryProcessor
sortPostProcessors(internalPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, internalPostProcessors);
// Re-register post-processor for detecting inner beans as ApplicationListeners,
//添加ApplicationListener探测器
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(applicationContext));
}
我们可以看到先从容器中获取所有类型为 BeanPostProcessor.class 的Bean的name数组,然后通过 BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class); 获取Bean的实例,最后通过 registerBeanPostProcessors(beanFactory, orderedPostProcessors);将获取到的BeanPostProcessor实例添加到容器的属性中,如下
private static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanPostProcessor> postProcessors) {
for (BeanPostProcessor postProcessor : postProcessors) {
beanFactory.addBeanPostProcessor(postProcessor);
}
}
@Override
public void addBeanPostProcessor(BeanPostProcessor beanPostProcessor) {
Assert.notNull(beanPostProcessor, "BeanPostProcessor must not be null");
// Remove from old position, if any
this.beanPostProcessors.remove(beanPostProcessor);
// Track whether it is instantiation/destruction aware
if (beanPostProcessor instanceof InstantiationAwareBeanPostProcessor) {
this.hasInstantiationAwareBeanPostProcessors = true;
}
if (beanPostProcessor instanceof DestructionAwareBeanPostProcessor) {
this.hasDestructionAwareBeanPostProcessors = true;
}
// Add to end of list
this.beanPostProcessors.add(beanPostProcessor);
}
可以看到将 beanPostProcessor 实例添加到容器的 beanPostProcessors 属性中
初始化Message资源
初始事件广播器
初始化ApplicationEventMulticaster是在方法initApplicationEventMulticaster()中实现的,进入到方法体,如下:
protected void initApplicationEventMulticaster() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
// 1、默认使用内置的事件广播器,如果有的话.
// 我们可以在配置文件中配置Spring事件广播器或者自定义事件广播器
// 例如: <bean id="applicationEventMulticaster" class="org.springframework.context.event.SimpleApplicationEventMulticaster"></bean>
if (beanFactory.containsLocalBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME)) {
this.applicationEventMulticaster = beanFactory.getBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, ApplicationEventMulticaster.class);
}
// 2、否则,新建一个事件广播器,SimpleApplicationEventMulticaster是spring的默认事件广播器
else {
this.applicationEventMulticaster = new SimpleApplicationEventMulticaster(beanFactory);
beanFactory.registerSingleton(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, this.applicationEventMulticaster);
}
}
通过源码可以看到其实现逻辑与initMessageSource基本相同,其步骤如下: (1)查找是否有name为applicationEventMulticaster的bean,如果有放到容器里,如果没有,初始化一个系统默认的SimpleApplicationEventMulticaster放入容器 (2)查找手动设置的applicationListeners,添加到applicationEventMulticaster里 (3)查找定义的类型为ApplicationListener的bean,设置到applicationEventMulticaster (4)初始化完成、对earlyApplicationEvents里的事件进行通知(此容器仅仅是广播器未建立的时候保存通知信息,一旦容器建立完成,以后均直接通知) (5)在系统操作时候,遇到的各种bean的通知事件进行通知 可以看到的是applicationEventMulticaster是一个标准的观察者模式,对于他内部的监听者applicationListeners,每次事件到来都会一一获取通知。
注册监听器
protected void registerListeners() {
// Register statically specified listeners first.
// 首先,注册指定的静态事件监听器,在spring boot中有应用
for (ApplicationListener<?> listener : getApplicationListeners()) {
getApplicationEventMulticaster().addApplicationListener(listener);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let post-processors apply to them!
// 其次,注册普通的事件监听器
String[] listenerBeanNames = getBeanNamesForType(ApplicationListener.class, true, false);
for (String listenerBeanName : listenerBeanNames) {
getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName);
}
// Publish early application events now that we finally have a multicaster...
// 如果有早期事件的话,在这里进行事件广播
// 因为前期SimpleApplicationEventMulticaster尚未注册,无法发布事件,
// 因此早期的事件会先存放在earlyApplicationEvents集合中,这里把它们取出来进行发布
// 所以早期事件的发布时间节点是早于其他事件的
Set<ApplicationEvent> earlyEventsToProcess = this.earlyApplicationEvents;
// 早期事件广播器是一个Set<ApplicationEvent>集合,保存了无法发布的早期事件,当SimpleApplicationEventMulticaster
// 创建完之后随即进行发布,同事也要将其保存的事件释放
this.earlyApplicationEvents = null;
if (earlyEventsToProcess != null) {
for (ApplicationEvent earlyEvent : earlyEventsToProcess) {
getApplicationEventMulticaster().multicastEvent(earlyEvent);
}
}
}
初始化其他的单例Bean(非延迟加载的)
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// Initialize conversion service for this context.
// 判断有无ConversionService(bean属性类型转换服务接口),并初始化
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME)
&& beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
//
// Register a default embedded value resolver if no bean post-processor
// (such as a PropertyPlaceholderConfigurer bean) registered any before:
// at this point, primarily for resolution in annotation attribute values.
// 如果beanFactory中不包含EmbeddedValueResolver,则向其中添加一个EmbeddedValueResolver
// EmbeddedValueResolver-->解析bean中的占位符和表达式
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// Initialize LoadTimeWeaverAware beans early to allow for registering their transformers early.
// 初始化LoadTimeWeaverAware类型的bean
// LoadTimeWeaverAware-->加载Spring Bean时织入第三方模块,如AspectJ
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
// 释放临时类加载器
beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes.
// 冻结缓存的BeanDefinition元数据
beanFactory.freezeConfiguration();
// Instantiate all remaining (non-lazy-init) singletons.
// 初始化其他的非延迟加载的单例bean
beanFactory.preInstantiateSingletons();
}
我们重点看 beanFactory.preInstantiateSingletons();
@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
getBean(beanName);
}
}
}
}
完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程,同时发出ContextRefreshEvent通知
protected void finishRefresh() {
// Clear context-level resource caches (such as ASM metadata from scanning).
// 清空资源缓存
clearResourceCaches();
// Initialize lifecycle processor for this context.
// 初始化生命周期处理器
initLifecycleProcessor();
// Propagate refresh to lifecycle processor first.
// 调用生命周期处理器的onRefresh方法
getLifecycleProcessor().onRefresh();
// Publish the final event.
// 推送容器刷新事件
publishEvent(new ContextRefreshedEvent(this));
// Participate in LiveBeansView MBean, if active.
LiveBeansView.registerApplicationContext(this);
}
其他内容
增加对SPEL语言的支持
Spring表达式语言全称为“Spring Expression Language”,缩写为“SpEL”,类似于Struts 2x中使用的OGNL语言,SpEL是单独模块,只依赖于core模块,不依赖于其他模块,可以单独使用。 SpEL使用#{…}作为定界符,所有在大框号中的字符都将被认为是SpEL,使用格式如下:
<util:properties id="database" location="classpath:db.properties">
</util:properties>
<bean id="dbcp" class="org.apache.commons.dbcp.BasicDataSource">
<property name="username" value="#{database.user}"></property>
<property name="password" value="#{database.pwd}"></property>
<property name="driverClassName" value="#{database.driver}"></property>
<property name="url" value="#{database.url}"></property>
</bean>
上面只是列举了其中最简单的使用方式,SpEL功能非常强大,使用好可以大大提高开发效率。在源码中通过代码beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver()),注册语言解析器,就可以对SpEL进行解析了,那么之后是在什么地方调用这个解析器的呢? 之前说beanFactory中说过Spring在bean进行初始化的时候会有属性填充的一步,而在这一步中Spring会调用AbstractAutowireCapabelBeanFactory类的applyPropertyValues来进行属性值得解析。同时这个步骤中一般通过AbstractBeanFactory中的evaluateBeanDefinitionString方法进行SpEL解析,方法代码如下:
protected Object evaluateBeanDefinitionString(String value, BeanDefinition beanDefinition) {
if (this.beanExpressionResolver == null) {
return value;
}
Scope scope = (beanDefinition != null ? getRegisteredScope(beanDefinition.getScope()) : null);
return this.beanExpressionResolver.evaluate(value, new BeanExpressionContext(this, scope));
}
PropertyPlaceholderConfigurer
有时候我们在阅读spring的配置文件中的Bean的描述时,会遇到类似如下情况:
<bean id="user" class="com.yhl.myspring.demo.applicationcontext.User">
<property name="name" value="${user.name}"/>
<property name="birthday" value="${user.birthday"/>
</bean>
这其中出现了变量:user.name、user.name、{user.birthday},这是spring的分散配置,可以在另外的配置文件中为user.name、user.birthday指定值,例如在bean.properties文件中定义:
user.name = xiaoming
user.birthday = 2019-04-19
当访问名为user的bean时,其name属性就会被字符串xiaoming替换,那spring框架是怎么知道存在这样的配置文件呢,这个就是PropertyPlaceholderConfigurer,需要在配置文件中添加一下代码:
<bean id="userHandler" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:bean.properties</value>
</list>
</property>
</bean>
在这个bean中指定了配置文件的位置。其实还是有个问题,这个userHandler只不过是spring框架管理的一个bean,并没有被别的bean或者对象引用,spring的beanFactory是怎么知道这个需要从这个bean中获取配置信息呢?我们看下PropertyPlaceholderConfigurer这个类的层次结构,如下图:
从上图中我们可以看到PropertyPlaceholderConfigurer间接的继承了BeanFactoryPostProcessor接口,这是一个很特别的接口,当spring加载任何实现了这个接口的bean的配置时,都会在bean工厂载入所有bean的配置之后执行postProcessBeanFactory方法。在PropertyResourceConfigurer类中实现了postProcessBeanFactory方法,在方法中先后调用了mergeProperties、convertProperties、processProperties这三个方法,分别得到配置,将得到的配置转换为合适的类型,最后将配置内容告知BeanFactory。 正是通过实现BeanFactoryPostProcessor接口,BeanFactory会在实例化任何bean之前获得配置信息,从而能够正确的解析bean描述文件中的变量引用。
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
try {
Properties mergedProps = this.mergeProperties();
this.convertProperties(mergedProps);
this.processProperties(beanFactory, mergedProps);
} catch (IOException var3) {
throw new BeanInitializationException("Could not load properties", var3);
}
}
自定义BeanFactoryPostProcessor
编写实现了BeanFactoryPostProcessor接口的MyBeanFactoryPostProcessor的容器后处理器,如下代码:
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("对容器进行后处理。。。。");
}
}
然后在配置文件中注册这个bean,如下:
<bean id="myPost" class="com.demo.myspring.demo.applicationcontext.MyBeanFactoryPostProcessor"></bean>
最后编写测试代码:
public class Test {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
User user = (User)context.getBean("user");
System.out.println(user.getName());
}
}
自定义监听器
定义监听事件
public class TestEvent extends ApplicationonEvent {
public String msg;
public TestEvent (Object source ) {
super (source );
}
public TestEvent (Object source , String msg ) {
super(source);
this.msg = msg ;
}
public void print () {
System.out.println(msg) ;
}
}
定义监昕器
public class TestListener implement ApplicationListener {
public void onApplicationEvent (ApplicationEvent event ) {
if (event instanceof TestEvent ) {
TestEvent testEvent = (TestEvent) event ;
testEvent print () ;
}
}
}
添加配置文件
<bean id=” testListener” class=” com.test.event.TestListener ” />
测试
@Test
public void MyAopTest() {
ApplicationContext ac = new ClassPathXmlApplicationContext("spring-aop.xml");
TestEvent event = new TestEvent (“hello” ,”msg”) ;
context.publishEvent(event);
}
源码分析
protected void publishEvent(Object event, ResolvableType eventType) {
Assert.notNull(event, "Event must not be null");
if (logger.isTraceEnabled()) {
logger.trace("Publishing event in " + getDisplayName() + ": " + event);
}
// Decorate event as an ApplicationEvent if necessary
ApplicationEvent applicationEvent;
//支持两种事件1、直接继承ApplicationEvent,2、其他时间,会被包装为PayloadApplicationEvent,可以使用getPayload获取真实的通知内容
if (event instanceof ApplicationEvent) {
applicationEvent = (ApplicationEvent) event;
}
else {
applicationEvent = new PayloadApplicationEvent<Object>(this, event);
if (eventType == null) {
eventType = ((PayloadApplicationEvent)applicationEvent).getResolvableType();
}
}
// Multicast right now if possible - or lazily once the multicaster is initialized
if (this.earlyApplicationEvents != null) {
//如果有预制行添加到预制行,预制行在执行一次后被置为null,以后都是直接执行
this.earlyApplicationEvents.add(applicationEvent);
}
else {
//广播event事件
getApplicationEventMulticaster().multicastEvent(applicationEvent, eventType);
}
// Publish event via parent context as well...
//父bean同样广播
if (this.parent != null) {
if (this.parent instanceof AbstractApplicationContext) {
((AbstractApplicationContext) this.parent).publishEvent(event, eventType);
}
else {
this.parent.publishEvent(event);
}
}
}
查找所有的监听者,依次遍历,如果有线程池,利用线程池进行发送,如果没有则直接发送,如果针对比较大的并发量,我们应该采用线程池模式,将发送通知和真正的业务逻辑进行分离
public void multicastEvent(final ApplicationEvent event, ResolvableType eventType) {
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
for (final ApplicationListener<?> listener : getApplicationListeners(event, type)) {
Executor executor = getTaskExecutor();
if (executor != null) {
executor.execute(new Runnable() {
@Override
public void run() {
invokeListener(listener, event);
}
});
}
else {
invokeListener(listener, event);
}
}
}
调用invokeListener
protected void invokeListener(ApplicationListener listener, ApplicationEvent event) {
ErrorHandler errorHandler = getErrorHandler();
if (errorHandler != null) {
try {
listener.onApplicationEvent(event);
}
catch (Throwable err) {
errorHandler.handleError(err);
}
}
else {
try {
listener.onApplicationEvent(event);
}
catch (ClassCastException ex) {
// Possibly a lambda-defined listener which we could not resolve the generic event type for
LogFactory.getLog(getClass()).debug("Non-matching event type for listener: " + listener, ex);
}
}
}
Spring之基于注解的源码
基于注解的Spring源码分析
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MainConfig.class);
创建AnnotationConfigApplicationContext对象,首先会跑到这里:
public class AnnotationConfigApplicationContext extends GenericApplicationContext implements AnnotationConfigRegistry {
//注解bean定义读取器,主要作用是用来读取被注解的了bean
private final AnnotatedBeanDefinitionReader reader;
//扫描器,它仅仅是在我们外部手动调用 .scan 等方法才有用,常规方式是不会用到scanner对象的
private final ClassPathBeanDefinitionScanner scanner;
public AnnotationConfigApplicationContext() {
//会隐式调用父类的构造方法,初始化DefaultListableBeanFactory
//初始化一个Bean读取器
StartupStep createAnnotatedBeanDefReader = this.getApplicationStartup().start("spring.context.annotated-bean-reader.create");
this.reader = new AnnotatedBeanDefinitionReader(this);
//初始化一个扫描器,它仅仅是在我们外部手动调用 .scan 等方法才有用,常规方式是不会用到scanner对象的
createAnnotatedBeanDefReader.end();
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
public AnnotationConfigApplicationContext(DefaultListableBeanFactory beanFactory) {
super(beanFactory);
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
//根据参数类型可以知道,其实可以传入多个annotatedClasses,但是这种情况出现的比较少
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
//调用无参构造函数,会先调用父类GenericApplicationContext的构造函数
//父类的构造函数里面就是初始化DefaultListableBeanFactory,并且赋值给beanFactory
//本类的构造函数里面,初始化了一个读取器:AnnotatedBeanDefinitionReader read,一个扫描器ClassPathBeanDefinitionScanner scanner
//scanner的用处不是很大,它仅仅是在我们外部手动调用 .scan 等方法才有用,常规方式是不会用到scanner对象的
this();
//把传入的类进行注册,这里有两个情况,
//传入传统的配置类
//传入bean(虽然一般没有人会这么做
//看到后面会知道spring把传统的带上@Configuration的配置类称之为FULL配置类,不带@Configuration的称之为Lite配置类
//但是我们这里先把带上@Configuration的配置类称之为传统配置类,不带的称之为普通bean
this.register(componentClasses);
//刷新
this.refresh();
}
public AnnotationConfigApplicationContext(String... basePackages) {
this();
this.scan(basePackages);
this.refresh();
}
public void setEnvironment(ConfigurableEnvironment environment) {
super.setEnvironment(environment);
this.reader.setEnvironment(environment);
this.scanner.setEnvironment(environment);
}
public void setBeanNameGenerator(BeanNameGenerator beanNameGenerator) {
this.reader.setBeanNameGenerator(beanNameGenerator);
this.scanner.setBeanNameGenerator(beanNameGenerator);
this.getBeanFactory().registerSingleton("org.springframework.context.annotation.internalConfigurationBeanNameGenerator", beanNameGenerator);
}
public void setScopeMetadataResolver(ScopeMetadataResolver scopeMetadataResolver) {
this.reader.setScopeMetadataResolver(scopeMetadataResolver);
this.scanner.setScopeMetadataResolver(scopeMetadataResolver);
}
public void register(Class<?>... componentClasses) {
Assert.notEmpty(componentClasses, "At least one component class must be specified");
StartupStep registerComponentClass = this.getApplicationStartup().start("spring.context.component-classes.register").tag("classes", () -> {
return Arrays.toString(componentClasses);
});
this.reader.register(componentClasses);
registerComponentClass.end();
}
public void scan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
StartupStep scanPackages = this.getApplicationStartup().start("spring.context.base-packages.scan").tag("packages", () -> {
return Arrays.toString(basePackages);
});
this.scanner.scan(basePackages);
scanPackages.end();
}
public <T> void registerBean(@Nullable String beanName, Class<T> beanClass, @Nullable Supplier<T> supplier, BeanDefinitionCustomizer... customizers) {
this.reader.registerBean(beanClass, beanName, supplier, customizers);
}
}
这个方法第一眼看上去,很简单,无非就是三行代码,但是这三行代码包含了大千世界。
我们先来为构造方法做一个简单的说明:
- 这是一个有参的构造方法,可以接收多个配置类,不过一般情况下,只会传入一个配置类。
- 这个配置类有两种情况,一种是传统意义上的带上@Configuration注解的配置类,还有一种是没有带上@Configuration,但是带有@Component,@Import,@ImportResouce,@Service,@ComponentScan等注解的配置类,在Spring内部把前者称为Full配置类,把后者称之为Lite配置类。在本源码分析中,有些地方也把Lite配置类称为普通Bean。
我们先来看一下第一行代码:通过this()调用此类无参的构造方法
首先映入眼帘的是reader和scanner,无参构造方法中就是对reader和scanner进行了实例化,reader的类型是AnnotatedBeanDefinitionReader,从字面意思就可以看出它是一个 “打了注解的Bean定义读取器”,scanner的类型是ClassPathBeanDefinitionScanner,其实这个字段并不重要,它仅仅是在我们外面手动调用.scan方法,或者调用参数为String的构造方法,传入需要扫描的包名,才会用到,像我们这样传入配置类是不会用到这个scanner对象的。
AnnotationConfigApplicationContext类是有继承关系的,会隐式调用父类的构造方法:
public class GenericApplicationContext extends AbstractApplicationContext implements BeanDefinitionRegistry {
private final DefaultListableBeanFactory beanFactory;
public GenericApplicationContext() {
this.beanFactory = new DefaultListableBeanFactory();
}
}
这个代码很简单,就是初始化了DefaultListableBeanFactory。
DefaultListableBeanFactory是相当重要的,从字面意思就可以看出它是一个Bean的工厂,什么是Bean的工厂?当然就是用来生产和获得Bean的。
让我们把目光回到AnnotationConfigApplicationContext的无参构造方法,让我们看看Spring在初始化AnnotatedBeanDefinitionReader的时候做了什么:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry) {
this(registry, getOrCreateEnvironment(registry));
}
这里的BeanDefinitionRegistry当然就是AnnotationConfigApplicationContext的实例了,这里又直接调用了此类其他的构造方法:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
让我们把目光移动到这个方法的最后一行,进入registerAnnotationConfigProcessors方法:
public static void registerAnnotationConfigProcessors(BeanDefinitionRegistry registry) {
registerAnnotationConfigProcessors(registry, null);
}
这又是一个门面方法,再点进去,这个方法的返回值Set,但是上游方法并没有去接收这个返回值,所以这个方法的返回值也不是很重要了,当然方法内部给这个返回值赋值也不重要了。由于这个方法内容比较多,这里就把最核心的贴出来,这个方法的核心就是注册Spring内置的多个Bean:
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
- 判断容器中是否已经存在了ConfigurationClassPostProcessor Bean
- 如果不存在(当然这里肯定是不存在的),就通过RootBeanDefinition的构造方法获得ConfigurationClassPostProcessor的BeanDefinition,RootBeanDefinition是BeanDefinition的子类:
3.执行registerPostProcessor方法,registerPostProcessor方法内部就是注册Bean,当然这里注册其他Bean也是一样的流程。
BeanDefinition是什么,顾名思义,它是用来描述Bean的,里面存放着关于Bean的一系列信息,比如Bean的作用域,Bean所对应的Class,是否懒加载,是否Primary等等,这个BeanDefinition也相当重要,我们以后会常常和它打交道。
registerPostProcessor方法:
private static BeanDefinitionHolder registerPostProcessor(
BeanDefinitionRegistry registry, RootBeanDefinition definition, String beanName) {
definition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(beanName, definition);
return new BeanDefinitionHolder(definition, beanName);
}
这方法为BeanDefinition设置了一个Role,ROLE_INFRASTRUCTURE代表这是spring内部的,并非用户定义的,然后又调用了registerBeanDefinition方法,再点进去,Oh No,你会发现它是一个接口,没办法直接点进去了,首先要知道registry实现类是什么,那么它的实现是什么呢?答案是DefaultListableBeanFactory:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
this.beanFactory.registerBeanDefinition(beanName, beanDefinition);
}
这又是一个门面方法,再点进去,核心在于下面两行代码:
//beanDefinitionMap是Map<String, BeanDefinition>,
//这里就是把beanName作为key,ScopedProxyMode作为value,推到map里面
this.beanDefinitionMap.put(beanName, beanDefinition);
//beanDefinitionNames就是一个List<String>,这里就是把beanName放到List中去
this.beanDefinitionNames.add(beanName);
从这里可以看出DefaultListableBeanFactory就是我们所说的容器了,里面放着beanDefinitionMap,beanDefinitionNames,beanDefinitionMap是一个hashMap,beanName作为Key,beanDefinition作为Value,beanDefinitionNames是一个集合,里面存放了beanName。
DefaultListableBeanFactory中的beanDefinitionMap,beanDefinitionNames也是相当重要的,以后会经常看到它,最好看到它,第一时间就可以反应出它里面放了什么数据
这里仅仅是注册,可以简单的理解为把一些原料放入工厂,工厂还没有真正的去生产。
上面已经介绍过,这里会一连串注册好几个Bean,在这其中最重要的一个Bean(没有之一)就是BeanDefinitionRegistryPostProcessor Bean。
ConfigurationClassPostProcessor实现BeanDefinitionRegistryPostProcessor接口,BeanDefinitionRegistryPostProcessor接口又扩展了BeanFactoryPostProcessor接口,BeanFactoryPostProcessor是Spring的扩展点之一,ConfigurationClassPostProcessor是Spring极为重要的一个类,必须牢牢的记住上面所说的这个类和它的继承关系。
除了注册了ConfigurationClassPostProcessor,还注册了其他Bean,其他Bean也都实现了其他接口,比如BeanPostProcessor等。
BeanPostProcessor接口也是Spring的扩展点之一。
至此,实例化AnnotatedBeanDefinitionReader reader分析完毕。
由于常规使用方式是不会用到AnnotationConfigApplicationContext里面的scanner的,所以这里就不看scanner是如何被实例化的了。
把目光回到最开始,再分析第二行代码:
register(annotatedClasses);
这里传进去的是一个数组,最终会循环调用如下方法:
<T> void doRegisterBean(Class<T> annotatedClass, @Nullable Supplier<T> instanceSupplier, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, BeanDefinitionCustomizer... definitionCustomizers) {
//AnnotatedGenericBeanDefinition可以理解为一种数据结构,是用来描述Bean的,这里的作用就是把传入的标记了注解的类
//转为AnnotatedGenericBeanDefinition数据结构,里面有一个getMetadata方法,可以拿到类上的注解
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(annotatedClass);
//判断是否需要跳过注解,spring中有一个@Condition注解,当不满足条件,这个bean就不会被解析
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(instanceSupplier);
//解析bean的作用域,如果没有设置的话,默认为单例
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
abd.setScope(scopeMetadata.getScopeName());
//获得beanName
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
//解析通用注解,填充到AnnotatedGenericBeanDefinition,解析的注解为Lazy,Primary,DependsOn,Role,Description
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
//限定符处理,不是特指@Qualifier注解,也有可能是Primary,或者是Lazy,或者是其他(理论上是任何注解,这里没有判断注解的有效性),如果我们在外面,以类似这种
//AnnotationConfigApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext(Appconfig.class);常规方式去初始化spring,
//qualifiers永远都是空的,包括上面的name和instanceSupplier都是同样的道理
//但是spring提供了其他方式去注册bean,就可能会传入了
if (qualifiers != null) {
//可以传入qualifier数组,所以需要循环处理
for (Class<? extends Annotation> qualifier : qualifiers) {
//Primary注解优先
if (Primary.class == qualifier) {
abd.setPrimary(true);
}
//Lazy注解
else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
}
//其他,AnnotatedGenericBeanDefinition有个Map<String,AutowireCandidateQualifier>属性,直接push进去
else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
for (BeanDefinitionCustomizer customizer : definitionCustomizers) {
customizer.customize(abd);
}
//这个方法用处不大,就是把AnnotatedGenericBeanDefinition数据结构和beanName封装到一个对象中
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
//注册,最终会调用DefaultListableBeanFactory中的registerBeanDefinition方法去注册,
//DefaultListableBeanFactory维护着一系列信息,比如beanDefinitionNames,beanDefinitionMap
//beanDefinitionNames是一个List<String>,用来保存beanName
//beanDefinitionMap是一个Map,用来保存beanName和beanDefinition
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
在这里又要说明下,以常规方式去注册配置类,此方法中除了第一个参数,其他参数都是默认值。
-
通过AnnotatedGenericBeanDefinition的构造方法,获得配置类的BeanDefinition,这里是不是似曾相似,在注册ConfigurationClassPostProcessor类的时候,也是通过构造方法去获得BeanDefinition的,只不过当时是通过RootBeanDefinition去获得,现在是通过AnnotatedGenericBeanDefinition去获得。
- 判断需不需要跳过注册,Spring中有一个@Condition注解,如果不满足条件,就会跳过这个类的注册。
- 然后是解析作用域,如果没有设置的话,默认为单例。
- 获得BeanName。
- 解析通用注解,填充到AnnotatedGenericBeanDefinition,解析的注解为Lazy,Primary,DependsOn,Role,Description。
- 限定符处理,不是特指@Qualifier注解,也有可能是Primary,或者是Lazy,或者是其他(理论上是任何注解,这里没有判断注解的有效性)。
- 把AnnotatedGenericBeanDefinition数据结构和beanName封装到一个对象中(这个不是很重要,可以简单的理解为方便传参)。
- 注册,最终会调用DefaultListableBeanFactory中的registerBeanDefinition方法去注册:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
//获取beanName
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
//注册bean
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
//Spring支持别名
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
这个registerBeanDefinition是不是又有一种似曾相似的感觉,没错,在上面注册Spring内置的Bean的时候,已经解析过这个方法了,这里就不重复了,此时,让我们再观察下beanDefinitionMap beanDefinitionNames两个变量,除了Spring内置的Bean,还有我们传进来的Bean,这里的Bean当然就是我们的配置类了
到这里注册配置类也分析完毕了。
大家可以看到其实到这里,Spring还没有进行扫描,只是实例化了一个工厂,注册了一些内置的Bean和我们传进去的配置类,真正的大头是在第三行代码:
refresh();
Spring之AOP
我们知道在面向对象OOP编程存在一些弊端,当需要为多个不具有继承关系的对象引入同一个公共行为时,例如日志,安全检测等,我们只有在每个对象里引入公共行为,这样程序中就产生了大量的重复代码,所以有了面向对象编程的补充,面向切面编程(AOP),AOP所关注的方向是横向的,不同于OOP的纵向。
AOP(Aspect Oriented Programming),即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。
面向切面是面向对象中的一种方式而已。在代码执行过程中,动态嵌入其他代码,叫做面向切面编程。常见的使用场景:日志,事务,数据库操作
面向切面编程的几个核心概念
| 概念 | 说明 |
|---|---|
| Aspect(切面) | 它是一个跨越多个类的模块化的关注点,它是通知(Advice)和切点(Pointcut)合起来的抽象,它定义了一个切点(Pointcut)用来匹配连接点(Join point),也就是需要对需要拦截的那些方法进行定义;它定义了一系列的通知(Advice)用来对拦截到的方法进行增强 |
| Weaving(织入) | 是将切面应用到目标对象的过程,这个过程可以是在编译时(例如使用 AspectJ 编译器),类加载时,运行时完成。Spring AOP 和其它纯 Java AOP 框架一样,是在运行时执行植入。 |
| Join point(连接点) | 程序执行期间的某一个点,例如执行方法或处理异常时候的点。在 Spring AOP 中,连接点总是表示方法的执行。 |
| Pointcut(切点) | 一个匹配连接点(Join point)的谓词表达式。通知(Advice)与切点表达式关联,并在切点匹配的任何连接点(Join point)(例如,执行具有特定名称的方法)上运行。切点是匹配连接点(Join point)的表达式的概念,是AOP的核心,并且 Spring 默认使用 AspectJ 作为切入点表达式语言。 |
| Advice(通知) | 通知是指一个切面在特定的连接点要做的事情。通知分为方法执行前通知,方法执行后通知,环绕通知等。许多 AOP 框架(包括 Spring)都将通知建模为拦截器,在连接点周围维护一系列拦截器(形成拦截器链),对连接点的方法进行增强。 |
| Advisor(顾问) | 这个概念是从 Spring 1.2的 AOP 支持中提出的,一个 Advisor 相当于一个小型的切面,不同的是它只有一个通知(Advice),Advisor 在事务管理里面会经常遇到,这个后面会讲到。 |
| Target object(目标对象) | 被一个或者多个切面(Aspect)通知的对象,也就是需要被 AOP 进行拦截对方法进行增强(使用通知)的对象,也称为被通知的对象。由于在 AOP 里面使用运行时代理,所以目标对象一直是被代理的对象。 |
| AOP proxy(AOP 代理) | 为了实现切面(Aspect)功能使用 AOP 框架创建一个对象,在 Spring 框架里面一个 AOP 代理要么指 JDK 动态代理,要么指 CgLIB 代理。 |
AOP的实现方式
| 通知类型 | 说明 |
|---|---|
| 前置通知(MethodBeforeAdvice) | 目标方法执行之前调用 |
| 后置通知(AfterReturningAdvice) | 目标方法执行完成之后调用 |
| 环绕通知(MethodInterceptor) | 目标方法执行前后都会调用方法,且能增强结果 |
| 异常处理通知(ThrowsAdvice) | 目标方法出现异常调用 |
整个 aspect 就可以描述为: 满足 pointcut 规则的 joinpoint 会被添加相应的 advice 操作.
接下来我们就详细分析下spring中的AOP。首先我们从动态AOP的使用开始。
AOP的使用
AOP之HelloWorld
在开始前,先引入Aspect。
<!-- aspectjweaver -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>${aspectj.version}</version>
</dependency>
创建用于拦截的bean
public class TestBean {
private String message = "test bean";
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public void test(){
System.out.println(this.message);
}
}
创建Advisor
Spring中摒弃了最原始的繁杂配置方式而采用@AspectJ注解对POJO进行标注,使AOP的工作大大简化,例如,在AspectJTest类中,我们要做的就是在所有类的test方法执行前在控制台beforeTest。而在所有类的test方法执行后打印afterTest,同时又使用环绕的方式在所有类的方法执行前后在此分别打印before1和after1,以下是AspectJTest的代码:
@Aspect
public class AspectJTest {
@Pointcut("execution(* *.test(..))")
public void test(){
}
@Before("test()")
public void beforeTest(){
System.out.println("beforeTest");
}
@Around("test()")
public Object aroundTest(ProceedingJoinPoint p){
System.out.println("around.....before");
Object o = null;
try{
o = p.proceed();
}catch(Throwable e){
e.printStackTrace();
}
System.out.println("around.....after");
return o;
}
@After("test()")
public void afterTest()
{
System.out.println("afterTest");
}
}
创建配置文件
要在Spring中开启AOP功能,,还需要在配置文件中作如下声明:
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd">
<aop:aspectj-autoproxy/>
<bean id="test" class="com.demo.myspring.demo.aop.TestBean">
<property name="message" value="这是一个苦逼的程序员"/>
</bean>
<bean id="aspect" class="com.demo.myspring.demo.aop.AspectJTest"/>
</beans>
测试
public class Test {
public static void main(String[] args) {
ApplicationContext bf = new ClassPathXmlApplicationContext("aspectTest.xml");
TestBean bean = (TestBean)bf.getBean("test");
bean.test();
}
}
执行后输出如下:
around.....before
beforeTest
这是一个苦逼的程序员
around.....after
afterTest
Spring实现了对所有类的test方法进行增强,使辅助功能可以独立于核心业务之外,方便与程序的扩展和解耦。
AOP注解实现
Spring是如何实现AOP的呢?Spring是否支持注解的AOP是由一个配置文件控制的,也就是<aop:aspectj-autoproxy/>,当在配置文件中声明了这句配置的时候,Spring就会支持注解的AOP,那么我们的分析就从这句注解开始。我们查看spring源码模块spring-aop
AOP自定义标签
对于AOP自定义标签,我们查看spring.handlers
http\://www.springframework.org/schema/aop=org.springframework.aop.config.AopNamespaceHandler
AopNamespaceHandler(AOP标签处理器)
AopNamespaceHandler这个类用于解析spring的配置文件中aop命名空间下的节点,默认注册下面的几个解析器。常用的是aspectj-autoproxy
public class AopNamespaceHandler extends NamespaceHandlerSupport {
public AopNamespaceHandler() {
}
public void init() {
// In 2.0 XSD as well as in 2.1 XSD.
this.registerBeanDefinitionParser("config", new ConfigBeanDefinitionParser());
this.registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser());
this.registerBeanDefinitionDecorator("scoped-proxy", new ScopedProxyBeanDefinitionDecorator());
// Only in 2.0 XSD: moved to context namespace as of 2.1
this.registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
}
}
从这段代码中我们可以得知,在解析配置文件的时候,一旦遇到了aspectj-autoproxy注解的时候会使用解析器AspectJAutoProxyBeanDefinitionParser进行解析,接下来我们就详细分析下其内部实现。
AspectJAutoProxyBeanDefinitionParser(AOP标签解析器)
所有解析器,因为都是对BeanDefinitionParser接口的统一实现,入口都是从parse函数开始的,AspectJAutoProxyBeanDefinitionParser的parse函数如下:
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 注册AnnotationAwareAspectJAutoProxyCreator
AopNamespaceUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(parserContext, element);
// 对于注解中子类的处理
extendBeanDefinition(element, parserContext);
return null;
}
通过代码可以了解到函数的具体逻辑是在registerAspectJAnnotationAutoProxyCreatorIfNecessary方法中实现的,继续进入到函数体内:
/**
* 注册AnnotationAwareAspectJAutoProxyCreator
* @param parserContext
* @param sourceElement
*/
public static void registerAspectJAnnotationAutoProxyCreatorIfNecessary(
ParserContext parserContext, Element sourceElement) {
// 注册或升级AutoProxyCreator定义beanName为org.springframework.aop.config.internalAutoProxyCreator的BeanDefinition
BeanDefinition beanDefinition = AopConfigUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(
parserContext.getRegistry(), parserContext.extractSource(sourceElement));
// 对于proxy-target-class以及expose-proxy属性的处理
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
// 注册组件并通知,便于监听器做进一步处理
registerComponentIfNecessary(beanDefinition, parserContext);
}
在registerAspectJAnnotationAutoProxyCreatorIfNeccessary方法中主要完成了3件事情,基本上每行代码都是一个完整的逻辑。接下来我们详细分析每一行代码。
注册或升级AnnotationAwareAspectJAutoProxyCreator(基于注解的AOP生成器)
对于AOP的实现,基本上都是靠AnnotationAwareAspectJAutoProxyCreator去完成,它可以根据@Point注解定义的切点来自动代理相匹配的bean。但是为了配置简便,Spring使用了自定义配置来帮助我们自动注册AnnotationAwareAspectJAutoProxyCreator,其注册过程就是在这里实现的。我们继续跟进到方法内部:
public static BeanDefinition registerAspectJAnnotationAutoProxyCreatorIfNecessary(BeanDefinitionRegistry registry,
@Nullable Object source) {
return registerOrEscalateApcAsRequired(AnnotationAwareAspectJAutoProxyCreator.class, registry, source);
}
public static final String AUTO_PROXY_CREATOR_BEAN_NAME = "org.springframework.aop.config.internalAutoProxyCreator";
private static BeanDefinition registerOrEscalateApcAsRequired(Class<?> cls, BeanDefinitionRegistry registry,
@Nullable Object source) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
//如果已经存在了自动代理创建器且存在的自动代理创建器与现在的不一致那么需要根据优先级来判断到底需要使用哪个
if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) {
BeanDefinition apcDefinition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME);
if (!cls.getName().equals(apcDefinition.getBeanClassName())) {
int currentPriority = findPriorityForClass(apcDefinition.getBeanClassName());
int requiredPriority = findPriorityForClass(cls);
if (currentPriority < requiredPriority) {
//改变bean最重要的就是改变bean所对应的className属性
apcDefinition.setBeanClassName(cls.getName());
}
}
return null;
}
//注册beanDefinition,Class为AnnotationAwareAspectJAutoProxyCreator.class,beanName为internalAutoProxyCreator
RootBeanDefinition beanDefinition = new RootBeanDefinition(cls);
beanDefinition.setSource(source);
beanDefinition.getPropertyValues().add("order", Ordered.HIGHEST_PRECEDENCE);
beanDefinition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME, beanDefinition);
return beanDefinition;
}
以上代码实现了自动注册AnnotationAwareAspectJAutoProxyCreator类的功能,同时这里还涉及了一个优先级的问题,如果已经存在了自动代理创建器,而且存在的自动代理创建器与现在的不一致,那么需要根据优先级来判断到底需要使用哪个。
处理proxy-target-class以及expose-proxy属性
useClassProxyingIfNecessary实现了proxy-target-class属性以及expose-proxy属性的处理,进入到方法内部:
private static void useClassProxyingIfNecessary(BeanDefinitionRegistry registry, @Nullable Element sourceElement) {
if (sourceElement != null) {
//实现了对proxy-target-class的处理
boolean proxyTargetClass = Boolean.parseBoolean(sourceElement.getAttribute(PROXY_TARGET_CLASS_ATTRIBUTE));
if (proxyTargetClass) {
AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry);
}
//对expose-proxy的处理
boolean exposeProxy = Boolean.parseBoolean(sourceElement.getAttribute(EXPOSE_PROXY_ATTRIBUTE));
if (exposeProxy) {
AopConfigUtils.forceAutoProxyCreatorToExposeProxy(registry);
}
}
}
在上述代码中用到了两个强制使用的方法,强制使用的过程其实也是一个属性设置的过程,两个函数的方法如下:
public static void forceAutoProxyCreatorToUseClassProxying(BeanDefinitionRegistry registry) {
if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) {
BeanDefinition definition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME);
definition.getPropertyValues().add("proxyTargetClass", Boolean.TRUE);
}
}
public static void forceAutoProxyCreatorToExposeProxy(BeanDefinitionRegistry registry) {
if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) {
BeanDefinition definition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME);
definition.getPropertyValues().add("exposeProxy", Boolean.TRUE);
}
}
- proxy-target-class:Spring AOP部分使用JDK动态代理或者CGLIB来为目标对象创建代理。(建议尽量使用JDK的动态代理),如果被代理的目标对象实现了至少一个接口, 則会使用JDK动态代理。所有该目标类型实现的接口都将被代理。若该目标对象没有实现任何接口,则创建一个CGLIB代理。如果你希望强制使用CGLIB代理,(例如希望代理目标对象的所有方法,而不只是实现自接口的方法)那也可以。但是需要考虑以下两个问题。
- 无法通知(advise) Final方法,因为它们不能被覆写。
- 你需要将CGLIB二进制发行包放在classpath下面。
与之相较,JDK本身就提供了动态代理,强制使用CGLIB代理需要将aop:config的 proxy-target-class 厲性设为 true:
<aop:config proxy-target-class = "true">...</aop:config>
当需要使用CGLIB代理和@AspectJ自动代理支持,可以按照以下方式设罝
<aop:aspectj-autoproxy proxy-target-class = "true"/>
- JDK动态代理:其代理对象必须是某个接口的实现,它是通过在运行期间创建一个接口的实现类来完成对目标对象的代理。
- CGIJB代理:实现原理类似于JDK动态代理,只是它在运行期间生成的代理对象是针对目标类扩展的子类。CGLIB是高效的代码生成包,底层是依靠ASM (开源的Java字节码编辑类库)操作字节码实现的,性能比JDK强。
- expose-proxy:有时候目标对象内部的自我调用将无法实施切面中的增强,如下示例:
public interface AService {
public void a();
public void b();
}
@Service()
public class AServicelmpll implements AService {
@Transactional(propagation = Propagation.REQUIRED)
public void a() {
this.b{);
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void b() {
}
}
此处的this指向目标对象,因此调用this.b()将不会执行b事务切面,即不会执行事务增强, 因此 b 方法的事务定义“@Transactional(propagation = Propagation.REQUIRES_NEW)” 将不会实施,为了解决这个问题,我们可以这样做:
<aop:aspectj-autoproxy expose-proxy = "true"/>
然后将以上代码中的 “this.b();” 修改为 “((AService) AopContext.currentProxy()).b();” 即可。 通过以上的修改便可以完成对a和b方法的同时增强。
创建AOP代理之获取增强器
通过自定义配置完成了对AnnotationAwareAspectJAutoProxyCreator类型的自动注册,那么这个类到底做了什么工作来完成AOP的操作呢?首先我们看看AnnotationAwareAspectJAutoProxyCreator的层次结构,如下图所示:

从上图的类层次结构图中我们看到这个类实现了BeanPostProcessor接口,而实现BeanPostProcessor后,当Spring加载这个Bean时会在实例化前调用其postProcesssAfterIntialization方法,而我们对于AOP逻辑的分析也由此开始。 首先看下其父类AbstractAutoProxyCreator中的postProcessAfterInitialization方法:
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) throws BeansException {
if (bean != null) {
//根据给定的bean的class和name构建出个key,格式:beanClassName_beanName
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
//如果它适合被代理,则需要封装指定bean
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
在上面的代码中用到了方法wrapIfNecessary,继续跟踪到方法内部:
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 如果已经处理过
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
// 无需增强
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
// 给定的bean类是否代表一个基础设施类,基础设施类不应代理,或者配置了指定bean不需要自动代理
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
// 如果存在增强方法则创建代理
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
// 如果获取到了增强则需要针对增强创建代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 创建代理
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
函数中我们已经看到了代理创建的雏形。当然,真正开始之前还需要经过一些判断,比如是否已经处理过或者是否是需要跳过的bean,而真正创建代理的代码是从getAdvicesAndAdvisorsForBean开始的。 创建代理主要包含了两个步骤: (1)获取增强方法或者增强器; (2)根据获取的增强进行代理。
其中逻辑复杂,我们首先来看看获取增强方法的实现逻辑。是在AbstractAdvisorAutoProxyCreator中实现的,代码如下:
AbstractAdvisorAutoProxyCreator
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
List<Advisor> candidateAdvisors = findCandidateAdvisors();
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
对于指定bean的增强方法的获取一定是包含两个步骤的,获取所有的增强以及寻找所有增强中使用于bean的增强并应用,那么findCandidateAdvisors与findAdvisorsThatCanApply便是做了这两件事情。当然,如果无法找到对应的增强器便返回DO_NOT_PROXY,其中DO_NOT_PROXY=null。
获取增强器
由于我们分析的是使用注解进行的AOP,所以对于findCandidateAdvisors的实现其实是由AnnotationAwareAspectJAutoProxyCreator类完成的,我们继续跟踪AnnotationAwareAspectJAutoProxyCreator的findCandidateAdvisors方法。代码如下
@Override
protected List<Advisor> findCandidateAdvisors() {
// Add all the Spring advisors found according to superclass rules.
// 当使用注解方式配置AOP的时候并不是丢弃了对XML配置的支持,
// 在这里调用父类方法加载配置文件中的AOP声明
List<Advisor> advisors = super.findCandidateAdvisors();
// Build Advisors for all AspectJ aspects in the bean factory.
if (this.aspectJAdvisorsBuilder != null) {
advisors.addAll(this.aspectJAdvisorsBuilder.buildAspectJAdvisors());
}
return advisors;
}
AnnotationAwareAspectJAutoProxyCreator间接继承了AbstractAdvisorAutoProxyCreator,在实现获取增强的方法中除了保留父类的获取配置文件中定义的增强外,同时添加了获取Bean的注解增强的功能,那么其实现正是由this.aspectJAdvisorsBuilder.buildAspectJAdvisors()来实现的。 在真正研究代码之前读者可以尝试着自己去想象一下解析思路,看看自己的实现与Spring是否有差别呢?
(1)获取所有beanName,这一步骤中所有在beanFactory中注册的Bean都会被提取出来。 (2)遍历所有beanName,并找出声明AspectJ注解的类,进行进一步的处理。 (3)对标记为AspectJ注解的类进行增强器的提取。 (4)将提取结果加入缓存。
public List<Advisor> buildAspectJAdvisors() {
List<String> aspectNames = this.aspectBeanNames;
if (aspectNames == null) {
synchronized (this) {
aspectNames = this.aspectBeanNames;
if (aspectNames == null) {
List<Advisor> advisors = new ArrayList<>();
aspectNames = new ArrayList<>();
// 获取所有的beanName
String[] beanNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Object.class, true, false);
// 循环所有的beanName找出对应的增强方法
for (String beanName : beanNames) {
// 不合法的bean则略过,由子类定义规则,默认返回true
if (!isEligibleBean(beanName)) {
continue;
}
// We must be careful not to instantiate beans eagerly as in this case they
// would be cached by the Spring container but would not have been weaved.
// 获取对应的bean的Class类型
Class<?> beanType = this.beanFactory.getType(beanName);
if (beanType == null) {
continue;
}
// 如果存在Aspect注解
if (this.advisorFactory.isAspect(beanType)) {
aspectNames.add(beanName);
AspectMetadata amd = new AspectMetadata(beanType, beanName);
if (amd.getAjType().getPerClause().getKind() == PerClauseKind.SINGLETON) {
MetadataAwareAspectInstanceFactory factory =
new BeanFactoryAspectInstanceFactory(this.beanFactory, beanName);
// 解析标记Aspect注解中的增强方法
List<Advisor> classAdvisors = this.advisorFactory.getAdvisors(factory);
if (this.beanFactory.isSingleton(beanName)) {
//将增强器存入缓存中,下次可以直接取
this.advisorsCache.put(beanName, classAdvisors);
}
else {
this.aspectFactoryCache.put(beanName, factory);
}
advisors.addAll(classAdvisors);
}
else {
// Per target or per this.
if (this.beanFactory.isSingleton(beanName)) {
throw new IllegalArgumentException("Bean with name '" + beanName +
"' is a singleton, but aspect instantiation model is not singleton");
}
MetadataAwareAspectInstanceFactory factory =
new PrototypeAspectInstanceFactory(this.beanFactory, beanName);
this.aspectFactoryCache.put(beanName, factory);
advisors.addAll(this.advisorFactory.getAdvisors(factory));
}
}
}
this.aspectBeanNames = aspectNames;
return advisors;
}
}
}
if (aspectNames.isEmpty()) {
return Collections.emptyList();
}
// 记录在缓存中
List<Advisor> advisors = new ArrayList<>();
for (String aspectName : aspectNames) {
List<Advisor> cachedAdvisors = this.advisorsCache.get(aspectName);
if (cachedAdvisors != null) {
advisors.addAll(cachedAdvisors);
}
else {
MetadataAwareAspectInstanceFactory factory = this.aspectFactoryCache.get(aspectName);
advisors.addAll(this.advisorFactory.getAdvisors(factory));
}
}
return advisors;
}
至此,我们已经完成了Advisor的提取,在上面的步骤中最为重要也最为繁杂的就是增强器的获取,而这一切功能委托给了getAdvisors方法去实现(this.advisorFactory.getAdvisors(factory))。
我们先来看看 this.advisorFactory.isAspect(beanType)
@Override
public boolean isAspect(Class<?> clazz) {
return (hasAspectAnnotation(clazz) && !compiledByAjc(clazz));
}
private boolean hasAspectAnnotation(Class<?> clazz) {
return (AnnotationUtils.findAnnotation(clazz, Aspect.class) != null);
}
@Nullable
private static <A extends Annotation> A findAnnotation(Class<?> clazz, Class<A> annotationType, Set<Annotation> visited) {
try {
//判断此Class 是否存在Aspect.class注解
A annotation = clazz.getDeclaredAnnotation(annotationType);
if (annotation != null) {
return annotation;
}
for (Annotation declaredAnn : getDeclaredAnnotations(clazz)) {
Class<? extends Annotation> declaredType = declaredAnn.annotationType();
if (!isInJavaLangAnnotationPackage(declaredType) && visited.add(declaredAnn)) {
annotation = findAnnotation(declaredType, annotationType, visited);
if (annotation != null) {
return annotation;
}
}
}
}
}
如果 bean 存在 Aspect.class注解,就可以获取此bean中的增强器了,接着我们来看看 **List
@Override
public List<Advisor> getAdvisors(MetadataAwareAspectInstanceFactory aspectInstanceFactory) {
// 获取标记为AspectJ的类
Class<?> aspectClass = aspectInstanceFactory.getAspectMetadata().getAspectClass();
// 获取标记为AspectJ的name
String aspectName = aspectInstanceFactory.getAspectMetadata().getAspectName();
validate(aspectClass);
// We need to wrap the MetadataAwareAspectInstanceFactory with a decorator
// so that it will only instantiate once.
MetadataAwareAspectInstanceFactory lazySingletonAspectInstanceFactory =
new LazySingletonAspectInstanceFactoryDecorator(aspectInstanceFactory);
List<Advisor> advisors = new ArrayList<>();
// 对aspectClass的每一个带有注解的方法进行循环(带有PointCut注解的方法除外),取得Advisor,并添加到集合里。
// (这是里应该是取得Advice,然后取得我们自己定义的切面类中PointCut,组合成Advisor)
for (Method method : getAdvisorMethods(aspectClass)) {
//将类中的方法封装成Advisor
Advisor advisor = getAdvisor(method, lazySingletonAspectInstanceFactory, advisors.size(), aspectName);
if (advisor != null) {
advisors.add(advisor);
}
}
// If it's a per target aspect, emit the dummy instantiating aspect.
if (!advisors.isEmpty() && lazySingletonAspectInstanceFactory.getAspectMetadata().isLazilyInstantiated()) {
Advisor instantiationAdvisor = new SyntheticInstantiationAdvisor(lazySingletonAspectInstanceFactory);
advisors.add(0, instantiationAdvisor);
}
// Find introduction fields.
for (Field field : aspectClass.getDeclaredFields()) {
Advisor advisor = getDeclareParentsAdvisor(field);
if (advisor != null) {
advisors.add(advisor);
}
}
return advisors;
}
普通增强器的获取
普通增强器的获取逻辑通过getAdvisor方法实现,实现步骤包括对切点的注解的获取以及根据注解信息生成增强。我们先来看看 getAdvisorMethods(aspectClass),这个方法,通过很巧妙的使用接口,定义一个匿名回调,把带有注解的Method都取得出来,放到集合里
private List<Method> getAdvisorMethods(Class<?> aspectClass) {
final List<Method> methods = new LinkedList<Method>();
ReflectionUtils.doWithMethods(aspectClass, new ReflectionUtils.MethodCallback() {
@Override
public void doWith(Method method) throws IllegalArgumentException {
// Exclude pointcuts
// 将没有使用Pointcut.class注解的方法加入到集合中
if (AnnotationUtils.getAnnotation(method, Pointcut.class) == null) {
methods.add(method);
}
}
});
Collections.sort(methods, METHOD_COMPARATOR);
return methods;
}
public static void doWithMethods(Class<?> clazz, MethodCallback mc, @Nullable MethodFilter mf) {
// Keep backing up the inheritance hierarchy.
// 通过反射获取类中所有的方法
Method[] methods = getDeclaredMethods(clazz);
//遍历所有的方法
for (Method method : methods) {
if (mf != null && !mf.matches(method)) {
continue;
}
try {
//调用函数体
mc.doWith(method);
}
catch (IllegalAccessException ex) {
throw new IllegalStateException("Not allowed to access method '" + method.getName() + "': " + ex);
}
}
if (clazz.getSuperclass() != null) {
doWithMethods(clazz.getSuperclass(), mc, mf);
}
else if (clazz.isInterface()) {
for (Class<?> superIfc : clazz.getInterfaces()) {
doWithMethods(superIfc, mc, mf);
}
}
}
普通增强器的获取逻辑通过 getAdvisor 方法来实现,实现步骤包括对切点的注解以及根据注解信息生成增强。
public Advisor getAdvisor(Method candidateAdviceMethod, MetadataAwareAspectInstanceFactory aif,
int declarationOrderInAspect, String aspectName) {
validate(aif.getAspectMetadata().getAspectClass());
// 获取PointCut信息(主要是PointCut里的表达式)
// 把Method对象也传进去的目的是,比较Method对象上的注解,是不是下面注解其中一个
// 如果不是,返回null;如果是,就把取得PointCut内容包装返回
// 被比较注解:Before.class, Around.class, After.class, AfterReturning.class, AfterThrowing.class, Pointcut.class
AspectJExpressionPointcut ajexp =
getPointcut(candidateAdviceMethod, aif.getAspectMetadata().getAspectClass());
if (ajexp == null) {
return null;
}
// 根据PointCut信息生成增强器
return new InstantiationModelAwarePointcutAdvisorImpl(
this, ajexp, aif, candidateAdviceMethod, declarationOrderInAspect, aspectName);
}
(1)切点信息的获取
所谓获取切点信息就是指定注解的表达式信息的获取,如@Before(“test()”)。
private AspectJExpressionPointcut getPointcut(Method candidateAdviceMethod, Class<?> candidateAspectClass) {
// 获取方法上的注解
// 比较Method对象上的注解,是不是下面注解其中一个,如果不是返回null
// 被比较注解:Before.class, Around.class, After.class, AfterReturning.class, AfterThrowing.class, Pointcut.class
AspectJAnnotation<?> aspectJAnnotation = AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(candidateAdviceMethod);
if (aspectJAnnotation == null) {
return null;
}
// 使用AspectJExpressionPointcut 实例封装获取的信息
AspectJExpressionPointcut ajexp = new AspectJExpressionPointcut(candidateAspectClass, new String[0], new Class<?>[0]);
// 提取得到的注解中的表达式如:
// @Pointcut("execution(* test.TestBean.*(..))")
ajexp.setExpression(aspectJAnnotation.getPointcutExpression());
return ajexp;
}
详细看下上面方法中使用到的方法findAspectJAnnotationOnMethod
protected static AspectJAnnotation<?> findAspectJAnnotationOnMethod(Method method) {
// 设置要查找的注解类,看看方法的上注解是不是这些注解其中之一
Class<?>[] classesToLookFor = new Class<?>[] {
Before.class, Around.class, After.class, AfterReturning.class, AfterThrowing.class, Pointcut.class};
for (Class<?> c : classesToLookFor) {
AspectJAnnotation<?> foundAnnotation = findAnnotation(method, (Class<Annotation>) c);
if (foundAnnotation != null) {
return foundAnnotation;
}
}
return null;
}
在上面方法中又用到了方法findAnnotation,继续跟踪代码:
// 获取指定方法上的注解并使用 AspectJAnnotation 封装
private static <A extends Annotation> AspectJAnnotation<A> findAnnotation(Method method, Class<A> toLookFor) {
A result = AnnotationUtils.findAnnotation(method, toLookFor);
if (result != null) {
return new AspectJAnnotation<A>(result);
}
else {
return null;
}
}
此方法的功能是获取指定方法上的注解并使用AspectJAnnotation封装。
(2)根据切点信息生成增强类
所有的增强都有Advisor实现类InstantiationModelAwarePontcutAdvisorImpl进行统一封装的。我们看下其构造函数:
public InstantiationModelAwarePointcutAdvisorImpl(AspectJAdvisorFactory af, AspectJExpressionPointcut ajexp,
MetadataAwareAspectInstanceFactory aif, Method method, int declarationOrderInAspect, String aspectName) {
this.declaredPointcut = ajexp;
this.method = method;
this.atAspectJAdvisorFactory = af;
this.aspectInstanceFactory = aif;
this.declarationOrder = declarationOrderInAspect;
this.aspectName = aspectName;
if (aif.getAspectMetadata().isLazilyInstantiated()) {
// Static part of the pointcut is a lazy type.
Pointcut preInstantiationPointcut =
Pointcuts.union(aif.getAspectMetadata().getPerClausePointcut(), this.declaredPointcut);
// Make it dynamic: must mutate from pre-instantiation to post-instantiation state.
// If it's not a dynamic pointcut, it may be optimized out
// by the Spring AOP infrastructure after the first evaluation.
this.pointcut = new PerTargetInstantiationModelPointcut(this.declaredPointcut, preInstantiationPointcut, aif);
this.lazy = true;
}
else {
// A singleton aspect.
// 初始化Advice
this.instantiatedAdvice = instantiateAdvice(this.declaredPointcut);
this.pointcut = declaredPointcut;
this.lazy = false;
}
}
通过对上面构造函数的分析,发现封装过程只是简单地将信息封装在类的实例中,所有的额信息单纯地复制。在实例初始化的过程中还完成了对于增强器的初始化。因为不同的增强所体现的逻辑是不同的,比如@Before(“test()”)与After(“test()”)标签的不同就是增强器增强的位置不同,所以就需要不同的增强器来完成不同的逻辑,而根据注解中的信息初始化对应的额增强器就是在instantiateAdvice函数中实现的,继续跟踪代码:
private Advice instantiateAdvice(AspectJExpressionPointcut pointcut) {
Advice advice = this.aspectJAdvisorFactory.getAdvice(this.aspectJAdviceMethod, pointcut,
this.aspectInstanceFactory, this.declarationOrder, this.aspectName);
return (advice != null ? advice : EMPTY_ADVICE);
}
@Override
@Nullable
public Advice getAdvice(Method candidateAdviceMethod, AspectJExpressionPointcut expressionPointcut,
MetadataAwareAspectInstanceFactory aspectInstanceFactory, int declarationOrder, String aspectName) {
Class<?> candidateAspectClass = aspectInstanceFactory.getAspectMetadata().getAspectClass();
validate(candidateAspectClass);
AspectJAnnotation<?> aspectJAnnotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(candidateAdviceMethod);
if (aspectJAnnotation == null) {
return null;
}
// If we get here, we know we have an AspectJ method.
// Check that it's an AspectJ-annotated class
if (!isAspect(candidateAspectClass)) {
throw new AopConfigException("Advice must be declared inside an aspect type: " +
"Offending method '" + candidateAdviceMethod + "' in class [" +
candidateAspectClass.getName() + "]");
}
if (logger.isDebugEnabled()) {
logger.debug("Found AspectJ method: " + candidateAdviceMethod);
}
AbstractAspectJAdvice springAdvice;
// 根据不同的注解类型封装不同的增强器
switch (aspectJAnnotation.getAnnotationType()) {
case AtBefore:
springAdvice = new AspectJMethodBeforeAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
break;
case AtAfter:
springAdvice = new AspectJAfterAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
break;
case AtAfterReturning:
springAdvice = new AspectJAfterReturningAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
AfterReturning afterReturningAnnotation = (AfterReturning) aspectJAnnotation.getAnnotation();
if (StringUtils.hasText(afterReturningAnnotation.returning())) {
springAdvice.setReturningName(afterReturningAnnotation.returning());
}
break;
case AtAfterThrowing:
springAdvice = new AspectJAfterThrowingAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
AfterThrowing afterThrowingAnnotation = (AfterThrowing) aspectJAnnotation.getAnnotation();
if (StringUtils.hasText(afterThrowingAnnotation.throwing())) {
springAdvice.setThrowingName(afterThrowingAnnotation.throwing());
}
break;
case AtAround:
springAdvice = new AspectJAroundAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
break;
case AtPointcut:
if (logger.isDebugEnabled()) {
logger.debug("Processing pointcut '" + candidateAdviceMethod.getName() + "'");
}
return null;
default:
throw new UnsupportedOperationException(
"Unsupported advice type on method: " + candidateAdviceMethod);
}
// Now to configure the advice...
springAdvice.setAspectName(aspectName);
springAdvice.setDeclarationOrder(declarationOrder);
String[] argNames = this.parameterNameDiscoverer.getParameterNames(candidateAdviceMethod);
if (argNames != null) {
springAdvice.setArgumentNamesFromStringArray(argNames);
}
springAdvice.calculateArgumentBindings();
return springAdvice;
}
从上述函数代码中可以看到,Spring会根据不同的注解生成不同的增强器,正如代码switch (aspectJAnnotation.getAnnotationType()),根据不同的类型来生成。例如AtBefore会对应AspectJMethodBeforeAdvice。在AspectJMethodBeforeAdvice中完成了增强逻辑,这里的 AspectJMethodBeforeAdvice 最后会被适配器封装成*MethodBeforeAdviceInterceptor,*下一篇文章中我们具体分析,具体看下其代码:
MethodBeforeAdviceInterceptor
public class MethodBeforeAdviceInterceptor implements MethodInterceptor, Serializable {
private MethodBeforeAdvice advice;
public MethodBeforeAdviceInterceptor(MethodBeforeAdvice advice) {
Assert.notNull(advice, "Advice must not be null");
this.advice = advice;
}
@Override
public Object invoke(MethodInvocation mi) throws Throwable {
this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis());
return mi.proceed();
}
}
其中的MethodBeforeAdvice代表着前置增强的AspectJMethodBeforeAdvice,跟踪before方法:
AspectJMethodBeforeAdvice.java
public class AspectJMethodBeforeAdvice extends AbstractAspectJAdvice implements MethodBeforeAdvice, Serializable {
public AspectJMethodBeforeAdvice(
Method aspectJBeforeAdviceMethod, AspectJExpressionPointcut pointcut, AspectInstanceFactory aif) {
super(aspectJBeforeAdviceMethod, pointcut, aif);
}
@Override
public void before(Method method, Object[] args, @Nullable Object target) throws Throwable {
//直接调用增强方法
invokeAdviceMethod(getJoinPointMatch(), null, null);
}
}
protected Object invokeAdviceMethod(
@Nullable JoinPointMatch jpMatch, @Nullable Object returnValue, @Nullable Throwable ex)
throws Throwable {
return invokeAdviceMethodWithGivenArgs(argBinding(getJoinPoint(), jpMatch, returnValue, ex));
}
protected Object invokeAdviceMethodWithGivenArgs(Object[] args) throws Throwable {
Object[] actualArgs = args;
if (this.aspectJAdviceMethod.getParameterCount() == 0) {
actualArgs = null;
}
try {
ReflectionUtils.makeAccessible(this.aspectJAdviceMethod);
// TODO AopUtils.invokeJoinpointUsingReflection
// 通过反射调用AspectJ注解类中的增强方法
return this.aspectJAdviceMethod.invoke(this.aspectInstanceFactory.getAspectInstance(), actualArgs);
}
catch (IllegalArgumentException ex) {
throw new AopInvocationException("Mismatch on arguments to advice method [" +
this.aspectJAdviceMethod + "]; pointcut expression [" +
this.pointcut.getPointcutExpression() + "]", ex);
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
invokeAdviceMethodWithGivenArgs方法中的aspectJAdviceMethod正是对与前置增强的方法,在这里实现了调用。
后置增强与前置增强有稍许不一致的地方。回顾之前讲过的前置增强,大致的结构是在拦截器链中放置MethodBeforeAdviceInterceptor,而在MethodBeforeAdviceInterceptor中又放置了AspectJMethodBeforeAdvice,并在调用invoke时首先串联调用。但是在后置增强的时候却不一样,没有提供中间的类,而是直接在拦截器中使用了中间的AspectJAfterAdvice,也就是直接实现了MethodInterceptor。
public class AspectJAfterAdvice extends AbstractAspectJAdvice
implements MethodInterceptor, AfterAdvice, Serializable {
public AspectJAfterAdvice(
Method aspectJBeforeAdviceMethod, AspectJExpressionPointcut pointcut, AspectInstanceFactory aif) {
super(aspectJBeforeAdviceMethod, pointcut, aif);
}
@Override
public Object invoke(MethodInvocation mi) throws Throwable {
try {
return mi.proceed();
}
finally {
// 激活增强方法
invokeAdviceMethod(getJoinPointMatch(), null, null);
}
}
@Override
public boolean isBeforeAdvice() {
return false;
}
@Override
public boolean isAfterAdvice() {
return true;
}
}
其他的几个增强器,留在下一篇文章中具体来看
寻找匹配的增强器
前面的函数中已经完成了所有增强器的解析,但是对于所有增强器来讲,并不一定都适用于当前的bean,还要挑取出适合的增强器,也就是满足我们配置的通配符的增强器。具体实现在findAdvisorsThatCanApply中。
protected List<Advisor> findAdvisorsThatCanApply(
List<Advisor> candidateAdvisors, Class<?> beanClass, String beanName) {
ProxyCreationContext.setCurrentProxiedBeanName(beanName);
try {
// 过滤已经得到的advisors
return AopUtils.findAdvisorsThatCanApply(candidateAdvisors, beanClass);
}
finally {
ProxyCreationContext.setCurrentProxiedBeanName(null);
}
}
继续看findAdvisorsThatCanApply:
public static List<Advisor> findAdvisorsThatCanApply(List<Advisor> candidateAdvisors, Class<?> clazz) {
if (candidateAdvisors.isEmpty()) {
return candidateAdvisors;
}
List<Advisor> eligibleAdvisors = new ArrayList<>();
// 首先处理引介增强
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor && canApply(candidate, clazz)) {
eligibleAdvisors.add(candidate);
}
}
boolean hasIntroductions = !eligibleAdvisors.isEmpty();
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor) {
// already processed
continue;
}
// 对于普通bean的处理
if (canApply(candidate, clazz, hasIntroductions)) {
eligibleAdvisors.add(candidate);
}
}
return eligibleAdvisors;
}
findAdvisorsThatCanApply函数的主要功能是寻找增强器中适用于当前class的增强器。引介增强与普通的增强的处理是不一样的,所以分开处理。而对于真正的匹配在canApply中实现。
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor) {
return ((IntroductionAdvisor) advisor).getClassFilter().matches(targetClass);
}
else if (advisor instanceof PointcutAdvisor) {
PointcutAdvisor pca = (PointcutAdvisor) advisor;
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
}
else {
// It doesn't have a pointcut so we assume it applies.
return true;
}
}
public static boolean canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions) {
Assert.notNull(pc, "Pointcut must not be null");
//通过Pointcut的条件判断此类是否能匹配
if (!pc.getClassFilter().matches(targetClass)) {
return false;
}
MethodMatcher methodMatcher = pc.getMethodMatcher();
if (methodMatcher == MethodMatcher.TRUE) {
// No need to iterate the methods if we're matching any method anyway...
return true;
}
IntroductionAwareMethodMatcher introductionAwareMethodMatcher = null;
if (methodMatcher instanceof IntroductionAwareMethodMatcher) {
introductionAwareMethodMatcher = (IntroductionAwareMethodMatcher) methodMatcher;
}
Set<Class<?>> classes = new LinkedHashSet<>();
if (!Proxy.isProxyClass(targetClass)) {
classes.add(ClassUtils.getUserClass(targetClass));
}
classes.addAll(ClassUtils.getAllInterfacesForClassAsSet(targetClass));
for (Class<?> clazz : classes) {
//反射获取类中所有的方法
Method[] methods = ReflectionUtils.getAllDeclaredMethods(clazz);
for (Method method : methods) {
//根据匹配原则判断该方法是否能匹配Pointcut中的规则,如果有一个方法能匹配,则返回true
if (introductionAwareMethodMatcher != null ?
introductionAwareMethodMatcher.matches(method, targetClass, hasIntroductions) :
methodMatcher.matches(method, targetClass)) {
return true;
}
}
}
return false;
}
首先判断bean是否满足切点的规则,如果能满足,则获取bean的所有方法,判断是否有方法能匹配规则,有方法匹配规则,就代表此 Advisor 能作用于该bean,然后将该Advisor加入 eligibleAdvisors 集合中。
我们以注解的规则来看看bean中的method是怎样匹配 Pointcut中的规则
AnnotationMethodMatcher
@Override
public boolean matches(Method method, Class<?> targetClass) {
if (matchesMethod(method)) {
return true;
}
// Proxy classes never have annotations on their redeclared methods.
if (Proxy.isProxyClass(targetClass)) {
return false;
}
// The method may be on an interface, so let's check on the target class as well.
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
return (specificMethod != method && matchesMethod(specificMethod));
}
private boolean matchesMethod(Method method) {
//可以看出判断该Advisor是否使用于bean中的method,只需看method上是否有Advisor的注解
return (this.checkInherited ? AnnotatedElementUtils.hasAnnotation(method, this.annotationType) :
method.isAnnotationPresent(this.annotationType));
}
至此,我们在后置处理器中找到了所有匹配Bean中的增强器,下一章讲解如何使用找到切面,来创建代理。
AOP代理的生成
在获取了所有对应bean的增强后,便可以进行代理的创建了。回到AbstractAutoProxyCreator的wrapIfNecessary方法中,如下所示:
1 protected static final Object[] DO_NOT_PROXY = null;
2
3 protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
4 if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
5 return bean;
6 }
7 if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
8 return bean;
9 }
10 if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
11 this.advisedBeans.put(cacheKey, Boolean.FALSE);
12 return bean;
13 }
14
15 // Create proxy if we have advice.
16 Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
17 if (specificInterceptors != DO_NOT_PROXY) {
18 this.advisedBeans.put(cacheKey, Boolean.TRUE);
19 Object proxy = createProxy(
20 bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
21 this.proxyTypes.put(cacheKey, proxy.getClass());
22 return proxy;
23 }
24
25 this.advisedBeans.put(cacheKey, Boolean.FALSE);
26 return bean;
27 }
我们上一篇文章分析完了第16行,获取到了所有对应bean的增强器,并获取到了此目标bean所有匹配的 Advisor,接下来我们要从第17行开始分析,如果 specificInterceptors 不为空,则要为当前bean创建代理类,接下来我们来看创建代理类的方法 createProxy:
protected Object createProxy(Class<?> beanClass, @Nullable String beanName,
@Nullable Object[] specificInterceptors, TargetSource targetSource) {
if (this.beanFactory instanceof ConfigurableListableBeanFactory) {
AutoProxyUtils.exposeTargetClass((ConfigurableListableBeanFactory) this.beanFactory, beanName, beanClass);
}
ProxyFactory proxyFactory = new ProxyFactory();
// 获取当前类中相关属性
proxyFactory.copyFrom(this);
if (!proxyFactory.isProxyTargetClass()) {
// 决定对于给定的bean是否应该使用targetClass而不是他的接口代理,
// 检査 proxyTargetClass 设置以及 preserveTargetClass 属性
if (shouldProxyTargetClass(beanClass, beanName)) {
proxyFactory.setProxyTargetClass(true);
}
else {
evaluateProxyInterfaces(beanClass, proxyFactory);
}
}
Advisor[] advisors = buildAdvisors(beanName, specificInterceptors);
// 加入增强器
proxyFactory.addAdvisors(advisors);
// 设置要代理的目标类
proxyFactory.setTargetSource(targetSource);
// 定制代理
customizeProxyFactory(proxyFactory);
// 用来控制代理工厂被配置之后,是否还允许修改通知。
// 缺省值是false (即在代理被配置之后,不允许修改代理的配置)。
proxyFactory.setFrozen(this.freezeProxy);
if (advisorsPreFiltered()) {
proxyFactory.setPreFiltered(true);
}
//真正创建代理的方法
return proxyFactory.getProxy(getProxyClassLoader());
}
@Override
public void setTargetSource(@Nullable TargetSource targetSource) {
this.targetSource = (targetSource != null ? targetSource : EMPTY_TARGET_SOURCE);
}
public void addAdvisors(Collection<Advisor> advisors) {
if (isFrozen()) {
throw new AopConfigException("Cannot add advisor: Configuration is frozen.");
}
if (!CollectionUtils.isEmpty(advisors)) {
for (Advisor advisor : advisors) {
if (advisor instanceof IntroductionAdvisor) {
validateIntroductionAdvisor((IntroductionAdvisor) advisor);
}
Assert.notNull(advisor, "Advisor must not be null");
this.advisors.add(advisor);
}
updateAdvisorArray();
adviceChanged();
}
}
从上面代码我们看到对于代理类的创建及处理spring是委托给了ProxyFactory处理的
创建代理
public Object getProxy(@Nullable ClassLoader classLoader) {
return createAopProxy().getProxy(classLoader);
}
在上面的getProxy方法中createAopProxy方法,其实现是在DefaultAopProxyFactory中,这个方法的主要功能是,根据optimize、ProxyTargetClass等参数来决定生成Jdk动态代理,还是生成Cglib代理。我们进入到方法内:
protected final synchronized AopProxy createAopProxy() {
if (!this.active) {
activate();
}
// 创建代理
return getAopProxyFactory().createAopProxy(this);
}
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
//手动设置创建Cglib代理类后,如果目标bean是一个接口,也要创建jdk代理类
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
//创建Cglib代理
return new ObjenesisCglibAopProxy(config);
}
else {
//默认创建jdk代理
return new JdkDynamicAopProxy(config);
}
}
我们知道对于Spring的代理是通过JDKProxy的实现和CglibProxy实现。Spring是如何选取的呢?
从if的判断条件中可以看到3个方面影响这Spring的判断。
- optimize:用来控制通过CGLIB创建的代理是否使用激进的优化策略,除非完全了解AOP代理如何处理优化,否则不推荐用户使用这个设置。目前这个属性仅用于CGLIB 代理,对于JDK动态代理(缺省代理)无效。
- proxyTargetClass:这个属性为true时,目标类本身被代理而不是目标类的接口。如果这个属性值被设为true,CGLIB代理将被创建,设置方式:
- hasNoUserSuppliedProxylnterfaces:是否存在代理接口
下面是对JDK与Cglib方式的总结。
- 如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP。
- 如果目标对象实现了接口,可以强制使用CGLIB实现AOP。
- 如果目标对象没有实现了接口,必须采用CGLIB库,Spring会自动在JDK动态代理 和CGLIB之间转换。
如何强制使用CGLIB实现AOP?
(1)添加 CGLIB 库,Spring_HOME/cglib/*.jar。
(2)在 Spring 配置文件中加人
JDK动态代理和CGLIB字节码生成的区别?
- JDK动态代理只能对实现了接口的类生成代理,而不能针对类。
- CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法,因为是继承,所以该类或方法最好不要声明成final。
获取代理
本文主要介绍JDK动态代理类的实现,在此之前,有必要熟悉一下JDK代理使用示例,
Spring的AOP实现其实也是用了Proxy和InvocationHandler这两个东西的。
我们再次来回顾一下使用JDK代理的方式,在整个创建过程中,对于InvocationHandler的创建是最为核心的,在自定义的InvocationHandler中需要重写3个函数。
- 构造函数,将代理的对象传入。
- invoke方法,此方法中实现了 AOP增强的所有逻辑。
- getProxy方法,此方法千篇一律,但是必不可少。
那么,我们看看Spring中的JDK代理实现是不是也是这么做的呢?我们来看看简化后的 JdkDynamicAopProxy 。
1 final class JdkDynamicAopProxy implements AopProxy, InvocationHandler, Serializable {
2
3 private final AdvisedSupport advised;
4
5 public JdkDynamicAopProxy(AdvisedSupport config) throws AopConfigException {
6 Assert.notNull(config, "AdvisedSupport must not be null");
7 if (config.getAdvisors().length == 0 && config.getTargetSource() == AdvisedSupport.EMPTY_TARGET_SOURCE) {
8 throw new AopConfigException("No advisors and no TargetSource specified");
9 }
10 this.advised = config;
11 }
12
13
14 @Override
15 public Object getProxy() {
16 return getProxy(ClassUtils.getDefaultClassLoader());
17 }
18
19 @Override
20 public Object getProxy(@Nullable ClassLoader classLoader) {
21 if (logger.isTraceEnabled()) {
22 logger.trace("Creating JDK dynamic proxy: " + this.advised.getTargetSource());
23 }
24 Class<?>[] proxiedInterfaces = AopProxyUtils.completeProxiedInterfaces(this.advised, true);
25 findDefinedEqualsAndHashCodeMethods(proxiedInterfaces);
26 return Proxy.newProxyInstance(classLoader, proxiedInterfaces, this);
27 }
28
29 @Override
30 @Nullable
31 public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
32 Object oldProxy = null;
33 boolean setProxyContext = false;
34
35 TargetSource targetSource = this.advised.targetSource;
36 Object target = null;
37
38 try {
39 if (!this.equalsDefined && AopUtils.isEqualsMethod(method)) {
40 // The target does not implement the equals(Object) method itself.
41 return equals(args[0]);
42 }
43 else if (!this.hashCodeDefined && AopUtils.isHashCodeMethod(method)) {
44 // The target does not implement the hashCode() method itself.
45 return hashCode();
46 }
47 else if (method.getDeclaringClass() == DecoratingProxy.class) {
48 // There is only getDecoratedClass() declared -> dispatch to proxy config.
49 return AopProxyUtils.ultimateTargetClass(this.advised);
50 }
51 else if (!this.advised.opaque && method.getDeclaringClass().isInterface() &&
52 method.getDeclaringClass().isAssignableFrom(Advised.class)) {
53 // Service invocations on ProxyConfig with the proxy config...
54 return AopUtils.invokeJoinpointUsingReflection(this.advised, method, args);
55 }
56
57 Object retVal;
58
59 if (this.advised.exposeProxy) {
60 // Make invocation available if necessary.
61 oldProxy = AopContext.setCurrentProxy(proxy);
62 setProxyContext = true;
63 }
64
65 // Get as late as possible to minimize the time we "own" the target,
66 // in case it comes from a pool.
67 target = targetSource.getTarget();
68 Class<?> targetClass = (target != null ? target.getClass() : null);
69
70 // Get the interception chain for this method.
71 List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
72
73 // Check whether we have any advice. If we don't, we can fallback on direct
74 // reflective invocation of the target, and avoid creating a MethodInvocation.
75 if (chain.isEmpty()) {
76 // We can skip creating a MethodInvocation: just invoke the target directly
77 // Note that the final invoker must be an InvokerInterceptor so we know it does
78 // nothing but a reflective operation on the target, and no hot swapping or fancy proxying.
79 Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
80 retVal = AopUtils.invokeJoinpointUsingReflection(target, method, argsToUse);
81 }
82 else {
83 // We need to create a method invocation...
84 MethodInvocation invocation =
85 new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
86 // Proceed to the joinpoint through the interceptor chain.
87 retVal = invocation.proceed();
88 }
89
90 // Massage return value if necessary.
91 Class<?> returnType = method.getReturnType();
92 if (retVal != null && retVal == target &&
93 returnType != Object.class && returnType.isInstance(proxy) &&
94 !RawTargetAccess.class.isAssignableFrom(method.getDeclaringClass())) {
95 // Special case: it returned "this" and the return type of the method
96 // is type-compatible. Note that we can't help if the target sets
97 // a reference to itself in another returned object.
98 retVal = proxy;
99 }
100 else if (retVal == null && returnType != Void.TYPE && returnType.isPrimitive()) {
101 throw new AopInvocationException(
102 "Null return value from advice does not match primitive return type for: " + method);
103 }
104 return retVal;
105 }
106 finally {
107 if (target != null && !targetSource.isStatic()) {
108 // Must have come from TargetSource.
109 targetSource.releaseTarget(target);
110 }
111 if (setProxyContext) {
112 // Restore old proxy.
113 AopContext.setCurrentProxy(oldProxy);
114 }
115 }
116 }
117
118 }
我们看到JdkDynamicAopProxy 也是和我们自定义的InvocationHandler一样,实现了InvocationHandler接口,并且提供了一个getProxy方法创建代理类,重写invoke方法。
我们重点看看代理类的调用。了解Jdk动态代理的话都会知道,在实现Jdk动态代理功能,要实现InvocationHandler接口的invoke方法(这个方法是一个回调方法)。 *被代理类中的方法被调用时,实际上是调用的invoke方法,我们看一看这个方法的实现。*
1 @Override
2 @Nullable
3 public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
4 MethodInvocation invocation;
5 Object oldProxy = null;
6 boolean setProxyContext = false;
7
8 TargetSource targetSource = this.advised.targetSource;
9 Object target = null;
10
11 try {
12 if (!this.equalsDefined && AopUtils.isEqualsMethod(method)) {
13 return equals(args[0]);
14 }
15 else if (!this.hashCodeDefined && AopUtils.isHashCodeMethod(method)) {
16 return hashCode();
17 }
18 else if (method.getDeclaringClass() == DecoratingProxy.class) {
19 return AopProxyUtils.ultimateTargetClass(this.advised);
20 }
21 else if (!this.advised.opaque && method.getDeclaringClass().isInterface() &&
22 method.getDeclaringClass().isAssignableFrom(Advised.class)) {
23 return AopUtils.invokeJoinpointUsingReflection(this.advised, method, args);
24 }
25
26 Object retVal;
27 if (this.advised.exposeProxy) {
28 // Make invocation available if necessary.
29 oldProxy = AopContext.setCurrentProxy(proxy);
30 setProxyContext = true;
31 }
32
33 target = targetSource.getTarget();
34 Class<?> targetClass = (target != null ? target.getClass() : null);
35
36 // 获取当前方法的拦截器链
37 List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
38
39 if (chain.isEmpty()) {
40 // 如果没有发现任何拦截器那么直接调用切点方法
41 Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
42 retVal = AopUtils.invokeJoinpointUsingReflection(target, method, argsToUse);
43 }
44 else {
45 // We need to create a method invocation...
46 // 将拦截器封装在ReflectiveMethodInvocation,
47 // 以便于使用其proceed进行链接表用拦截器
48 invocation = new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
49 // Proceed to the joinpoint through the interceptor chain.
50 // 执行拦截器链
51 retVal = invocation.proceed();
52 }
53
54 Class<?> returnType = method.getReturnType();
55 // 返回结果
56 if (retVal != null && retVal == target &&
57 returnType != Object.class && returnType.isInstance(proxy) &&
58 !RawTargetAccess.class.isAssignableFrom(method.getDeclaringClass())) {
59 retVal = proxy;
60 }
61 else if (retVal == null && returnType != Void.TYPE && returnType.isPrimitive()) {
62 throw new AopInvocationException(
63 "Null return value from advice does not match primitive return type for: " + method);
64 }
65 return retVal;
66 }
67 finally {
68 if (target != null && !targetSource.isStatic()) {
69 // Must have come from TargetSource.
70 targetSource.releaseTarget(target);
71 }
72 if (setProxyContext) {
73 // Restore old proxy.
74 AopContext.setCurrentProxy(oldProxy);
75 }
76 }
77 }
我们先来看看第37行,获取目标bean中目标method中的增强器,并将增强器封装成拦截器链
1 @Override
2 public List<Object> getInterceptorsAndDynamicInterceptionAdvice(
3 Advised config, Method method, @Nullable Class<?> targetClass) {
4
5 // This is somewhat tricky... We have to process introductions first,
6 // but we need to preserve order in the ultimate list.
7 AdvisorAdapterRegistry registry = GlobalAdvisorAdapterRegistry.getInstance();
8 Advisor[] advisors = config.getAdvisors();
9 List<Object> interceptorList = new ArrayList<>(advisors.length);
10 Class<?> actualClass = (targetClass != null ? targetClass : method.getDeclaringClass());
11 Boolean hasIntroductions = null;
12
13 //获取bean中的所有增强器
14 for (Advisor advisor : advisors) {
15 if (advisor instanceof PointcutAdvisor) {
16 // Add it conditionally.
17 PointcutAdvisor pointcutAdvisor = (PointcutAdvisor) advisor;
18 if (config.isPreFiltered() || pointcutAdvisor.getPointcut().getClassFilter().matches(actualClass)) {
19 MethodMatcher mm = pointcutAdvisor.getPointcut().getMethodMatcher();
20 boolean match;
21 if (mm instanceof IntroductionAwareMethodMatcher) {
22 if (hasIntroductions == null) {
23 hasIntroductions = hasMatchingIntroductions(advisors, actualClass);
24 }
25 match = ((IntroductionAwareMethodMatcher) mm).matches(method, actualClass, hasIntroductions);
26 }
27 else {
28 //根据增强器中的Pointcut判断增强器是否能匹配当前类中的method
29 //我们要知道目标Bean中并不是所有的方法都需要增强,也有一些普通方法
30 match = mm.matches(method, actualClass);
31 }
32 if (match) {
33 //如果能匹配,就将advisor封装成MethodInterceptor加入到interceptorList中
34 MethodInterceptor[] interceptors = registry.getInterceptors(advisor);
35 if (mm.isRuntime()) {
36 // Creating a new object instance in the getInterceptors() method
37 // isn't a problem as we normally cache created chains.
38 for (MethodInterceptor interceptor : interceptors) {
39 interceptorList.add(new InterceptorAndDynamicMethodMatcher(interceptor, mm));
40 }
41 }
42 else {
43 interceptorList.addAll(Arrays.asList(interceptors));
44 }
45 }
46 }
47 }
48 else if (advisor instanceof IntroductionAdvisor) {
49 IntroductionAdvisor ia = (IntroductionAdvisor) advisor;
50 if (config.isPreFiltered() || ia.getClassFilter().matches(actualClass)) {
51 Interceptor[] interceptors = registry.getInterceptors(advisor);
52 interceptorList.addAll(Arrays.asList(interceptors));
53 }
54 }
55 else {
56 Interceptor[] interceptors = registry.getInterceptors(advisor);
57 interceptorList.addAll(Arrays.asList(interceptors));
58 }
59 }
60
61 return interceptorList;
62 }
我们知道目标Bean中并不是所有的方法都需要增强,所以我们要遍历所有的 Advisor ,根据Pointcut判断增强器是否能匹配当前类中的method,取出能匹配的增强器,封装成 MethodInterceptor,加入到拦截器链中,我们来看看第34行
@Override
public MethodInterceptor[] getInterceptors(Advisor advisor) throws UnknownAdviceTypeException {
List<MethodInterceptor> interceptors = new ArrayList<>(3);
Advice advice = advisor.getAdvice();
if (advice instanceof MethodInterceptor) {
interceptors.add((MethodInterceptor) advice);
}
//这里遍历三个适配器,将对应的advisor转化成Interceptor
//这三个适配器分别是MethodBeforeAdviceAdapter,AfterReturningAdviceAdapter,ThrowsAdviceAdapter
for (AdvisorAdapter adapter : this.adapters) {
if (adapter.supportsAdvice(advice)) {
interceptors.add(adapter.getInterceptor(advisor));
}
}
if (interceptors.isEmpty()) {
throw new UnknownAdviceTypeException(advisor.getAdvice());
}
return interceptors.toArray(new MethodInterceptor[0]);
}
private final List<AdvisorAdapter> adapters = new ArrayList<>(3);
/**
* Create a new DefaultAdvisorAdapterRegistry, registering well-known adapters.
*/
public DefaultAdvisorAdapterRegistry() {
registerAdvisorAdapter(new MethodBeforeAdviceAdapter());
registerAdvisorAdapter(new AfterReturningAdviceAdapter());
registerAdvisorAdapter(new ThrowsAdviceAdapter());
}
@Override
public void registerAdvisorAdapter(AdvisorAdapter adapter) {
this.adapters.add(adapter);
}
由于Spring中涉及过多的拦截器,增强器,增强方法等方式来对逻辑进行增强,在上一篇文章中我们知道创建的几个增强器,AspectJAroundAdvice、AspectJAfterAdvice、AspectJAfterThrowingAdvice这几个增强器都实现了 MethodInterceptor 接口,AspectJMethodBeforeAdvice 和AspectJAfterReturningAdvice 并没有实现 MethodInterceptor 接口,因此AspectJMethodBeforeAdvice 和AspectJAfterReturningAdvice不能满足MethodInterceptor 接口中的invoke方法,所以这里使用适配器模式将AspectJMethodBeforeAdvice 和AspectJAfterReturningAdvice转化成能满足需求的MethodInterceptor实现类。
遍历adapters,通过adapter.supportsAdvice(advice)找到advice对应的适配器,adapter.getInterceptor(advisor)将advisor转化成对应的interceptor
我们来看看这几个增强器
AspectJAroundAdvice
 View Code
View Code
AspectJMethodBeforeAdvice
View Code
AspectJAfterAdvice
View Code
AspectJAfterReturningAdvice
View Code
AspectJAfterThrowingAdvice
View Code
接下来我们看看MethodBeforeAdviceAdapter和AfterReturningAdviceAdapter这两个适配器,这两个适配器是将MethodBeforeAdvice和AfterReturningAdvice适配成对应的Interceptor
MethodBeforeAdviceAdapter
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable {
@Override
public boolean supportsAdvice(Advice advice) {
//判断是否是MethodBeforeAdvice类型的advice
return (advice instanceof MethodBeforeAdvice);
}
@Override
public MethodInterceptor getInterceptor(Advisor advisor) {
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
//将advice封装成MethodBeforeAdviceInterceptor
return new MethodBeforeAdviceInterceptor(advice);
}
}
//MethodBeforeAdviceInterceptor实现了MethodInterceptor接口,实现了invoke方法,并将advice作为属性
public class MethodBeforeAdviceInterceptor implements MethodInterceptor, BeforeAdvice, Serializable {
private final MethodBeforeAdvice advice;
public MethodBeforeAdviceInterceptor(MethodBeforeAdvice advice) {
Assert.notNull(advice, "Advice must not be null");
this.advice = advice;
}
@Override
public Object invoke(MethodInvocation mi) throws Throwable {
this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis());
return mi.proceed();
}
}
AfterReturningAdviceAdapter
class AfterReturningAdviceAdapter implements AdvisorAdapter, Serializable {
@Override
public boolean supportsAdvice(Advice advice) {
return (advice instanceof AfterReturningAdvice);
}
@Override
public MethodInterceptor getInterceptor(Advisor advisor) {
AfterReturningAdvice advice = (AfterReturningAdvice) advisor.getAdvice();
return new AfterReturningAdviceInterceptor(advice);
}
}
public class AfterReturningAdviceInterceptor implements MethodInterceptor, AfterAdvice, Serializable {
private final AfterReturningAdvice advice;
public AfterReturningAdviceInterceptor(AfterReturningAdvice advice) {
Assert.notNull(advice, "Advice must not be null");
this.advice = advice;
}
@Override
public Object invoke(MethodInvocation mi) throws Throwable {
Object retVal = mi.proceed();
this.advice.afterReturning(retVal, mi.getMethod(), mi.getArguments(), mi.getThis());
return retVal;
}
}
至此我们获取到了一个拦截器链,链中包括AspectJAroundAdvice、AspectJAfterAdvice、AspectJAfterThrowingAdvice、MethodBeforeAdviceInterceptor、AfterReturningAdviceInterceptor
接下来 ReflectiveMethodInvocation 类进行了链的封装,而在ReflectiveMethodInvocation类的proceed方法中实现了拦截器的逐一调用,那么我们继续来探究,在proceed方法中是怎么实现前置增强在目标方法前调用后置增强在目标方法后调用的逻辑呢?
我们先来看看ReflectiveMethodInvocation的构造器,只是简单的进行属性赋值,不过我们要注意有一个特殊的变量currentInterceptorIndex,这个变量代表执行Interceptor的下标,从-1开始,Interceptor执行一个,先++this.currentInterceptorIndex
protected ReflectiveMethodInvocation(
Object proxy, @Nullable Object target, Method method, @Nullable Object[] arguments,
@Nullable Class<?> targetClass, List<Object> interceptorsAndDynamicMethodMatchers) {
this.proxy = proxy;
this.target = target;
this.targetClass = targetClass;
this.method = BridgeMethodResolver.findBridgedMethod(method);
this.arguments = AopProxyUtils.adaptArgumentsIfNecessary(method, arguments);
this.interceptorsAndDynamicMethodMatchers = interceptorsAndDynamicMethodMatchers;
}
private int currentInterceptorIndex = -1;
下面是ReflectiveMethodInvocation类Proceed方法:
public Object proceed() throws Throwable {
// 首先,判断是不是所有的interceptor(也可以想像成advisor)都被执行完了。
// 判断的方法是看currentInterceptorIndex这个变量的值,增加到Interceptor总个数这个数值没有,
// 如果到了,就执行被代理方法(invokeJoinpoint());如果没到,就继续执行Interceptor。
if (this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size() - 1) {
return invokeJoinpoint();
}
// 如果Interceptor没有被全部执行完,就取出要执行的Interceptor,并执行。
// currentInterceptorIndex先自增
Object interceptorOrInterceptionAdvice =this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex);
// 如果Interceptor是PointCut类型
if (interceptorOrInterceptionAdvice instanceof InterceptorAndDynamicMethodMatcher) {
InterceptorAndDynamicMethodMatcher dm = (InterceptorAndDynamicMethodMatcher) interceptorOrInterceptionAdvice;
// 如果当前方法符合Interceptor的PointCut限制,就执行Interceptor
if (dm.methodMatcher.matches(this.method, this.targetClass, this.arguments)) {
// 这里将this当变量传进去,这是非常重要的一点
return dm.interceptor.invoke(this);
}
// 如果不符合,就跳过当前Interceptor,执行下一个Interceptor
else {
return proceed();
}
}
// 如果Interceptor不是PointCut类型,就直接执行Interceptor里面的增强。
else {
return ((MethodInterceptor) interceptorOrInterceptionAdvice).invoke(this);
}
}
由于篇幅过程,目标方法和增强方法是如何执行的,我们将重新写一篇文章来讲解
AOP目标方法和增强方法的执行
上一篇博文中我们讲了代理类的生成,这一篇主要讲解剩下的部分,当代理类调用时,目标方法和代理方法是如何执行的,我们还是接着上篇的ReflectiveMethodInvocation类Proceed方法来看
public Object proceed() throws Throwable {
// 首先,判断是不是所有的interceptor(也可以想像成advisor)都被执行完了。
// 判断的方法是看currentInterceptorIndex这个变量的值,增加到Interceptor总个数这个数值没有,
// 如果到了,就执行被代理方法(invokeJoinpoint());如果没到,就继续执行Interceptor。
if (this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size() - 1) {
return invokeJoinpoint();
}
// 如果Interceptor没有被全部执行完,就取出要执行的Interceptor,并执行。
// currentInterceptorIndex先自增
Object interceptorOrInterceptionAdvice = this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex);
// 如果Interceptor是PointCut类型
if (interceptorOrInterceptionAdvice instanceof InterceptorAndDynamicMethodMatcher) {
InterceptorAndDynamicMethodMatcher dm = (InterceptorAndDynamicMethodMatcher) interceptorOrInterceptionAdvice;
// 如果当前方法符合Interceptor的PointCut限制,就执行Interceptor
if (dm.methodMatcher.matches(this.method, this.targetClass, this.arguments)) {
// 这里将this当变量传进去,这是非常重要的一点
return dm.interceptor.invoke(this);
}
// 如果不符合,就跳过当前Interceptor,执行下一个Interceptor
else {
return proceed();
}
}
// 如果Interceptor不是PointCut类型,就直接执行Interceptor里面的增强。
else {
return ((MethodInterceptor) interceptorOrInterceptionAdvice).invoke(this);
}
}
我们先来看一张方法调用顺序图
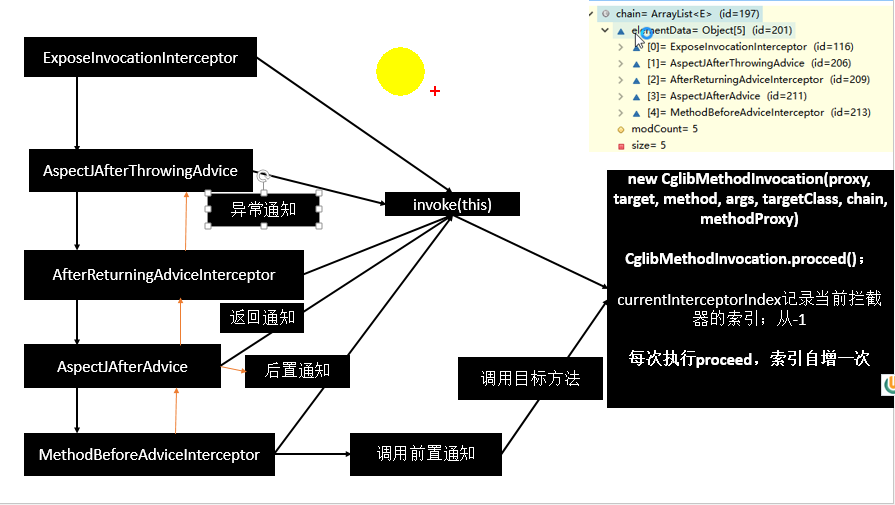
我们看到链中的顺序是AspectJAfterThrowingAdvice、AfterReturningAdviceInterceptor、AspectJAfterAdvice、MethodBeforeAdviceInterceptor,这些拦截器是按顺序执行的,那我们来看看第一个拦截器AspectJAfterThrowingAdvice中的invoke方法
AspectJAfterThrowingAdvice
1 @Override
2 public Object invoke(MethodInvocation mi) throws Throwable {
3 try {
4 //直接调用MethodInvocation的proceed方法
5 //从proceed()方法中我们知道dm.interceptor.invoke(this)传过来的参数就是ReflectiveMethodInvocation执行器本身
6 //这里又直接调用了ReflectiveMethodInvocation的proceed()方法
7 return mi.proceed();
8 }
9 catch (Throwable ex) {
10 if (shouldInvokeOnThrowing(ex)) {
11 invokeAdviceMethod(getJoinPointMatch(), null, ex);
12 }
13 throw ex;
14 }
15 }
第一个拦截器AspectJAfterThrowingAdvice的invoke方法中,直接调用mi.proceed();,从proceed()方法中我们知道dm.interceptor.invoke(this)传过来的参数就是ReflectiveMethodInvocation执行器本身,所以又会执行proceed()方法,拦截器下标currentInterceptorIndex自增,获取下一个拦截器AfterReturningAdviceInterceptor,并调用拦截器中的invoke方法,,此时第一个拦截器在invoke()方法的第七行卡住了,接下来我们看第二个拦截器的执行
AfterReturningAdviceInterceptor
1 @Override
2 public Object invoke(MethodInvocation mi) throws Throwable {
3 //直接调用MethodInvocation的proceed方法
4 Object retVal = mi.proceed();
5 this.advice.afterReturning(retVal, mi.getMethod(), mi.getArguments(), mi.getThis());
6 return retVal;
7 }
AfterReturningAdviceInterceptor还是直接调用mi.proceed(),又回到了ReflectiveMethodInvocation的proceed()方法中,此时AfterReturningAdviceInterceptor方法卡在第四行,接着回到ReflectiveMethodInvocation的proceed()方法中,拦截器下标currentInterceptorIndex自增,获取下一个拦截器AspectJAfterAdvice,并调用AspectJAfterAdvice中的invoke方法
AspectJAfterAdvice
1 @Override
2 public Object invoke(MethodInvocation mi) throws Throwable {
3 try {
4 //直接调用MethodInvocation的proceed方法
5 return mi.proceed();
6 }
7 finally {
8 invokeAdviceMethod(getJoinPointMatch(), null, null);
9 }
10 }
AspectJAfterAdvice还是直接调用mi.proceed(),又回到了ReflectiveMethodInvocation的proceed()方法中,此时AspectJAfterAdvice方法卡在第五行,接着回到ReflectiveMethodInvocation的proceed()方法中,拦截器下标currentInterceptorIndex自增,获取下一个拦截器MethodBeforeAdviceInterceptor,并调用MethodBeforeAdviceInterceptor中的invoke方法
MethodBeforeAdviceInterceptor
1 @Override
2 public Object invoke(MethodInvocation mi) throws Throwable {
3 //终于开始做事了,调用增强器的before方法,明显是通过反射的方式调用
4 //到这里增强方法before的业务逻辑执行
5 this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis());
6 //又调用了调用MethodInvocation的proceed方法
7 return mi.proceed();
8 }
第5行代码终于通过反射调用了切面里面的before方法,接着又调用mi.proceed(),我们知道这是最后一个拦截器了,此时this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size() - 1应该为true了,那么就会执行 return invokeJoinpoint();,也就是执行bean中的目标方法,接着我们来看看目标方法的执行
@Nullable
protected Object invokeJoinpoint() throws Throwable {
return AopUtils.invokeJoinpointUsingReflection(this.target, this.method, this.arguments);
}
@Nullable
public static Object invokeJoinpointUsingReflection(@Nullable Object target, Method method, Object[] args)
throws Throwable {
// Use reflection to invoke the method.
try {
ReflectionUtils.makeAccessible(method);
//直接通过反射调用目标bean中的method
return method.invoke(target, args);
}
catch (InvocationTargetException ex) {
// Invoked method threw a checked exception.
// We must rethrow it. The client won't see the interceptor.
throw ex.getTargetException();
}
catch (IllegalArgumentException ex) {
throw new AopInvocationException("AOP configuration seems to be invalid: tried calling method [" +
method + "] on target [" + target + "]", ex);
}
catch (IllegalAccessException ex) {
throw new AopInvocationException("Could not access method [" + method + "]", ex);
}
}
before方法执行完后,就通过反射的方式执行目标bean中的method,并且返回结果,接下来我们想想程序该怎么执行呢?
1 、MethodBeforeAdviceInterceptor执行完了后,开始退栈,*AspectJAfterAdvice中invoke卡在第5行的代码继续往下执行, 我们看到在AspectJAfterAdvice的invoke方法中的finally中第8行有这样一句话 invokeAdviceMethod(getJoinPointMatch(), null, null);,就是通过反射调用AfterAdvice的方法,意思是切面类中的 @After方法不管怎样都会执行,因为在finally中*
*2、AspectJAfterAdvice中invoke方法发执行完后,也开始退栈,接着就到了AfterReturningAdviceInterceptor的invoke方法的第4行开始恢复,但是此时如果目标bean和前面增强器中出现了异常,此时AfterReturningAdviceInterceptor中第5行代码就不会执行了,直接退栈;如果没有出现异常,则执行第5行,也就是通过反射执行切面类中@AfterReturning注解的方法,然后退栈*
*3、AfterReturningAdviceInterceptor退栈后,就到了AspectJAfterThrowingAdvice拦截器,此拦截器中invoke方法的第7行开始恢复,我们看到在 catch (Throwable ex) { 代码中,也就是第11行 invokeAdviceMethod(getJoinPointMatch(), null, ex);,如果目标bean的method或者前面的增强方法中出现了异常,则会被这里的catch捕获,也是通过反射的方式执行@AfterThrowing注解的方法,然后退栈*
总结
这个代理类调用过程,我们可以看到是一个递归的调用过程,通过ReflectiveMethodInvocation类中Proceed方法递归调用,顺序执行拦截器链中AspectJAfterThrowingAdvice、AfterReturningAdviceInterceptor、AspectJAfterAdvice、MethodBeforeAdviceInterceptor这几个拦截器,在拦截器中反射调用增强方法
Spring事务源码
spring基于Aop实现了事物管理。
事务的介绍
数据库事务特性
- 原子性 多个数据库操作是不可分割的,只有所有的操作都执行成功,事务才能被提交;只要有一个操作执行失败,那么所有的操作都要回滚,数据库状态必须回复到操作之前的状态
- 一致性 事务操作成功后,数据库的状态和业务规则必须一致。例如:从A账户转账100元到B账户,无论数据库操作成功失败,A和B两个账户的存款总额是不变的。
- 隔离性 当并发操作时,不同的数据库事务之间不会相互干扰(当然这个事务隔离级别也是有关系的)
- 持久性 事务提交成功之后,事务中的所有数据都必须持久化到数据库中。即使事务提交之后数据库立刻崩溃,也需要保证数据能能够被恢复。
事物隔离级别
当数据库并发操作时,可能会引起脏读、不可重复读、幻读等现象。
- 脏读 事务A读取事务B尚未提交的更改数据,并做了修改;此时如果事务B回滚,那么事务A读取到的数据是无效的,此时就发生了脏读。
- 不可重复读 一个事务执行相同的查询两次或两次以上,每次都得到不同的数据。如:A事务下查询账户余额,此时恰巧B事务给账户里转账100元,A事务再次查询账户余额,那么A事务的两次查询结果是不一致的。
- 幻读 A事务读取B事务提交的新增数据,此时A事务将出现幻读现象。幻读与不可重复读容易混淆,如何区分呢?幻读是读取到了其他事务提交的新数据,不可重复读是读取到了已经提交事务的更改数据(修改或删除)
对于以上问题,可以有多个解决方案,设置数据库事务隔离级别就是其中的一种,数据库事务隔离级别分为四个等级,通过一个表格描述其作用。
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 |
|---|---|---|---|
| READ UNCOMMITTED | 允许 | 允许 | 允许 |
| READ COMMITTED | 脏读 | 允许 | 允许 |
| REPEATABLE READ | 不允许 | 不允许 | 允许 |
| SERIALIZABLE | 不允许 | 不允许 | 不允许 |
Spring事务支持核心接口
Spring事务管理高层抽象主要包括3个接口,Spring的事务主要是由他们共同完成的:
- TransactionDefinition:事务定义信息(隔离、传播、超时、只读)—通过配置如何进行事务管理。
- PlatformTransactionManager:事务管理器—主要用于平台相关事务的管理
- TransactionStatus:事务具体运行状态—事务管理过程中,每个时间点事务的状态信息。
TransactionDefinition(事务定义信息)
定义与spring兼容的事务属性的接口
public interface TransactionDefinition {
// 如果当前没有事物,则新建一个事物;如果已经存在一个事物,则加入到这个事物中。
int PROPAGATION_REQUIRED = 0;
// 支持当前事物,如果当前没有事物,则以非事物方式执行。
int PROPAGATION_SUPPORTS = 1;
// 使用当前事物,如果当前没有事物,则抛出异常。
int PROPAGATION_MANDATORY = 2;
// 新建事物,如果当前已经存在事物,则挂起当前事物。
int PROPAGATION_REQUIRES_NEW = 3;
// 以非事物方式执行,如果当前存在事物,则挂起当前事物。
int PROPAGATION_NOT_SUPPORTED = 4;
// 以非事物方式执行,如果当前存在事物,则抛出异常。
int PROPAGATION_NEVER = 5;
// 如果当前存在事物,则在嵌套事物内执行;如果当前没有事物,则与PROPAGATION_REQUIRED传播特性相同
int PROPAGATION_NESTED = 6;
// 使用后端数据库默认的隔离级别。
int ISOLATION_DEFAULT = -1;
// READ_UNCOMMITTED 隔离级别
int ISOLATION_READ_UNCOMMITTED = Connection.TRANSACTION_READ_UNCOMMITTED;
// READ_COMMITTED 隔离级别
int ISOLATION_READ_COMMITTED = Connection.TRANSACTION_READ_COMMITTED;
// REPEATABLE_READ 隔离级别
int ISOLATION_REPEATABLE_READ = Connection.TRANSACTION_REPEATABLE_READ;
// SERIALIZABLE 隔离级别
int ISOLATION_SERIALIZABLE = Connection.TRANSACTION_SERIALIZABLE;
// 默认超时时间
int TIMEOUT_DEFAULT = -1;
// 获取事物传播特性
int getPropagationBehavior();
// 获取事物隔离级别
int getIsolationLevel();
// 获取事物超时时间
int getTimeout();
// 判断事物是否可读
boolean isReadOnly();
// 获取事物名称
@Nullable
String getName();
}
该接口主要提供的方法:
-
getIsolationLevel:隔离级别获取
-
getPropagationBehavior:传播行为获取
-
getTimeout:获取超时时间
-
isReadOnly 是否只读(保存、更新、删除—对数据进行操作-变成可读写的,查询-设置这个属性为true,只能读不能写)
-
withDefaults()
Return an unmodifiable TransactionDefinition with defaults. For customization purposes, use the modifiable DefaultTransactionDefinition instead. Since: 5.2这些事务的定义信息,都可以在配置文件中配置和定制。
Spring事物传播特性
| 传播特性名称 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事物,则新建一个事物;如果已经存在一个事物,则加入到这个事物中 |
| PROPAGATION_SUPPORTS | 支持当前事物,如果当前没有事物,则以非事物方式执行 |
| PROPAGATION_MANDATORY | 使用当前事物,如果当前没有事物,则抛出异常 |
| PROPAGATION_REQUIRES_NEW | 新建事物,如果当前已经存在事物,则挂起当前事物 |
| PROPAGATION_NOT_SUPPORTED | 以非事物方式执行,如果当前存在事物,则挂起当前事物 |
| PROPAGATION_NEVER | 以非事物方式执行,如果当前存在事物,则抛出异常 |
| PROPAGATION_NESTED | 如果当前存在事物,则在嵌套事物内执行;如果当前没有事物,则与PROPAGATION_REQUIRED传播特性相同 |
Spring事物隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
- TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
- TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
- TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
mysql默认的事务隔离级别为 可重复读repeatable-read
Oracle 默认隔离级别 READ_COMMITTED
PlatformTransactionManager(事务管理器)
Spring事务基础结构中的中心接口
public interface PlatformTransactionManager {
// 根据指定的传播行为,返回当前活动的事务或创建新事务。
TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException;
// 就给定事务的状态提交给定事务。
void commit(TransactionStatus status) throws TransactionException;
// 执行给定事务的回滚。
void rollback(TransactionStatus status) throws TransactionException;
}
该接口提供三个方法:
- commit:提交事务
- rollback:回滚事务
- getTransaction:获取事务状态
Spring将事物管理委托给底层的持久化框架来完成,因此,Spring为不同的持久化框架提供了不同的PlatformTransactionManager接口实现。列举几个Spring自带的事物管理器:
| 事物管理器 | 说明 |
|---|---|
| org.springframework.jdbc.datasource.DataSourceTransactionManager | 提供对单个javax.sql.DataSource事务管理,用于Spring JDBC抽象框架、iBATIS或MyBatis框架的事务管理 |
| org.springframework.orm.jpa.JpaTransactionManager | 提供对单个javax.persistence.EntityManagerFactory事务支持,用于集成JPA实现框架时的事务管理 |
| org.springframework.transaction.jta.JtaTransactionManager | 提供对分布式事务管理的支持,并将事务管理委托给Java EE应用服务器事务管理器 |
- DataSourceTransactionManager针对JdbcTemplate、MyBatis 事务控制 ,使用Connection(连接)进行事务控制 : 开启事务 connection.setAutoCommit(false); 提交事务 connection.commit(); 回滚事务 connection.rollback();
- HibernateTransactionManage针对Hibernate框架进行事务管理, 使用Session的Transaction相关操作进行事务控制 : 开启事务 session.beginTransaction(); 提交事务 session.getTransaction().commit(); 回滚事务 session.getTransaction().rollback();
事务管理器的选择? 用户根据选择和使用的持久层技术,来选择对应的事务管理器。
TransactionStatus(事务状态)
- 事物状态描述
- TransactionStatus接口
public interface TransactionStatus extends SavepointManager, Flushable {
// 返回当前事务是否为新事务(否则将参与到现有事务中,或者可能一开始就不在实际事务中运行)
boolean isNewTransaction();
// 返回该事务是否在内部携带保存点,也就是说,已经创建为基于保存点的嵌套事务。
boolean hasSavepoint();
// 设置事务仅回滚。
void setRollbackOnly();
// 返回事务是否已标记为仅回滚
boolean isRollbackOnly();
// 将会话刷新到数据存储区
@Override
void flush();
// 返回事物是否已经完成,无论提交或者回滚。
boolean isCompleted();
}
SavepointManager接口
public interface SavepointManager {
// 创建一个新的保存点。
Object createSavepoint() throws TransactionException;
// 回滚到给定的保存点。
// 注意:调用此方法回滚到给定的保存点之后,不会自动释放保存点,
// 可以通过调用releaseSavepoint方法释放保存点。
void rollbackToSavepoint(Object savepoint) throws TransactionException;
// 显式释放给定的保存点。(大多数事务管理器将在事务完成时自动释放保存点)
void releaseSavepoint(Object savepoint) throws TransactionException;
}
用户管理事务,需要先配置事务管理方案TransactionDefinition、 管理事务通过TransactionManager完成,TransactionManager根据 TransactionDefinition进行事务管理,在事务运行过程中,每个时间点都可以通过获取TransactionStatus了解事务运行状态!
Spring事务管理两种方式
-
编程式的事务管理 通过TransactionTemplate手动管理事务 在实际应用中很少使用,原因是要修改原来的代码,加入事务管理代码(侵入性 )
-
使用XML配置声明式事务 Spring的声明式事务是通过AOP实现的(环绕通知) 开发中经常使用(代码侵入性最小)–推荐使用!
Spring编程式事务
- 数据库表结构
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`balance` int(11) DEFAULT NULL COMMENT '账户余额',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='--账户表'
- 实现
import org.apache.commons.dbcp.BasicDataSource;
import org.springframework.dao.DataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
import javax.sql.DataSource;
/**
* Spring编程式事务
*/
public class MyTransaction {
private JdbcTemplate jdbcTemplate;
private DataSourceTransactionManager txManager;
private DefaultTransactionDefinition txDefinition;
private String insert_sql = "insert into account (balance) values ('100')";
public void save() {
// 1、初始化jdbcTemplate
DataSource dataSource = getDataSource();
jdbcTemplate = new JdbcTemplate(dataSource);
// 2、创建物管理器
txManager = new DataSourceTransactionManager();
txManager.setDataSource(dataSource);
// 3、定义事物属性
txDefinition = new DefaultTransactionDefinition();
txDefinition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
// 3、开启事物
TransactionStatus txStatus = txManager.getTransaction(txDefinition);
// 4、执行业务逻辑
try {
jdbcTemplate.execute(insert_sql);
//int i = 1/0;
jdbcTemplate.execute(insert_sql);
txManager.commit(txStatus);
} catch (DataAccessException e) {
txManager.rollback(txStatus);
e.printStackTrace();
}
}
public DataSource getDataSource() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/my_test?useSSL=false&useUnicode=true&characterEncoding=UTF-8");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
}
- 测试类及结果
public class MyTest {
@Test
public void test1() {
MyTransaction myTransaction = new MyTransaction();
myTransaction.save();
}
}
运行测试类,在抛出异常之后手动回滚事物,所以数据库表中不会增加记录。
基于@Transactional注解的声明式事物
其底层建立在 AOP 的基础之上,对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。通过声明式事物,无需在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过等价的基于标注的方式),便可以将事务规则应用到业务逻辑中。
- 接口
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
/**
* 账户接口
*/
@Transactional(propagation = Propagation.REQUIRED)
public interface AccountServiceImp {
void save() throws RuntimeException;
}
- 实现
import org.springframework.jdbc.core.JdbcTemplate;
/**
* 账户接口实现
*/
public class AccountServiceImpl implements AccountServiceImp {
private JdbcTemplate jdbcTemplate;
private static String insert_sql = "insert into account(balance) values (100)";
@Override
public void save() throws RuntimeException {
System.out.println("==开始执行sql");
jdbcTemplate.update(insert_sql);
System.out.println("==结束执行sql");
System.out.println("==准备抛出异常");
throw new RuntimeException("==手动抛出一个异常");
}
public void setJdbcTemplate(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
}
- 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
<!--开启tx注解-->
<tx:annotation-driven transaction-manager="transactionManager"/>
<!--事物管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--数据源-->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/my_test?useSSL=false&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</bean>
<!--jdbcTemplate-->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--业务bean-->
<bean id="accountService" class="com.demo.aop.AccountServiceImpl">
<property name="jdbcTemplate" ref="jdbcTemplate"/>
</bean>
</beans>
- 测试
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
** 基于tx标签的声明式事务
*/
public class MyTest {
@Test
public void test1() {
// 基于tx标签的声明式事务
ApplicationContext ctx = new ClassPathXmlApplicationContext("aop.xml");
AccountServiceImp studentService = ctx.getBean("accountService", AccountServiceImp.class);
studentService.save();
}
}
- 测试
==开始执行sql
==结束执行sql
==准备抛出异常
java.lang.RuntimeException: ==手动抛出一个异常
at com.demo.spring.AccountServiceImpl.save(AccountServiceImpl.java:24)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
测试方法中手动抛出了一个异常,Spring会自动回滚事物,查看数据库可以看到并没有新增记录。
注意:默认情况下Spring中的事务处理只对RuntimeException方法进行回滚,所以,如果此处将RuntimeException替换成普通的Exception不会产生回滚效果。
接下来我们就分析基于@Transactional注解的声明式事物的的源码实现。
Spring事务是怎么通过AOP实现的
此篇文章需要有SpringAOP基础,知道AOP底层原理可以更好的理解Spring的事务处理。
自定义标签
对于Spring中事务功能的代码分析,我们首先从配置文件开始人手,在配置文件中有这样一个配置:
根据之前的分析,我们因此可以判断,在自定义标签中的解析过程中一定是做了一些辅助操作,于是我们先从自定义标签入手进行分析。使用Idea搜索全局代码,关键字annotation-driven,最终锁定类TxNamespaceHandler,在TxNamespaceHandler中的 init 方法中:
@Override
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());
}
在遇到诸如tx:annotation-driven为开头的配置后,Spring都会使用AnnotationDrivenBeanDefinitionParser类的parse方法进行解析。
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
if ("aspectj".equals(mode)) {
// mode="aspectj"
registerTransactionAspect(element, parserContext);
if (ClassUtils.isPresent("javax.transaction.Transactional", getClass().getClassLoader())) {
registerJtaTransactionAspect(element, parserContext);
}
}
else {
// mode="proxy"
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}
在解析中存在对于mode属性的判断,根据代码,如果我们需要使用AspectJ的方式进行事务切入(Spring中的事务是以AOP为基础的),那么可以使用这样的配置:
<tx:annotation-driven transaction-manager="transactionManager" mode="aspectj"/>
注册 InfrastructureAdvisorAutoProxyCreator
我们以默认配置为例进行分析,进人AopAutoProxyConfigurer类的configureAutoProxyCreator:
public static void configureAutoProxyCreator(Element element, ParserContext parserContext) {
//向IOC注册InfrastructureAdvisorAutoProxyCreator这个类型的Bean
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
String txAdvisorBeanName = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME;
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// Create the TransactionAttributeSource definition.
// 创建AnnotationTransactionAttributeSource类型的Bean
RootBeanDefinition sourceDef = new RootBeanDefinition("org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
String sourceName = parserContext.getReaderContext().registerWithGeneratedName(sourceDef);
// Create the TransactionInterceptor definition.
// 创建TransactionInterceptor类型的Bean
RootBeanDefinition interceptorDef = new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
String interceptorName = parserContext.getReaderContext().registerWithGeneratedName(interceptorDef);
// Create the TransactionAttributeSourceAdvisor definition.
// 创建BeanFactoryTransactionAttributeSourceAdvisor类型的Bean
RootBeanDefinition advisorDef = new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
// 将上面AnnotationTransactionAttributeSource类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
// 将上面TransactionInterceptor类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
// 将上面三个Bean注册进IOC中
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}
这里分别是注册了三个Bean,和一个InfrastructureAdvisorAutoProxyCreator,其中三个Bean支撑了整个事务的功能。
我们首先需要回顾一下AOP的原理,AOP中有一个 Advisor 存放在代理类中,而Advisor中有advise与pointcut信息,每次执行被代理类的方法时都会执行代理类的invoke(如果是JDK代理)方法,而invoke方法会根据advisor中的pointcut动态匹配这个方法需要执行的advise链,遍历执行advise链,从而达到AOP切面编程的目的。
BeanFactoryTransactionAttributeSourceAdvisor:首先看这个类的继承结构,可以看到这个类其实是一个Advisor,其实由名字也能看出来,类中有几个关键地方注意一下,在之前的注册过程中,将两个属性注入进这个Bean中:
// 将上面AnnotationTransactionAttributeSource类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
// 将上面TransactionInterceptor类型Bean注入进上面的Advisor
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
那么它们被注入成什么了呢?进入BeanFactoryTransactionAttributeSourceAdvisor一看便知。
@Nullable
private TransactionAttributeSource transactionAttributeSource;
在其父类中有属性:
@Nullable
private String adviceBeanName;
也就是说,这里先将上面的TransactionInterceptor的BeanName传入到Advisor中,然后将AnnotationTransactionAttributeSource这个Bean注入到Advisor中,那么这个Source Bean有什么用呢?可以继续看看BeanFactoryTransactionAttributeSourceAdvisor的源码。
private final TransactionAttributeSourcePointcut pointcut = new TransactionAttributeSourcePointcut() {
@Override
@Nullable
protected TransactionAttributeSource getTransactionAttributeSource() {
return transactionAttributeSource;
}
};
看到这里应该明白了,这里的Source是提供了pointcut信息,作为存放事务属性的一个类注入进Advisor中,到这里应该知道注册这三个Bean的作用了吧?首先注册pointcut、advice、advisor,然后将pointcut和advice注入进advisor中,在之后动态代理的时候会使用这个Advisor去寻找每个Bean是否需要动态代理(取决于是否有开启事务),因为Advisor有pointcut信息。
- InfrastructureAdvisorAutoProxyCreator:在方法开头,首先就调用了AopNamespeceUtils去注册了这个Bean,那么这个Bean是干什么用的呢?还是先看看这个类的结构。这个类继承了AbstractAutoProxyCreator,看到这个名字,熟悉AOP的话应该已经知道它是怎么做的了吧?其次这个类还实现了BeanPostProcessor接口,凡事实现了这个BeanPost接口的类,我们首先关注的就是它的postProcessAfterInitialization方法,这里在其父类也就是刚刚提到的AbstractAutoProxyCreator这里去实现。(这里需要知道Spring容器初始化Bean的过程,关于BeanPostProcessor的使用我会另开一篇讲解。如果不知道只需了解如果一个Bean实现了BeanPostProcessor接口,当所有Bean实例化且依赖注入之后初始化方法之后会执行这个实现Bean的postProcessAfterInitialization方法)
进入这个函数:
public static void registerAutoProxyCreatorIfNecessary(
ParserContext parserContext, Element sourceElement) {
BeanDefinition beanDefinition = AopConfigUtils.registerAutoProxyCreatorIfNecessary(
parserContext.getRegistry(), parserContext.extractSource(sourceElement));
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
registerComponentIfNecessary(beanDefinition, parserContext);
}
@Nullable
public static BeanDefinition registerAutoProxyCreatorIfNecessary(BeanDefinitionRegistry registry,
@Nullable Object source) {
return registerOrEscalateApcAsRequired(InfrastructureAdvisorAutoProxyCreator.class, registry, source);
}
对于解析来的代码流程AOP中已经有所分析,上面的两个函数主要目的是注册了InfrastructureAdvisorAutoProxyCreator类型的bean,那么注册这个类的目的是什么呢?查看这个类的层次,如下图所示:
从上面的层次结构中可以看到,InfrastructureAdvisorAutoProxyCreator间接实现了SmartInstantiationAwareBeanPostProcessor,而SmartInstantiationAwareBeanPostProcessor又继承自InstantiationAwareBeanPostProcessor,也就是说在Spring中,所有bean实例化时Spring都会保证调用其postProcessAfterInstantiation方法,其实现是在父类AbstractAutoProxyCreator类中实现。
以之前的示例为例,当实例化AccountServiceImpl的bean时便会调用此方法,方法如下:
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
// 根据给定的bean的class和name构建出key,格式:beanClassName_beanName
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
// 如果它适合被代理,则需要封装指定bean
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
这里实现的主要目的是对指定bean进行封装,当然首先要确定是否需要封装,检测与封装的工作都委托给了wrapIfNecessary函数进行。
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 如果处理过这个bean的话直接返回
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
// 之后如果Bean匹配不成功,会将Bean的cacheKey放入advisedBeans中
// value为false,所以这里可以用cacheKey判断此bean是否之前已经代理不成功了
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
// 这里会将Advise、Pointcut、Advisor类型的类过滤,直接不进行代理,return
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
// 这里即为不成功的情况,将false放入Map中
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
// 这里是主要验证的地方,传入Bean的class与beanName去判断此Bean有哪些Advisor
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
// 如果有相应的advisor被找到,则用advisor与此bean做一个动态代理,将这两个的信息
// 放入代理类中进行代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 创建代理的地方
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
// 返回代理对象
return proxy;
}
// 如果此Bean没有一个Advisor匹配,将返回null也就是DO_NOT_PROXY
// 也就是会走到这一步,将其cacheKey,false存入Map中
this.advisedBeans.put(cacheKey, Boolean.FALSE);
// 不代理直接返回原bean
return bean;
}
wrapIfNecessary函数功能实现起来很复杂,但是逻辑上理解起来还是相对简单的,在wrapIfNecessary函数中主要的工作如下:
(1)找出指定bean对应的增强器。
(2)根据找出的增强器创建代理。
听起来似乎简单的逻辑,Spring中又做了哪些复杂的工作呢?对于创建代理的部分,通过之前的分析相信大家已经很熟悉了,但是对于增强器的获取,Spring又是怎么做的呢?
获取对应class/method的增强器
获取指定bean对应的增强器,其中包含两个关键字:增强器与对应。也就是说在 getAdvicesAndAdvisorsForBean函数中,不但要找出增强器,而且还需要判断增强器是否满足要求。
@Override
@Nullable
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
List<Advisor> candidateAdvisors = findCandidateAdvisors();
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
寻找候选增强器
protected List<Advisor> findCandidateAdvisors() {
Assert.state(this.advisorRetrievalHelper != null, "No BeanFactoryAdvisorRetrievalHelper available");
return this.advisorRetrievalHelper.findAdvisorBeans();
}
public List<Advisor> findAdvisorBeans() {
// Determine list of advisor bean names, if not cached already.
String[] advisorNames = this.cachedAdvisorBeanNames;
if (advisorNames == null) {
// 获取BeanFactory中所有对应Advisor.class的类名
// 这里和AspectJ的方式有点不同,AspectJ是获取所有的Object.class,然后通过反射过滤有注解AspectJ的类
advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Advisor.class, true, false);
this.cachedAdvisorBeanNames = advisorNames;
}
if (advisorNames.length == 0) {
return new ArrayList<>();
}
List<Advisor> advisors = new ArrayList<>();
for (String name : advisorNames) {
if (isEligibleBean(name)) {
if (this.beanFactory.isCurrentlyInCreation(name)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping currently created advisor '" + name + "'");
}
}
else {
try {
//直接获取advisorNames的实例,封装进advisors数组
advisors.add(this.beanFactory.getBean(name, Advisor.class));
}
catch (BeanCreationException ex) {
Throwable rootCause = ex.getMostSpecificCause();
if (rootCause instanceof BeanCurrentlyInCreationException) {
BeanCreationException bce = (BeanCreationException) rootCause;
String bceBeanName = bce.getBeanName();
if (bceBeanName != null && this.beanFactory.isCurrentlyInCreation(bceBeanName)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipping advisor '" + name +
"' with dependency on currently created bean: " + ex.getMessage());
}
continue;
}
}
throw ex;
}
}
}
}
return advisors;
}
首先是通过BeanFactoryUtils类提供的工具方法获取所有对应Advisor.class的类,获取办法无非是使用ListableBeanFactory中提供的方法:
String[] getBeanNamesForType(@Nullable Class<?> type, boolean includeNonSingletons, boolean allowEagerInit);
在我们讲解自定义标签时曾经注册了一个类型为 BeanFactoryTransactionAttributeSourceAdvisor 的 bean,而在此 bean 中我们又注入了另外两个Bean,那么此时这个 Bean 就会被开始使用了。因为 BeanFactoryTransactionAttributeSourceAdvisor同样也实现了 Advisor接口,那么在获取所有增强器时自然也会将此bean提取出来, 并随着其他增强器一起在后续的步骤中被织入代理。
候选增强器中寻找到匹配项
当找出对应的增强器后,接下来的任务就是看这些增强器是否与对应的class匹配了,当然不只是class,class内部的方法如果匹配也可以通过验证。
public static List<Advisor> findAdvisorsThatCanApply(List<Advisor> candidateAdvisors, Class<?> clazz) {
if (candidateAdvisors.isEmpty()) {
return candidateAdvisors;
}
List<Advisor> eligibleAdvisors = new ArrayList<>();
// 首先处理引介增强
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor && canApply(candidate, clazz)) {
eligibleAdvisors.add(candidate);
}
}
boolean hasIntroductions = !eligibleAdvisors.isEmpty();
for (Advisor candidate : candidateAdvisors) {
// 引介增强已经处理
if (candidate instanceof IntroductionAdvisor) {
// already processed
continue;
}
// 对于普通bean的处理
if (canApply(candidate, clazz, hasIntroductions)) {
eligibleAdvisors.add(candidate);
}
}
return eligibleAdvisors;
}
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor) {
return ((IntroductionAdvisor) advisor).getClassFilter().matches(targetClass);
}
else if (advisor instanceof PointcutAdvisor) {
PointcutAdvisor pca = (PointcutAdvisor) advisor;
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
}
else {
// It doesn't have a pointcut so we assume it applies.
return true;
}
}
BeanFactoryTransactionAttributeSourceAdvisor 间接实现了PointcutAdvisor。 因此,在canApply函数中的第二个if判断时就会通过判断,会将BeanFactoryTransactionAttributeSourceAdvisor中的getPointcut()方法返回值作为参数继续调用canApply方法,而 getPoint()方法返回的是TransactionAttributeSourcePointcut类型的实例。对于 transactionAttributeSource这个属性大家还有印象吗?这是在解析自定义标签时注入进去的。
private final TransactionAttributeSourcePointcut pointcut = new TransactionAttributeSourcePointcut() {
@Override
@Nullable
protected TransactionAttributeSource getTransactionAttributeSource() {
return transactionAttributeSource;
}
};
那么,使用TransactionAttributeSourcePointcut类型的实例作为函数参数继续跟踪canApply。
public static boolean canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions) {
Assert.notNull(pc, "Pointcut must not be null");
if (!pc.getClassFilter().matches(targetClass)) {
return false;
}
// 此时的pc表示TransactionAttributeSourcePointcut
// pc.getMethodMatcher()返回的正是自身(this)
MethodMatcher methodMatcher = pc.getMethodMatcher();
if (methodMatcher == MethodMatcher.TRUE) {
// No need to iterate the methods if we're matching any method anyway...
return true;
}
IntroductionAwareMethodMatcher introductionAwareMethodMatcher = null;
if (methodMatcher instanceof IntroductionAwareMethodMatcher) {
introductionAwareMethodMatcher = (IntroductionAwareMethodMatcher) methodMatcher;
}
Set<Class<?>> classes = new LinkedHashSet<>();
if (!Proxy.isProxyClass(targetClass)) {
classes.add(ClassUtils.getUserClass(targetClass));
}
//获取对应类的所有接口
classes.addAll(ClassUtils.getAllInterfacesForClassAsSet(targetClass));
//对类进行遍历
for (Class<?> clazz : classes) {
//反射获取类中所有的方法
Method[] methods = ReflectionUtils.getAllDeclaredMethods(clazz);
for (Method method : methods) {
//对类和方法进行增强器匹配
if (introductionAwareMethodMatcher != null ?
introductionAwareMethodMatcher.matches(method, targetClass, hasIntroductions) :
methodMatcher.matches(method, targetClass)) {
return true;
}
}
}
return false;
}
通过上面函数大致可以理清大体脉络,首先获取对应类的所有接口并连同类本身一起遍历,遍历过程中又对类中的方法再次遍历,一旦匹配成功便认为这个类适用于当前增强器。
到这里我们不禁会有疑问,对于事物的配置不仅仅局限于在函数上配置,我们都知道,在类或接口上的配置可以延续到类中的每个函数,那么,如果针对每个函数迸行检测,在类本身上配罝的事务属性岂不是检测不到了吗?带着这个疑问,我们继续探求matcher方法。
做匹配的时候 methodMatcher.matches(method, targetClass)会使用 TransactionAttributeSourcePointcut 类的 matches 方法。
@Override
public boolean matches(Method method, Class<?> targetClass) {
if (TransactionalProxy.class.isAssignableFrom(targetClass)) {
return false;
}
// 自定义标签解析时注入
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null);
}
此时的 tas 表示 AnnotationTransactionAttributeSource 类型,这里会判断tas.getTransactionAttribute(method, targetClass) != null,而 AnnotationTransactionAttributeSource 类型的 getTransactionAttribute 方法如下:
@Override
@Nullable
public TransactionAttribute getTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
Object cacheKey = getCacheKey(method, targetClass);
Object cached = this.attributeCache.get(cacheKey);
//先从缓存中获取TransactionAttribute
if (cached != null) {
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return (TransactionAttribute) cached;
}
}
else {
// 如果缓存中没有,工作又委托给了computeTransactionAttribute函数
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache.
if (txAttr == null) {
// 设置为空
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
if (logger.isDebugEnabled()) {
logger.debug("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
//加入缓存中
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
尝试从缓存加载,如果对应信息没有被缓存的话,工作又委托给了computeTransactionAttribute函数,在computeTransactionAttribute函数中我们终于看到了事务标签的提取过程。
提取事务标签
@Nullable
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
// method代表接口中的方法,specificMethod代表实现类中的方法
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
// First try is the method in the target class.
// 查看方法中是否存在事务声明
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// Second try is the transaction attribute on the target class.
// 查看方法所在类中是否存在事务声明
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
// 如果存在接口,则到接口中去寻找
if (specificMethod != method) {
// Fallback is to look at the original method.
// 查找接口方法
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
// 到接口中的类中去寻找
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
对于事务属性的获取规则相信大家都已经很清楚,如果方法中存在事务属性,则使用方法上的属性,否则使用方法所在的类上的属性,如果方法所在类的属性上还是没有搜寻到对应的事务属性,那么在搜寻接口中的方法,再没有的话,最后尝试搜寻接口的类上面的声明。对于函数computeTransactionAttribute中的逻辑与我们所认识的规则并无差別,但是上面函数中并没有真正的去做搜寻事务属性的逻辑,而是搭建了个执行框架,将搜寻事务属性的任务委托给了 findTransactionAttribute 方法去执行。
@Override
@Nullable
protected TransactionAttribute findTransactionAttribute(Class<?> clazz) {
return determineTransactionAttribute(clazz);
}
@Nullable
protected TransactionAttribute determineTransactionAttribute(AnnotatedElement ae) {
for (TransactionAnnotationParser annotationParser : this.annotationParsers) {
TransactionAttribute attr = annotationParser.parseTransactionAnnotation(ae);
if (attr != null) {
return attr;
}
}
return null;
}
this.annotationParsers 是在当前类 AnnotationTransactionAttributeSource 初始化的时候初始化的,其中的值被加入了 SpringTransactionAnnotationParser,也就是当进行属性获取的时候其实是使用 SpringTransactionAnnotationParser 类的 parseTransactionAnnotation 方法进行解析的。
@Override
@Nullable
public TransactionAttribute parseTransactionAnnotation(AnnotatedElement ae) {
AnnotationAttributes attributes = AnnotatedElementUtils.findMergedAnnotationAttributes(
ae, Transactional.class, false, false);
if (attributes != null) {
return parseTransactionAnnotation(attributes);
}
else {
return null;
}
}
至此,我们终于看到了想看到的获取注解标记的代码。首先会判断当前的类是否含有 Transactional注解,这是事务属性的基础,当然如果有的话会继续调用parseTransactionAnnotation 方法解析详细的属性。
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
Propagation propagation = attributes.getEnum("propagation");
// 解析propagation
rbta.setPropagationBehavior(propagation.value());
Isolation isolation = attributes.getEnum("isolation");
// 解析isolation
rbta.setIsolationLevel(isolation.value());
// 解析timeout
rbta.setTimeout(attributes.getNumber("timeout").intValue());
// 解析readOnly
rbta.setReadOnly(attributes.getBoolean("readOnly"));
// 解析value
rbta.setQualifier(attributes.getString("value"));
ArrayList<RollbackRuleAttribute> rollBackRules = new ArrayList<>();
// 解析rollbackFor
Class<?>[] rbf = attributes.getClassArray("rollbackFor");
for (Class<?> rbRule : rbf) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析rollbackForClassName
String[] rbfc = attributes.getStringArray("rollbackForClassName");
for (String rbRule : rbfc) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析noRollbackFor
Class<?>[] nrbf = attributes.getClassArray("noRollbackFor");
for (Class<?> rbRule : nrbf) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
// 解析noRollbackForClassName
String[] nrbfc = attributes.getStringArray("noRollbackForClassName");
for (String rbRule : nrbfc) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
rbta.getRollbackRules().addAll(rollBackRules);
return rbta;
}
至此,我们终于完成了事务标签的解析。回顾一下,我们现在的任务是找出某个增强器是否适合于对应的类,而是否匹配的关键则在于是否从指定的类或类中的方法中找到对应的事务属性,现在,我们以AccountServiceImpl为例,已经在它的接口AccountServiceImp中找到了事务属性,所以,它是与事务增强器匹配的,也就是它会被事务功能修饰。
至此,事务功能的初始化工作便结束了,当判断某个bean适用于事务增强时,也就是适用于增强器BeanFactoryTransactionAttributeSourceAdvisor
BeanFactoryTransactionAttributeSourceAdvisor 作为 Advisor 的实现类,自然要遵从 Advisor 的处理方式,当代理被调用时会调用这个类的增强方法,也就是此bean的Advice,又因为在解析事务定义标签时我们把Transactionlnterceptor类的bean注人到了 BeanFactoryTransactionAttributeSourceAdvisor中,所以,在调用事务增强器增强的代理类时会首先执行Transactionlnterceptor进行增强,同时,也就是在Transactionlnterceptor类中的invoke方法中完成了整个事务的逻辑。
事务增强器
上一篇文章我们讲解了事务的Advisor是如何注册进Spring容器的,也讲解了Spring是如何将有配置事务的类配置上事务的,实际上也就是用了AOP那一套,也讲解了Advisor,pointcut验证流程,至此,事务的初始化工作都已经完成了,在之后的调用过程,如果代理类的方法被调用,都会调用BeanFactoryTransactionAttributeSourceAdvisor这个Advisor的增强方法,也就是我们还未提到的那个Advisor里面的advise,还记得吗,在自定义标签的时候我们将TransactionInterceptor这个Advice作为bean注册进IOC容器,并且将其注入进Advisor中,这个Advice在代理类的invoke方法中会被封装到拦截器链中,最终事务的功能都在advise中体现,所以我们先来关注一下TransactionInterceptor这个类吧。
TransactionInterceptor类继承自MethodInterceptor,所以调用该类是从其invoke方法开始的,首先预览下这个方法:
@Override
@Nullable
public Object invoke(final MethodInvocation invocation) throws Throwable {
// Work out the target class: may be {@code null}.
// The TransactionAttributeSource should be passed the target class
// as well as the method, which may be from an interface.
Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// Adapt to TransactionAspectSupport's invokeWithinTransaction...
return invokeWithinTransaction(invocation.getMethod(), targetClass, invocation::proceed);
}
重点来了,进入invokeWithinTransaction方法:
@Nullable
protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,
final InvocationCallback invocation) throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
TransactionAttributeSource tas = getTransactionAttributeSource();
// 获取对应事务属性
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
// 获取beanFactory中的transactionManager
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
// 构造方法唯一标识(类.方法,如:service.UserServiceImpl.save)
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
// 声明式事务处理
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// 创建TransactionInfo
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// 执行原方法
// 继续调用方法拦截器链,这里一般将会调用目标类的方法,如:AccountServiceImpl.save方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// 异常回滚
completeTransactionAfterThrowing(txInfo, ex);
// 手动向上抛出异常,则下面的提交事务不会执行
// 如果子事务出异常,则外层事务代码需catch住子事务代码,不然外层事务也会回滚
throw ex;
}
finally {
// 消除信息
cleanupTransactionInfo(txInfo);
}
// 提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
else {
final ThrowableHolder throwableHolder = new ThrowableHolder();
try {
// 编程式事务处理
Object result = ((CallbackPreferringPlatformTransactionManager) tm).execute(txAttr, status -> {
TransactionInfo txInfo = prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
try {
return invocation.proceedWithInvocation();
}
catch (Throwable ex) {
if (txAttr.rollbackOn(ex)) {
// A RuntimeException: will lead to a rollback.
if (ex instanceof RuntimeException) {
throw (RuntimeException) ex;
}
else {
throw new ThrowableHolderException(ex);
}
}
else {
// A normal return value: will lead to a commit.
throwableHolder.throwable = ex;
return null;
}
}
finally {
cleanupTransactionInfo(txInfo);
}
});
// Check result state: It might indicate a Throwable to rethrow.
if (throwableHolder.throwable != null) {
throw throwableHolder.throwable;
}
return result;
}
catch (ThrowableHolderException ex) {
throw ex.getCause();
}
catch (TransactionSystemException ex2) {
if (throwableHolder.throwable != null) {
logger.error("Application exception overridden by commit exception", throwableHolder.throwable);
ex2.initApplicationException(throwableHolder.throwable);
}
throw ex2;
}
catch (Throwable ex2) {
if (throwableHolder.throwable != null) {
logger.error("Application exception overridden by commit exception", throwableHolder.throwable);
}
throw ex2;
}
}
}
创建事务Info对象
我们先分析事务创建的过程。
protected TransactionInfo createTransactionIfNecessary(@Nullable PlatformTransactionManager tm,
@Nullable TransactionAttribute txAttr, final String joinpointIdentification) {
// If no name specified, apply method identification as transaction name.
// 如果没有名称指定则使用方法唯一标识,并使用DelegatingTransactionAttribute封装txAttr
if (txAttr != null && txAttr.getName() == null) {
txAttr = new DelegatingTransactionAttribute(txAttr) {
@Override
public String getName() {
return joinpointIdentification;
}
};
}
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
// 获取TransactionStatus
status = tm.getTransaction(txAttr);
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Skipping transactional joinpoint [" + joinpointIdentification +
"] because no transaction manager has been configured");
}
}
}
// 根据指定的属性与status准备一个TransactionInfo
return prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
}
对于createTransactionlfNecessary函数主要做了这样几件事情。
(1)使用 DelegatingTransactionAttribute 封装传入的 TransactionAttribute 实例。
对于传入的TransactionAttribute类型的参数txAttr,当前的实际类型是RuleBasedTransactionAttribute,是由获取事务属性时生成,主要用于数据承载,而这里之所以使用DelegatingTransactionAttribute进行封装,当然是提供了更多的功能。
(2)获取事务。
事务处理当然是以事务为核心,那么获取事务就是最重要的事情。
(3)构建事务信息。
根据之前几个步骤获取的信息构建Transactionlnfo并返回。
获取事务
其中核心是在getTransaction方法中:
@Override
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException {
// 获取一个transaction
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
if (definition == null) {
definition = new DefaultTransactionDefinition();
}
// 如果在这之前已经存在事务了,就进入存在事务的方法中
if (isExistingTransaction(transaction)) {
return handleExistingTransaction(definition, transaction, debugEnabled);
}
// 事务超时设置验证
if (definition.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) {
throw new InvalidTimeoutException("Invalid transaction timeout", definition.getTimeout());
}
// 走到这里说明此时没有存在事务,如果传播特性是MANDATORY时抛出异常
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
// 如果此时不存在事务,当传播特性是REQUIRED或NEW或NESTED都会进入if语句块
else if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
// PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED都需要新建事务
// 因为此时不存在事务,将null挂起
SuspendedResourcesHolder suspendedResources = suspend(null);
if (debugEnabled) {
logger.debug("Creating new transaction with name [" + definition.getName() + "]: " + definition);
}
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// new一个status,存放刚刚创建的transaction,然后将其标记为新事务!
// 这里transaction后面一个参数决定是否是新事务!
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 新开一个连接的地方,非常重要
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException | Error ex) {
resume(null, suspendedResources);
throw ex;
}
}
else {
// Create "empty" transaction: no actual transaction, but potentially synchronization.
if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT && logger.isWarnEnabled()) {
logger.warn("Custom isolation level specified but no actual transaction initiated; " +
"isolation level will effectively be ignored: " + definition);
}
// 其他的传播特性一律返回一个空事务,transaction = null
//当前不存在事务,且传播机制=PROPAGATION_SUPPORTS/PROPAGATION_NOT_SUPPORTED/PROPAGATION_NEVER,这三种情况,创建“空”事务
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(definition, null, true, newSynchronization, debugEnabled, null);
}
}
先来看看transaction是如何被创建出来的:
@Override
protected Object doGetTransaction() {
// 这里DataSourceTransactionObject是事务管理器的一个内部类
// DataSourceTransactionObject就是一个transaction,这里new了一个出来
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
txObject.setSavepointAllowed(isNestedTransactionAllowed());
// 解绑与绑定的作用在此时体现,如果当前线程有绑定的话,将会取出holder
// 第一次conHolder肯定是null
ConnectionHolder conHolder =
(ConnectionHolder) TransactionSynchronizationManager.getResource(obtainDataSource());
// 此时的holder被标记成一个旧holder
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
创建transaction过程很简单,接着就会判断当前是否存在事务:
@Override
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
return (txObject.hasConnectionHolder() && txObject.getConnectionHolder().isTransactionActive());
}
public boolean hasConnectionHolder() {
return (this.connectionHolder != null);
}
这里判断是否存在事务的依据主要是获取holder中的transactionActive变量是否为true,如果是第一次进入事务,holder直接为null判断不存在了,如果是第二次进入事务transactionActive变量是为true的(后面会提到是在哪里把它变成true的),由此来判断当前是否已经存在事务了。
至此,源码分成了2条处理线
1.当前已存在事务:isExistingTransaction()判断是否存在事务,存在事务handleExistingTransaction()根据不同传播机制不同处理
2.当前不存在事务: 不同传播机制不同处理
当前不存在事务
如果不存在事务,传播特性又是REQUIRED或NEW或NESTED,将会先挂起null,这个挂起方法我们后面再讲,然后创建一个DefaultTransactionStatus ,并将其标记为新事务,然后执行doBegin(transaction, definition);这个方法也是一个关键方法
神秘又关键的status对象
TransactionStatus接口
public interface TransactionStatus extends SavepointManager, Flushable {
// 返回当前事务是否为新事务(否则将参与到现有事务中,或者可能一开始就不在实际事务中运行)
boolean isNewTransaction();
// 返回该事务是否在内部携带保存点,也就是说,已经创建为基于保存点的嵌套事务。
boolean hasSavepoint();
// 设置事务仅回滚。
void setRollbackOnly();
// 返回事务是否已标记为仅回滚
boolean isRollbackOnly();
// 将会话刷新到数据存储区
@Override
void flush();
// 返回事物是否已经完成,无论提交或者回滚。
boolean isCompleted();
}
再来看看实现类DefaultTransactionStatus
DefaultTransactionStatus
public class DefaultTransactionStatus extends AbstractTransactionStatus {
//事务对象
@Nullable
private final Object transaction;
//事务对象
private final boolean newTransaction;
private final boolean newSynchronization;
private final boolean readOnly;
private final boolean debug;
//事务对象
@Nullable
private final Object suspendedResources;
public DefaultTransactionStatus(
@Nullable Object transaction, boolean newTransaction, boolean newSynchronization,
boolean readOnly, boolean debug, @Nullable Object suspendedResources) {
this.transaction = transaction;
this.newTransaction = newTransaction;
this.newSynchronization = newSynchronization;
this.readOnly = readOnly;
this.debug = debug;
this.suspendedResources = suspendedResources;
}
//略...
}
我们看看这行代码 DefaultTransactionStatus status = newTransactionStatus( definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 这里是构造一个status对象的方法
protected DefaultTransactionStatus newTransactionStatus(
TransactionDefinition definition, @Nullable Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, @Nullable Object suspendedResources) {
boolean actualNewSynchronization = newSynchronization &&
!TransactionSynchronizationManager.isSynchronizationActive();
return new DefaultTransactionStatus(
transaction, newTransaction, actualNewSynchronization,
definition.isReadOnly(), debug, suspendedResources);
}
实际上就是封装了事务属性definition,新创建的transaction,并且将事务状态属性设置为新事务,最后一个参数为被挂起的事务。
简单了解一下关键参数即可:
第二个参数transaction:事务对象,在一开头就有创建,其就是事务管理器的一个内部类。 第三个参数newTransaction:布尔值,一个标识,用于判断是否是新的事务,用于提交或者回滚方法中,是新的才会提交或者回滚。 最后一个参数suspendedResources:被挂起的对象资源,挂起操作会返回旧的holder,将其与一些事务属性一起封装成一个对象,就是这个suspendedResources这个对象了,它会放在status中,在最后的清理工作方法中判断status中是否有这个挂起对象,如果有会恢复它
接着我们来看看关键代码 doBegin(transaction, definition);
1 @Override
2 protected void doBegin(Object transaction, TransactionDefinition definition) {
3 DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
4 Connection con = null;
5
6 try {
7 // 判断如果transaction没有holder的话,才去从dataSource中获取一个新连接
8 if (!txObject.hasConnectionHolder() ||
9 txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
10 //通过dataSource获取连接
11 Connection newCon = this.dataSource.getConnection();
12 if (logger.isDebugEnabled()) {
13 logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
14 }
15 // 所以,只有transaction中的holder为空时,才会设置为新holder
16 // 将获取的连接封装进ConnectionHolder,然后封装进transaction的connectionHolder属性
17 txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
18 }
19 //设置新的连接为事务同步中
20 txObject.getConnectionHolder().setSynchronizedWithTransaction(true);
21 con = txObject.getConnectionHolder().getConnection();
22 //conn设置事务隔离级别,只读
23 Integer previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition);
24 txObject.setPreviousIsolationLevel(previousIsolationLevel);//DataSourceTransactionObject设置事务隔离级别
25
26 // 如果是自动提交切换到手动提交
27 if (con.getAutoCommit()) {
28 txObject.setMustRestoreAutoCommit(true);
29 if (logger.isDebugEnabled()) {
30 logger.debug("Switching JDBC Connection [" + con + "] to manual commit");
31 }
32 con.setAutoCommit(false);
33 }
34 // 如果只读,执行sql设置事务只读
35 prepareTransactionalConnection(con, definition);
36 // 设置connection持有者的事务开启状态
37 txObject.getConnectionHolder().setTransactionActive(true);
38
39 int timeout = determineTimeout(definition);
40 if (timeout != TransactionDefinition.TIMEOUT_DEFAULT) {
41 // 设置超时秒数
42 txObject.getConnectionHolder().setTimeoutInSeconds(timeout);
43 }
44
45 // 将当前获取到的连接绑定到当前线程
46 if (txObject.isNewConnectionHolder()) {
47 TransactionSynchronizationManager.bindResource(getDataSource(), txObject.getConnectionHolder());
48 }
49 }catch (Throwable ex) {
50 if (txObject.isNewConnectionHolder()) {
51 DataSourceUtils.releaseConnection(con, this.dataSource);
52 txObject.setConnectionHolder(null, false);
53 }
54 throw new CannotCreateTransactionException("Could not open JDBC Connection for transaction", ex);
55 }
56 }
conn设置事务隔离级别,只读
@Nullable
public static Integer prepareConnectionForTransaction(Connection con, @Nullable TransactionDefinition definition)
throws SQLException {
Assert.notNull(con, "No Connection specified");
// Set read-only flag.
// 设置数据连接的只读标识
if (definition != null && definition.isReadOnly()) {
try {
if (logger.isDebugEnabled()) {
logger.debug("Setting JDBC Connection [" + con + "] read-only");
}
con.setReadOnly(true);
}
catch (SQLException | RuntimeException ex) {
Throwable exToCheck = ex;
while (exToCheck != null) {
if (exToCheck.getClass().getSimpleName().contains("Timeout")) {
// Assume it's a connection timeout that would otherwise get lost: e.g. from JDBC 4.0
throw ex;
}
exToCheck = exToCheck.getCause();
}
// "read-only not supported" SQLException -> ignore, it's just a hint anyway
logger.debug("Could not set JDBC Connection read-only", ex);
}
}
// Apply specific isolation level, if any.
// 设置数据库连接的隔离级别
Integer previousIsolationLevel = null;
if (definition != null && definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT) {
if (logger.isDebugEnabled()) {
logger.debug("Changing isolation level of JDBC Connection [" + con + "] to " +
definition.getIsolationLevel());
}
int currentIsolation = con.getTransactionIsolation();
if (currentIsolation != definition.getIsolationLevel()) {
previousIsolationLevel = currentIsolation;
con.setTransactionIsolation(definition.getIsolationLevel());
}
}
return previousIsolationLevel;
}
我们看到都是通过 Connection 去设置
线程变量的绑定
我们看 doBegin 方法的47行,将当前获取到的连接绑定到当前线程,绑定与解绑围绕一个线程变量,此变量在TransactionSynchronizationManager类中:
private static final ThreadLocal<Map<Object, Object>> resources = new NamedThreadLocal<>("Transactional resources");
这是一个 static final 修饰的 线程变量,存储的是一个Map,我们来看看47行的静态方法,bindResource
public static void bindResource(Object key, Object value) throws IllegalStateException {
// 从上面可知,线程变量是一个Map,而这个Key就是dataSource
// 这个value就是holder
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Assert.notNull(value, "Value must not be null");
// 获取这个线程变量Map
Map<Object, Object> map = resources.get();
// set ThreadLocal Map if none found
if (map == null) {
map = new HashMap<>();
resources.set(map);
}
// 将新的holder作为value,dataSource作为key放入当前线程Map中
Object oldValue = map.put(actualKey, value);
// Transparently suppress a ResourceHolder that was marked as void...
if (oldValue instanceof ResourceHolder && ((ResourceHolder) oldValue).isVoid()) {
oldValue = null;
}
if (oldValue != null) {
throw new IllegalStateException("Already value [" + oldValue + "] for key [" +
actualKey + "] bound to thread [" + Thread.currentThread().getName() + "]");
} Thread.currentThread().getName() + "]");
}
// 略...
}
扩充知识点
这里再扩充一点,mybatis中获取的数据库连接,就是根据 dataSource 从ThreadLocal中获取的
以查询举例,会调用Executor#doQuery方法:

最终会调用DataSourceUtils#doGetConnection获取,真正的数据库连接,其中TransactionSynchronizationManager中保存的就是方法调用前,spring增强方法中绑定到线程的connection,从而保证整个事务过程中connection的一致性
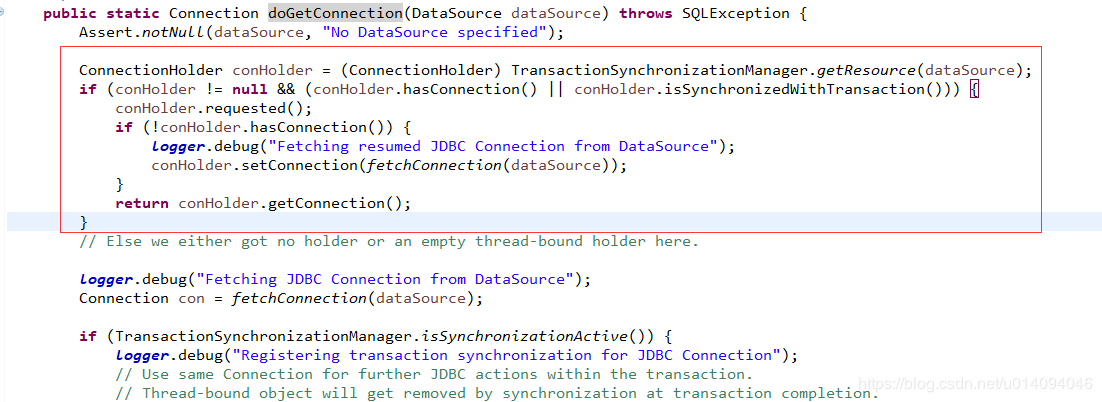
我们看看TransactionSynchronizationManager.getResource(Object key)这个方法
@Nullable
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Object value = doGetResource(actualKey);
if (value != null && logger.isTraceEnabled()) {
logger.trace("Retrieved value [" + value + "] for key [" + actualKey + "] bound to thread [" +
Thread.currentThread().getName() + "]");
}
return value;
}
@Nullable
private static Object doGetResource(Object actualKey) {
Map<Object, Object> map = resources.get();
if (map == null) {
return null;
}
Object value = map.get(actualKey);
// Transparently remove ResourceHolder that was marked as void...
if (value instanceof ResourceHolder && ((ResourceHolder) value).isVoid()) {
map.remove(actualKey);
// Remove entire ThreadLocal if empty...
if (map.isEmpty()) {
resources.remove();
}
value = null;
}
return value;
}
就是从线程变量的Map中根据 DataSource获取 ConnectionHolder
已经存在的事务
前面已经提到,第一次事务开始时必会新创一个holder然后做绑定操作,此时线程变量是有holder的且avtive为true,如果第二个事务进来,去new一个transaction之后去线程变量中取holder,holder是不为空的且active是为true的,所以会进入handleExistingTransaction方法:
1 private TransactionStatus handleExistingTransaction(
2 TransactionDefinition definition, Object transaction, boolean debugEnabled)
3 throws TransactionException {
4 // 1.NERVER(不支持当前事务;如果当前事务存在,抛出异常)报错
5 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
6 throw new IllegalTransactionStateException(
7 "Existing transaction found for transaction marked with propagation 'never'");
8 }
9 // 2.NOT_SUPPORTED(不支持当前事务,现有同步将被挂起)挂起当前事务,返回一个空事务
10 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
11 if (debugEnabled) {
12 logger.debug("Suspending current transaction");
13 }
14 // 这里会将原来的事务挂起,并返回被挂起的对象
15 Object suspendedResources = suspend(transaction);
16 boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
17 // 这里可以看到,第二个参数transaction传了一个空事务,第三个参数false为旧标记
18 // 最后一个参数就是将前面挂起的对象封装进新的Status中,当前事务执行完后,就恢复suspendedResources
19 return prepareTransactionStatus(definition, null, false, newSynchronization, debugEnabled, suspendedResources);
20 }
21 // 3.REQUIRES_NEW挂起当前事务,创建新事务
22 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
23 if (debugEnabled) {
24 logger.debug("Suspending current transaction, creating new transaction with name [" +
25 definition.getName() + "]");
26 }
27 // 将原事务挂起,此时新建事务,不与原事务有关系
28 // 会将transaction中的holder设置为null,然后解绑!
29 SuspendedResourcesHolder suspendedResources = suspend(transaction);
30 try {
31 boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
32 // new一个status出来,传入transaction,并且为新事务标记,然后传入挂起事务
33 DefaultTransactionStatus status = newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
34 // 这里也做了一次doBegin,此时的transaction中holer是为空的,因为之前的事务被挂起了
35 // 所以这里会取一次新的连接,并且绑定!
36 doBegin(transaction, definition);
37 prepareSynchronization(status, definition);
38 return status;
39 }
40 catch (RuntimeException beginEx) {
41 resumeAfterBeginException(transaction, suspendedResources, beginEx);
42 throw beginEx;
43 }
44 catch (Error beginErr) {
45 resumeAfterBeginException(transaction, suspendedResources, beginErr);
46 throw beginErr;
47 }
48 }
49 // 如果此时的传播特性是NESTED,不会挂起事务
50 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
51 if (!isNestedTransactionAllowed()) {
52 throw new NestedTransactionNotSupportedException(
53 "Transaction manager does not allow nested transactions by default - " +
54 "specify 'nestedTransactionAllowed' property with value 'true'");
55 }
56 if (debugEnabled) {
57 logger.debug("Creating nested transaction with name [" + definition.getName() + "]");
58 }
59 // 这里如果是JTA事务管理器,就不可以用savePoint了,将不会进入此方法
60 if (useSavepointForNestedTransaction()) {
61 // 这里不会挂起事务,说明NESTED的特性是原事务的子事务而已
62 // new一个status,传入transaction,传入旧事务标记,传入挂起对象=null
63 DefaultTransactionStatus status =prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
64 // 这里是NESTED特性特殊的地方,在先前存在事务的情况下会建立一个savePoint
65 status.createAndHoldSavepoint();
66 return status;
67 }
68 else {
69 // JTA事务走这个分支,创建新事务
70 boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
71 DefaultTransactionStatus status = newTransactionStatus(
72 definition, transaction, true, newSynchronization, debugEnabled, null);
73 doBegin(transaction, definition);
74 prepareSynchronization(status, definition);
75 return status;
76 }
77 }
78
79 // 到这里PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY,存在事务加入事务即可,标记为旧事务,空挂起
80 boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
81 return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
82 }
对于已经存在事务的处理过程中,我们看到了很多熟悉的操作,但是,也有些不同的地方,函数中对已经存在的事务处理考虑两种情况。
(1)PROPAGATION_REQUIRES_NEW表示当前方法必须在它自己的事务里运行,一个新的事务将被启动,而如果有一个事务正在运行的话,则在这个方法运行期间被挂起。而Spring中对于此种传播方式的处理与新事务建立最大的不同点在于使用suspend方法将原事务挂起。 将信息挂起的目的当然是为了在当前事务执行完毕后在将原事务还原。
(2)PROPAGATION_NESTED表示如果当前正有一个事务在运行中,则该方法应该运行在一个嵌套的事务中,被嵌套的事务可以独立于封装事务进行提交或者回滚,如果封装事务不存在,行为就像PROPAGATION_REQUIRES_NEW。对于嵌入式事务的处理,Spring中主要考虑了两种方式的处理。
- Spring中允许嵌入事务的时候,则首选设置保存点的方式作为异常处理的回滚。
- 对于其他方式,比如JTA无法使用保存点的方式,那么处理方式与PROPAGATION_ REQUIRES_NEW相同,而一旦出现异常,则由Spring的事务异常处理机制去完成后续操作。
对于挂起操作的主要目的是记录原有事务的状态,以便于后续操作对事务的恢复
小结
到这里我们可以知道,在当前存在事务的情况下,根据传播特性去决定是否为新事务,是否挂起当前事务。
NOT_SUPPORTED :会挂起事务,不运行doBegin方法传空transaction,标记为旧事务。封装status对象:
return prepareTransactionStatus(definition, null, false, newSynchronization, debugEnabled, suspendedResources)
REQUIRES_NEW :将会挂起事务且运行doBegin方法,标记为新事务。封装status对象:
DefaultTransactionStatus status = newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
NESTED :不会挂起事务且不会运行doBegin方法,标记为旧事务,但会创建savePoint。封装status对象:
DefaultTransactionStatus status =prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
其他事务例如REQUIRED :不会挂起事务,封装原有的transaction不会运行doBegin方法,标记旧事务,封装status对象:
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
挂起
对于挂起操作的主要目的是记录原有事务的状态,以便于后续操作对事务的恢复:
@Nullable
protected final SuspendedResourcesHolder suspend(@Nullable Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
// 这里是真正做挂起的方法,这里返回的是一个holder
suspendedResources = doSuspend(transaction);
}
// 这里将名称、隔离级别等信息从线程变量中取出并设置对应属性为null到线程变量
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
// 将事务各个属性与挂起的holder一并封装进SuspendedResourcesHolder对象中
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException | Error ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
doSuspend挂起操作
@Override
protected Object doSuspend(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 将transaction中的holder属性设置为空
txObject.setConnectionHolder(null);
// ConnnectionHolder从线程变量中解绑!
return TransactionSynchronizationManager.unbindResource(obtainDataSource());
}
我们来看看 unbindResource
private static Object doUnbindResource(Object actualKey) {
// 取得当前线程的线程变量Map
Map<Object, Object> map = resources.get();
if (map == null) {
return null;
}
// 将key为dataSourece的value移除出Map,然后将旧的Holder返回
Object value = map.remove(actualKey);
// Remove entire ThreadLocal if empty...
// 如果此时map为空,直接清除线程变量
if (map.isEmpty()) {
resources.remove();
}
// Transparently suppress a ResourceHolder that was marked as void...
if (value instanceof ResourceHolder && ((ResourceHolder) value).isVoid()) {
value = null;
}
if (value != null && logger.isTraceEnabled()) {
logger.trace("Removed value [" + value + "] for key [" + actualKey + "] from thread [" +
Thread.currentThread().getName() + "]");
}
// 将旧Holder返回
return value;
}
可以回头看一下解绑操作的介绍。这里挂起主要干了三件事:
- 将transaction中的holder属性设置为空
- 解绑(会返回线程中的那个旧的holder出来,从而封装到SuspendedResourcesHolder对象中)
- 将SuspendedResourcesHolder放入status中,方便后期子事务完成后,恢复外层事务
事务的回滚和提交
上一篇文章讲解了获取事务,并且通过获取的connection设置只读、隔离级别等,这篇文章讲解剩下的事务的回滚和提交
回滚处理
之前已经完成了目标方法运行前的事务准备工作,而这些准备工作最大的目的无非是对于程序没有按照我们期待的那样进行,也就是出现特定的错误,那么,当出现错误的时候,Spring是怎么对数据进行恢复的呢?
1 protected void completeTransactionAfterThrowing(@Nullable TransactionInfo txInfo, Throwable ex) {
2 // 当抛出异常时首先判断当前是否存在事务,这是基础依据
3 if (txInfo != null && txInfo.getTransactionStatus() != null) {
4 if (logger.isTraceEnabled()) {
5 logger.trace("Completing transaction for [" + txInfo.getJoinpointIdentification() +
6 "] after exception: " + ex);
7 }
8 // 这里判断是否回滚默认的依据是抛出的异常是否是RuntimeException或者是Error的类型
9 if (txInfo.transactionAttribute != null && txInfo.transactionAttribute.rollbackOn(ex)) {
10 try {
11 txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
12 }
13 catch (TransactionSystemException ex2) {
14 logger.error("Application exception overridden by rollback exception", ex);
15 ex2.initApplicationException(ex);
16 throw ex2;
17 }
18 catch (RuntimeException | Error ex2) {
19 logger.error("Application exception overridden by rollback exception", ex);
20 throw ex2;
21 }
22 }
23 else {
24 // We don't roll back on this exception.
25 // Will still roll back if TransactionStatus.isRollbackOnly() is true.
26 // 如果不满足回滚条件即使抛出异常也同样会提交
27 try {
28 txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
29 }
30 catch (TransactionSystemException ex2) {
31 logger.error("Application exception overridden by commit exception", ex);
32 ex2.initApplicationException(ex);
33 throw ex2;
34 }
35 catch (RuntimeException | Error ex2) {
36 logger.error("Application exception overridden by commit exception", ex);
37 throw ex2;
38 }
39 }
40 }
41 }
在对目标方法的执行过程中,一旦出现Throwable就会被引导至此方法处理,但是并不代表所有的Throwable都会被回滚处理,比如我们最常用的Exception,默认是不会被处理的。 默认情况下,即使出现异常,数据也会被正常提交,而这个关键的地方就是在txlnfo.transactionAttribute.rollbackOn(ex)这个函数。
回滚条件
@Override
public boolean rollbackOn(Throwable ex) {
return (ex instanceof RuntimeException || ex instanceof Error);
}
默认情况下Spring中的亊务异常处理机制只对RuntimeException和Error两种情况感兴趣,我们可以利用注解方式来改变,例如:
@Transactional(propagation = Propagation.REQUIRED, rollbackFor = Exception.class)
回滚处理
当然,一旦符合回滚条件,那么Spring就会将程序引导至回滚处理函数中。
1 private void processRollback(DefaultTransactionStatus status, boolean unexpected) {
2 try {
3 boolean unexpectedRollback = unexpected;
4
5 try {
6 triggerBeforeCompletion(status);
7 // 如果status有savePoint,说明此事务是NESTD,且为子事务,只回滚到savePoint
8 if (status.hasSavepoint()) {
9 if (status.isDebug()) {
10 logger.debug("Rolling back transaction to savepoint");
11 }
12 //回滚到保存点
13 status.rollbackToHeldSavepoint();
14 }
15 // 如果此时的status显示是新的事务才进行回滚
16 else if (status.isNewTransaction()) {
17 if (status.isDebug()) {
18 logger.debug("Initiating transaction rollback");
19 }
20 //如果此时是子事务,我们想想哪些类型的事务会进入到这里?
21 //回顾上一篇文章中已存在事务的处理,NOT_SUPPORTED创建的Status是prepareTransactionStatus(definition, null, false...),说明是旧事物,并且事务为null,不会进入
22 //REQUIRES_NEW会创建一个新的子事务,Status是newTransactionStatus(definition, transaction, true...)说明是新事务,将会进入到这个分支
23 //PROPAGATION_NESTED创建的Status是prepareTransactionStatus(definition, transaction, false...)是旧事物,使用的是外层的事务,不会进入
24 //PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY存在事务加入事务即可,标记为旧事务,prepareTransactionStatus(definition, transaction, false..)
25 //说明当子事务,只有REQUIRES_NEW会进入到这里进行回滚
26 doRollback(status);
27 }
28 else {
29 // Participating in larger transaction
30 // 如果status中有事务,进入下面
31 // 根据上面分析,PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY创建的Status是prepareTransactionStatus(definition, transaction, false..)
32 // 如果此事务时子事务,表示存在事务,并且事务为旧事物,将进入到这里
33 if (status.hasTransaction()) {
34 if (status.isLocalRollbackOnly() || isGlobalRollbackOnParticipationFailure()) {
35 if (status.isDebug()) {
36 logger.debug("Participating transaction failed - marking existing transaction as rollback-only");
37 }
38 // 对status中的transaction作一个回滚了的标记,并不会立即回滚
39 doSetRollbackOnly(status);
40 }
41 else {
42 if (status.isDebug()) {
43 logger.debug("Participating transaction failed - letting transaction originator decide on rollback");
44 }
45 }
46 }
47 else {
48 logger.debug("Should roll back transaction but cannot - no transaction available");
49 }
50 // Unexpected rollback only matters here if we're asked to fail early
51 if (!isFailEarlyOnGlobalRollbackOnly()) {
52 unexpectedRollback = false;
53 }
54 }
55 }
56 catch (RuntimeException | Error ex) {
57 triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
58 throw ex;
59 }
60
61 triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
62
63 }
64 finally {
65 // 清空记录的资源并将挂起的资源恢复
66 // 子事务结束了,之前挂起的事务就要恢复了
67 cleanupAfterCompletion(status);
68 }
69 }
我i们先来看看第13行,回滚到保存点的代码,根据保存点回滚的实现方式其实是根据底层的数据库连接进行的。回滚到保存点之后,也要释放掉当前的保存点
public void rollbackToHeldSavepoint() throws TransactionException {
Object savepoint = getSavepoint();
if (savepoint == null) {
throw new TransactionUsageException(
"Cannot roll back to savepoint - no savepoint associated with current transaction");
}
getSavepointManager().rollbackToSavepoint(savepoint);
getSavepointManager().releaseSavepoint(savepoint);
setSavepoint(null);
}
这里使用的是JDBC的方式进行数据库连接,那么getSavepointManager()函数返回的是JdbcTransactionObjectSupport,也就是说上面函数会调用JdbcTransactionObjectSupport 中的 rollbackToSavepoint 方法。
@Override
public void rollbackToSavepoint(Object savepoint) throws TransactionException {
ConnectionHolder conHolder = getConnectionHolderForSavepoint();
try {
conHolder.getConnection().rollback((Savepoint) savepoint);
conHolder.resetRollbackOnly();
}
catch (Throwable ex) {
throw new TransactionSystemException("Could not roll back to JDBC savepoint", ex);
}
}
当之前已经保存的事务信息中的事务为新事物,那么直接回滚。常用于单独事务的处理。对于没有保存点的回滚,Spring同样是使用底层数据库连接提供的API来操作的。由于我们使用的是DataSourceTransactionManager,那么doRollback函数会使用此类中的实现:
@Override
protected void doRollback(DefaultTransactionStatus status) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
Connection con = txObject.getConnectionHolder().getConnection();
if (status.isDebug()) {
logger.debug("Rolling back JDBC transaction on Connection [" + con + "]");
}
try {
con.rollback();
}
catch (SQLException ex) {
throw new TransactionSystemException("Could not roll back JDBC transaction", ex);
}
}
当前事务信息中表明是存在事务的,又不属于以上两种情况,只做回滚标识,等到提交的时候再判断是否有回滚标识,下面回滚的时候再介绍,子事务中状态为PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY回滚的时候将会标记为回滚标识,我们来看看是怎么标记的
@Override
protected void doSetRollbackOnly(DefaultTransactionStatus status) {
// 将status中的transaction取出
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
if (status.isDebug()) {
logger.debug("Setting JDBC transaction [" + txObject.getConnectionHolder().getConnection() +
"] rollback-only");
}
// transaction执行标记回滚
txObject.setRollbackOnly();
}
public void setRollbackOnly() {
// 这里将transaction里面的connHolder标记回滚
getConnectionHolder().setRollbackOnly();
}
public void setRollbackOnly() {
// 将holder中的这个属性设置成true
this.rollbackOnly = true;
}
我们看到将status中的Transaction中的 ConnectionHolder的属性rollbackOnly标记为true,这里我们先不多考虑,等到下面提交的时候再介绍
我们简单的做个小结
- status.hasSavepoint()如果status中有savePoint,只回滚到savePoint!
- status.isNewTransaction()如果status是一个新事务,才会真正去回滚!
- status.hasTransaction()如果status有事务,将会对staus中的事务标记!
事务提交
在事务的执行并没有出现任何的异常,也就意味着事务可以走正常事务提交的流程了。这里回到流程中去,看看commitTransactionAfterReturning(txInfo)方法做了什么:
protected void commitTransactionAfterReturning(@Nullable TransactionInfo txInfo) {
if (txInfo != null && txInfo.getTransactionStatus() != null) {
if (logger.isTraceEnabled()) {
logger.trace("Completing transaction for [" + txInfo.getJoinpointIdentification() + "]");
}
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
}
在真正的数据提交之前,还需要做个判断。不知道大家还有没有印象,在我们分析事务异常处理规则的时候,当某个事务既没有保存点又不是新事物,Spring对它的处理方式只是设置一个回滚标识。这个回滚标识在这里就会派上用场了,如果子事务状态是
PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY,将会在外层事务中运行,回滚的时候,并不执行回滚,只是标记一下回滚状态,当外层事务提交的时候,会先判断ConnectionHolder中的回滚状态,如果已经标记为回滚,则不会提交,而是外层事务进行回滚
1 @Override
2 public final void commit(TransactionStatus status) throws TransactionException {
3 if (status.isCompleted()) {
4 throw new IllegalTransactionStateException(
5 "Transaction is already completed - do not call commit or rollback more than once per transaction");
6 }
7
8 DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
9 // 如果在事务链中已经被标记回滚,那么不会尝试提交事务,直接回滚
10 if (defStatus.isLocalRollbackOnly()) {
11 if (defStatus.isDebug()) {
12 logger.debug("Transactional code has requested rollback");
13 }
14 processRollback(defStatus, false);
15 return;
16 }
17
18 if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
19 if (defStatus.isDebug()) {
20 logger.debug("Global transaction is marked as rollback-only but transactional code requested commit");
21 }
22 // 这里会进行回滚,并且抛出一个异常
23 processRollback(defStatus, true);
24 return;
25 }
26
27 // 如果没有被标记回滚之类的,这里才真正判断是否提交
28 processCommit(defStatus);
29 }
而当事务执行一切都正常的时候,便可以真正地进入提交流程了。
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
boolean unexpectedRollback = false;
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
// 判断是否有savePoint
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Releasing transaction savepoint");
}
unexpectedRollback = status.isGlobalRollbackOnly();
// 不提交,仅仅是释放savePoint
status.releaseHeldSavepoint();
}
// 判断是否是新事务
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction commit");
}
unexpectedRollback = status.isGlobalRollbackOnly();
// 这里才真正去提交!
doCommit(status);
}
else if (isFailEarlyOnGlobalRollbackOnly()) {
unexpectedRollback = status.isGlobalRollbackOnly();
}
// Throw UnexpectedRollbackException if we have a global rollback-only
// marker but still didn't get a corresponding exception from commit.
if (unexpectedRollback) {
throw new UnexpectedRollbackException(
"Transaction silently rolled back because it has been marked as rollback-only");
}
}
catch (UnexpectedRollbackException ex) {
// 略...
}
// Trigger afterCommit callbacks, with an exception thrown there
// propagated to callers but the transaction still considered as committed.
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
}
}
finally {
// 清空记录的资源并将挂起的资源恢复
cleanupAfterCompletion(status);
}
}
- status.hasSavepoint()如果status有savePoint,说明此时的事务是嵌套事务NESTED,这个事务外面还有事务,这里不提交,只是释放保存点。这里也可以看出来NESTED的传播行为了。
- status.isNewTransaction()如果是新的事务,才会提交!!,这里如果是子事务,只有PROPAGATION_NESTED状态才会走到这里提交,也说明了此状态子事务提交和外层事务是隔离的
- 如果是子事务,PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY这几种状态是旧事物,提交的时候将什么都不做,因为他们是运行在外层事务当中,如果子事务没有回滚,将由外层事务一次性提交
如果程序流通过了事务的层层把关,最后顺利地进入了提交流程,那么同样,Spring会将事务提交的操作引导至底层数据库连接的API,进行事务提交。
@Override
protected void doCommit(DefaultTransactionStatus status) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
Connection con = txObject.getConnectionHolder().getConnection();
if (status.isDebug()) {
logger.debug("Committing JDBC transaction on Connection [" + con + "]");
}
try {
con.commit();
}
catch (SQLException ex) {
throw new TransactionSystemException("Could not commit JDBC transaction", ex);
}
}
从回滚和提交的逻辑看,只有status是新事务,才会进行提交或回滚,需要读者记好这个状态–>是否是新事务。
清理工作
而无论是在异常还是没有异常的流程中,最后的finally块中都会执行一个方法cleanupAfterCompletion(status)
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
// 设置完成状态
status.setCompleted();
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.clear();
}
if (status.isNewTransaction()) {
doCleanupAfterCompletion(status.getTransaction());
}
if (status.getSuspendedResources() != null) {
if (status.isDebug()) {
logger.debug("Resuming suspended transaction after completion of inner transaction");
}
Object transaction = (status.hasTransaction() ? status.getTransaction() : null);
// 结束之前事务的挂起状态
resume(transaction, (SuspendedResourcesHolder) status.getSuspendedResources());
}
}
如果是新事务需要做些清除资源的工作?
@Override
protected void doCleanupAfterCompletion(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// Remove the connection holder from the thread, if exposed.
if (txObject.isNewConnectionHolder()) {
// 将数据库连接从当前线程中解除绑定,解绑过程我们在挂起的过程中已经分析过
TransactionSynchronizationManager.unbindResource(obtainDataSource());
}
// Reset connection.
// 释放连接,当前事务完成,则需要将连接释放,如果有线程池,则重置数据库连接,放回线程池
Connection con = txObject.getConnectionHolder().getConnection();
try {
if (txObject.isMustRestoreAutoCommit()) {
// 恢复数据库连接的自动提交属性
con.setAutoCommit(true);
}
// 重置数据库连接
DataSourceUtils.resetConnectionAfterTransaction(con, txObject.getPreviousIsolationLevel());
}
catch (Throwable ex) {
logger.debug("Could not reset JDBC Connection after transaction", ex);
}
if (txObject.isNewConnectionHolder()) {
if (logger.isDebugEnabled()) {
logger.debug("Releasing JDBC Connection [" + con + "] after transaction");
}
// 如果当前事务是独立的新创建的事务则在事务完成时释放数据库连接
DataSourceUtils.releaseConnection(con, this.dataSource);
}
txObject.getConnectionHolder().clear();
}
如果在事务执行前有事务挂起,那么当前事务执行结束后需要将挂起事务恢复。
如果有挂起的事务的话,status.getSuspendedResources() != null,也就是说status中会有suspendedResources这个属性,取得status中的transaction后进入resume方法:
protected final void resume(@Nullable Object transaction, @Nullable SuspendedResourcesHolder resourcesHolder)
throws TransactionException {
if (resourcesHolder != null) {
Object suspendedResources = resourcesHolder.suspendedResources;
// 如果有被挂起的事务才进入
if (suspendedResources != null) {
// 真正去resume恢复的地方
doResume(transaction, suspendedResources);
}
List<TransactionSynchronization> suspendedSynchronizations = resourcesHolder.suspendedSynchronizations;
if (suspendedSynchronizations != null) {
// 将上面提到的TransactionSynchronizationManager专门存放线程变量的类中
// 的属性设置成被挂起事务的属性
TransactionSynchronizationManager.setActualTransactionActive(resourcesHolder.wasActive);
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(resourcesHolder.isolationLevel);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(resourcesHolder.readOnly);
TransactionSynchronizationManager.setCurrentTransactionName(resourcesHolder.name);
doResumeSynchronization(suspendedSynchronizations);
}
}
}
我们来看看doResume
@Override
protected void doResume(@Nullable Object transaction, Object suspendedResources) {
TransactionSynchronizationManager.bindResource(obtainDataSource(), suspendedResources);
}
这里恢复只是把suspendedResources重新绑定到线程中。
事务传播属性详解
我们先来看看七种传播属性
Spring事物传播特性表:
| 传播特性名称 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事物,则新建一个事物;如果已经存在一个事物,则加入到这个事物中 |
| PROPAGATION_SUPPORTS | 支持当前事物,如果当前没有事物,则以非事物方式执行 |
| PROPAGATION_MANDATORY | 使用当前事物,如果当前没有事物,则抛出异常 |
| PROPAGATION_REQUIRES_NEW | 新建事物,如果当前已经存在事物,则挂起当前事物 |
| PROPAGATION_NOT_SUPPORTED | 以非事物方式执行,如果当前存在事物,则挂起当前事物 |
| PROPAGATION_NEVER | 以非事物方式执行,如果当前存在事物,则抛出异常 |
| PROPAGATION_NESTED | 如果当前存在事物,则在嵌套事物内执行;如果当前没有事物,则与PROPAGATION_REQUIRED传播特性相同 |
当前不存在事务的情况下
每次创建一个TransactionInfo的时候都会去new一个transaction,然后去线程变量Map中拿holder,当此时线程变量的Map中holder为空时,就视为当前情况下不存在事务,所以此时transaction中holder = null。
1、PROPAGATION_MANDATORY
使用当前事物,如果当前没有事物,则抛出异常
在上一篇博文中我们在getTransaction方法中可以看到如下代码,当前线程不存在事务时,如果传播属性为PROPAGATION_MANDATORY,直接抛出异常,因为PROPAGATION_MANDATORY必须要在事务中运行
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
2、REQUIRED、REQUIRES_NEW、NESTED
我们继续看上一篇博文中的getTransaction方法
else if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
// PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED都需要新建事务
// 因为此时不存在事务,将null挂起
SuspendedResourcesHolder suspendedResources = suspend(null);
if (debugEnabled) {
logger.debug("Creating new transaction with name [" + definition.getName() + "]: " + definition);
}
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// new一个status,存放刚刚创建的transaction,然后将其标记为新事务!
// 这里transaction后面一个参数决定是否是新事务!
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 新开一个连接的地方,非常重要
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException | Error ex) {
resume(null, suspendedResources);
throw ex;
}
}
此时会讲null挂起,此时的status变量为:
DefaultTransactionStatus status = newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
此时的transaction中holder依然为null,标记为新事务,接着就会执行doBegin方法了:
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
Connection con = null;
// 此时会进入这个if语句块,因为此时的holder依然为null
if (!txObject.hasConnectionHolder() ||
txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
// 从dataSource从取得一个新的connection
Connection newCon = obtainDataSource().getConnection();
if (logger.isDebugEnabled()) {
logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
}
// new一个新的holder放入新的连接,设置为新的holder
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
// 略...
prepareTransactionalConnection(con, definition);
// 将holder设置avtive = true
txObject.getConnectionHolder().setTransactionActive(true);
// Bind the connection holder to the thread.
// 绑定到当前线程
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.bindResource(obtainDataSource(), txObject.getConnectionHolder());
}
}
}
所以,一切都是新的,新的事务,新的holder,新的连接,在当前不存在事务的时候一切都是新创建的。
这三种传播特性在当前不存在事务的情况下是没有区别的,此事务都为新创建的连接,在回滚和提交的时候都可以正常回滚或是提交,就像正常的事务操作那样。
3、PROPAGATION_SUPPORTS、PROPAGATION_NOT_SUPPORTED、PROPAGATION_NEVER
我们看看当传播属性为PROPAGATION_SUPPORTS、PROPAGATION_NOT_SUPPORTED、PROPAGATION_NEVER这几种时的代码,getTransaction方法
else {
//其他的传播特性一律返回一个空事务,transaction = null
//当前不存在事务,且传播机制=PROPAGATION_SUPPORTS/PROPAGATION_NOT_SUPPORTED/PROPAGATION_NEVER,这三种情况,创建“空”事务
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(definition, null, true, newSynchronization, debugEnabled, null);
}
我们看到Status中第二个参数传的是null,表示一个空事务,意思是当前线程中并没有Connection,那如何进行数据库的操作呢?上一篇文章中我们有一个扩充的知识点,Mybaits中使用的数据库连接是从通过TransactionSynchronizationManager.getResource(Object key)获取spring增强方法中绑定到线程的connection,如下代码,那当传播属性为PROPAGATION_SUPPORTS、PROPAGATION_NOT_SUPPORTED、PROPAGATION_NEVER这几种时,并没有创建新的Connection,当前线程中也没有绑定Connection,那Mybatis是如何获取Connecion的呢?这里留一个疑问,我们后期看Mybatis的源码的时候来解决这个疑问
@Nullable
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Object value = doGetResource(actualKey);
if (value != null && logger.isTraceEnabled()) {
logger.trace("Retrieved value [" + value + "] for key [" + actualKey + "] bound to thread [" +
Thread.currentThread().getName() + "]");
}
return value;
}
@Nullable
private static Object doGetResource(Object actualKey) {
Map<Object, Object> map = resources.get();
if (map == null) {
return null;
}
Object value = map.get(actualKey);
// Transparently remove ResourceHolder that was marked as void...
if (value instanceof ResourceHolder && ((ResourceHolder) value).isVoid()) {
map.remove(actualKey);
// Remove entire ThreadLocal if empty...
if (map.isEmpty()) {
resources.remove();
}
value = null;
}
return value;
}
此时我们知道Status中的Transaction为null,在目标方法执行完毕后,进行回滚或提交的时候,会判断当前事务是否是新事务,代码如下
@Override
public boolean isNewTransaction() {
return (hasTransaction() && this.newTransaction);
}
此时transacion为null,回滚或提交的时候将什么也不做
当前存在事务情况下
上一篇文章中已经讲过,第一次事务开始时必会新创一个holder然后做绑定操作,此时线程变量是有holder的且avtive为true,如果第二个事务进来,去new一个transaction之后去线程变量中取holder,holder是不为空的且active是为true的,所以会进入handleExistingTransaction方法:
1 private TransactionStatus handleExistingTransaction(
2 TransactionDefinition definition, Object transaction, boolean debugEnabled)
3 throws TransactionException {
4 // 1.NERVER(不支持当前事务;如果当前事务存在,抛出异常)报错
5 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
6 throw new IllegalTransactionStateException(
7 "Existing transaction found for transaction marked with propagation 'never'");
8 }
9 // 2.NOT_SUPPORTED(不支持当前事务,现有同步将被挂起)挂起当前事务,返回一个空事务
10 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
11 if (debugEnabled) {
12 logger.debug("Suspending current transaction");
13 }
14 // 这里会将原来的事务挂起,并返回被挂起的对象
15 Object suspendedResources = suspend(transaction);
16 boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
17 // 这里可以看到,第二个参数transaction传了一个空事务,第三个参数false为旧标记
18 // 最后一个参数就是将前面挂起的对象封装进新的Status中,当前事务执行完后,就恢复suspendedResources
19 return prepareTransactionStatus(definition, null, false, newSynchronization, debugEnabled, suspendedResources);
20 }
21 // 3.REQUIRES_NEW挂起当前事务,创建新事务
22 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
23 if (debugEnabled) {
24 logger.debug("Suspending current transaction, creating new transaction with name [" +
25 definition.getName() + "]");
26 }
27 // 将原事务挂起,此时新建事务,不与原事务有关系
28 // 会将transaction中的holder设置为null,然后解绑!
29 SuspendedResourcesHolder suspendedResources = suspend(transaction);
30 try {
31 boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
32 // new一个status出来,传入transaction,并且为新事务标记,然后传入挂起事务
33 DefaultTransactionStatus status = newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
34 // 这里也做了一次doBegin,此时的transaction中holer是为空的,因为之前的事务被挂起了
35 // 所以这里会取一次新的连接,并且绑定!
36 doBegin(transaction, definition);
37 prepareSynchronization(status, definition);
38 return status;
39 }
40 catch (RuntimeException beginEx) {
41 resumeAfterBeginException(transaction, suspendedResources, beginEx);
42 throw beginEx;
43 }
44 catch (Error beginErr) {
45 resumeAfterBeginException(transaction, suspendedResources, beginErr);
46 throw beginErr;
47 }
48 }
49 // 如果此时的传播特性是NESTED,不会挂起事务
50 if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
51 if (!isNestedTransactionAllowed()) {
52 throw new NestedTransactionNotSupportedException(
53 "Transaction manager does not allow nested transactions by default - " +
54 "specify 'nestedTransactionAllowed' property with value 'true'");
55 }
56 if (debugEnabled) {
57 logger.debug("Creating nested transaction with name [" + definition.getName() + "]");
58 }
59 // 这里如果是JTA事务管理器,就不可以用savePoint了,将不会进入此方法
60 if (useSavepointForNestedTransaction()) {
61 // 这里不会挂起事务,说明NESTED的特性是原事务的子事务而已
62 // new一个status,传入transaction,传入旧事务标记,传入挂起对象=null
63 DefaultTransactionStatus status =prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
64 // 这里是NESTED特性特殊的地方,在先前存在事务的情况下会建立一个savePoint
65 status.createAndHoldSavepoint();
66 return status;
67 }
68 else {
69 // JTA事务走这个分支,创建新事务
70 boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
71 DefaultTransactionStatus status = newTransactionStatus(
72 definition, transaction, true, newSynchronization, debugEnabled, null);
73 doBegin(transaction, definition);
74 prepareSynchronization(status, definition);
75 return status;
76 }
77 }
78
79 // 到这里PROPAGATION_SUPPORTS 或 PROPAGATION_REQUIRED或PROPAGATION_MANDATORY,存在事务加入事务即可,标记为旧事务,空挂起
80 boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
81 return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
82 }
1、NERVER
不支持当前事务;如果当前事务存在,抛出异常
// 1.NERVER(不支持当前事务;如果当前事务存在,抛出异常)报错
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
throw new IllegalTransactionStateException(
"Existing transaction found for transaction marked with propagation 'never'");
}
我们看到如果当前线程中存在事务,传播属性为PROPAGATION_NEVER,会直接抛出异常
2、NOT_SUPPORTED
以非事物方式执行,如果当前存在事物,则挂起当前事物
我们看上面代码第9行,如果传播属性为PROPAGATION_NOT_SUPPORTED,会先将原来的transaction挂起,此时status为:
return prepareTransactionStatus(definition, null, false, newSynchronization, debugEnabled, suspendedResources);
transaction为空,旧事务,挂起的对象存入status中。
此时与外层事务隔离了,在这种传播特性下,是不进行事务的,当提交时,因为是旧事务,所以不会commit,失败时也不会回滚rollback
3、REQUIRES_NEW
此时会先挂起,然后去执行doBegin方法,此时会创建一个新连接,新holder,新holder有什么用呢?
如果是新holder,会在doBegin中做绑定操作,将新holder绑定到当前线程,其次,在提交或是回滚时finally语句块始终会执行清理方法时判断新holder会进行解绑操作。
@Override
protected void doCleanupAfterCompletion(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// Remove the connection holder from the thread, if exposed.
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.unbindResource(obtainDataSource());
}
}
符合传播特性,所以这里REQUIRES_NEW这个传播特性是与原事务相隔的,用的连接都是新new出来的。
此时返回的status是这样的:
DefaultTransactionStatus status = newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
其中transaction中holder为新holder,连接都是新的。标记为新事务,在开头的回顾中提到,如果是新事务,提交时才能成功提交。并且在最后一个参数放入挂起的对象,之后将会恢复它。
REQUIRES_NEW小结
会于前一个事务隔离,自己新开一个事务,与上一个事务无关,如果报错,上一个事务catch住异常,上一个事务是不会回滚的,这里要注意(在invokeWithinTransaction方法中的catch代码块中,处理完异常后,还通过 throw ex;将异常抛给了上层,所以上层要catch住子事务的异常,子事务回滚后,上层事务也会回滚),而只要自己提交了之后,就算上一个事务后面的逻辑报错,自己是不会回滚的(因为被标记为新事务,所以在提交阶段已经提交了)。
4、NESTED
不挂起事务,并且返回的status对象如下:
DefaultTransactionStatus status =prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
status.createAndHoldSavepoint();
不同于其他的就是此传播特性会创建savePoint,有什么用呢?前面说到,如果是旧事务的话回滚是不会执行的,但先看看它的status,虽然标记为旧事务,但它还有savePoint,如果有savePoint,会回滚到保存点去,提交的时候,会释放保存点,但是不提交!切记,这里就是NESTED与REQUIRES_NEW不同点之一了,NESTED只会在外层事务成功时才进行提交,实际提交点只是去释放保存点,外层事务失败,NESTED也将回滚,但如果是REQUIRES_NEW的话,不管外层事务是否成功,它都会提交不回滚。这就是savePoint的作用。
由于不挂起事务,可以看出来,此时transaction中的holder用的还是旧的,连接也是上一个事务的连接,可以看出来,这个传播特性会将原事务和自己当成一个事务来做。
NESTED 小结
与前一个事务不隔离,没有新开事务,用的也是老transaction,老的holder,同样也是老的connection,没有挂起的事务。关键点在这个传播特性在存在事务情况下会创建savePoint,但不存在事务情况下是不会创建savePoint的。在提交时不真正提交,只是释放了保存点而已,在回滚时会回滚到保存点位置,如果上层事务catch住异常的话,是不会影响上层事务的提交的,外层事务提交时,会统一提交,外层事务回滚的话,会全部回滚
5、REQUIRED 、PROPAGATION_REQUIRED或PROPAGATION_MANDATORY
存在事务加入事务即可,标记为旧事务,空挂起
status为:
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
使用旧事务,标记为旧事务,挂起对象为空。
与前一个事务不隔离,没有新开事务,用的也是老transaction,老的connection,但此时被标记成旧事务,所以,在提交阶段不会真正提交的,在外层事务提交阶段,才会把事务提交。
如果此时这里出现了异常,内层事务执行回滚时,旧事务是不会去回滚的,而是进行回滚标记,我们看看文章开头处回滚的处理函数processRollback中第39行,当前事务信息中表明是存在事务的,但是既没有保存点,又不是新事务,回滚的时候只做回滚标识,等到提交的时候再判断是否有回滚标识,commit的时候,如果有回滚标识,就进行回滚
@Override
protected void doSetRollbackOnly(DefaultTransactionStatus status) {
// 将status中的transaction取出
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
if (status.isDebug()) {
logger.debug("Setting JDBC transaction [" + txObject.getConnectionHolder().getConnection() +
"] rollback-only");
}
// transaction执行标记回滚
txObject.setRollbackOnly();
}
public void setRollbackOnly() {
// 这里将transaction里面的connHolder标记回滚
getConnectionHolder().setRollbackOnly();
}
public void setRollbackOnly() {
// 将holder中的这个属性设置成true
this.rollbackOnly = true;
}
我们知道,在内层事务中transaction对象中的holder对象其实就是外层事务transaction里的holder,holder是一个对象,指向同一个地址,在这里设置holder标记,外层事务transaction中的holder也是会被设置到的,在外层事务提交的时候有这样一段代码:
@Override
public final void commit(TransactionStatus status) throws TransactionException {
// 略...
// !shouldCommitOnGlobalRollbackOnly()只有JTA与JPA事务管理器才会返回false
// defStatus.isGlobalRollbackOnly()这里判断status是否被标记了
if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
if (defStatus.isDebug()) {
logger.debug("Global transaction is marked as rollback-only but transactional code requested commit");
}
// 如果内层事务抛异常,外层事务是会走到这个方法中的,而不是去提交
processRollback(defStatus, true);
return;
}
// 略...
}
在外层事务提交的时候是会去验证transaction中的holder里是否被标记rollback了,内层事务回滚,将会标记holder,而holder是线程变量,在此传播特性中holder是同一个对象,外层事务将无法正常提交而进入processRollback方法进行回滚,并抛出异常:
private void processRollback(DefaultTransactionStatus status, boolean unexpected) {
try {
// 此时这个值为true
boolean unexpectedRollback = unexpected;
try {
triggerBeforeCompletion(status);
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Rolling back transaction to savepoint");
}
status.rollbackToHeldSavepoint();
}
// 新事务,将进行回滚操作
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction rollback");
}
// 回滚!
doRollback(status);
}
// 略...
// Raise UnexpectedRollbackException if we had a global rollback-only marker
// 抛出一个异常
if (unexpectedRollback) {
// 这个就是上文说到的抛出的异常类型
throw new UnexpectedRollbackException(
"Transaction rolled back because it has been marked as rollback-only");
}
}
finally {
cleanupAfterCompletion(status);
}
}
@Configuration配置类及@Bean的原理
@Configuration注解提供了全新的bean创建方式。最初spring通过xml配置文件初始化bean并完成依赖注入工作。从spring3.0开始,在spring framework模块中提供了这个注解,搭配@Bean等注解,可以完全不依赖xml配置,在运行时完成bean的创建和初始化工作。例如:
public interface IBean {
}
public class AppBean implements IBean{
}
//@Configuration申明了AppConfig是一个配置类
@Configuration
public class AppConfig {
//@Bean注解申明了一个bean,bean名称默认为方法名appBean
@Bean
IBean appBean(){
return new AppBean();
}
}
默认情况下bean的名称和方法名称相同,你也可以使用name属性来指定,如@Bean(name = “myBean”)
@Configuration注解使用
我们先来看看@Configuration 这个注解的定义
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component //@Component元注解
public @interface Configuration {
String value() default "";
}
我们看到源码里面,@Configuration 标记了@Component元注解,因此可以被@ComponentScan扫描并处理,在Spring容器初始化时Configuration类 会被注册到Bean容器中,最后还会实例化。
使用@Autowired/@Inject
因为@Configuration本身也是一个@Component,因此配置类本身也会被注册到应用上下文,并且也可以使用IOC的@Autowired/@Inject等注解来注入所需bean。我们来修改配置类如下:
@Configuration
public class AppConfig {
@Autowired
public Environment env;
@Bean
IBean appBean(){
return new AppBean();
}
}
使用@CompomentScan
配置类也可以自己添加注解@CompomentScan,来显式扫描需使用组件。
@Configuration 使用@Component 进行原注解,因此@Configuration 类也可以被组件扫描到(特别是使用XML元素)。
@Configuration
@ComponentScan("abc.xxx")
public class AppConfig {
@Bean
IBean appBean(){
return new AppBean();
}
}
在这里认识几个注解: @Controller, @Service, @Repository, @Component
- @Controller: 表明一个注解的类是一个”Controller”,也就是控制器,可以把它理解为MVC 模式的Controller 这个角色。这个注解是一个特殊的@Component,允许实现类通过类路径的扫描扫描到。它通常与@RequestMapping 注解一起使用。
- @Service: 表明这个带注解的类是一个”Service”,也就是服务层,可以把它理解为MVC 模式中的Service层这个角色,这个注解也是一个特殊的@Component,允许实现类通过类路径的扫描扫描到
- @Repository: 表明这个注解的类是一个”Repository”,团队实现了JavaEE 模式中像是作为”Data Access Object” 可能作为DAO来使用,当与 PersistenceExceptionTranslationPostProcessor 结合使用时,这样注释的类有资格获得Spring转换的目的。这个注解也是@Component 的一个特殊实现,允许实现类能够被自动扫描到
- @Component: 表明这个注释的类是一个组件,当使用基于注释的配置和类路径扫描时,这些类被视为自动检测的候选者。
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Controller {
@AliasFor(annotation = Component.class)
String value() default "";
}
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Service {
@AliasFor(annotation = Component.class)
String value() default "";
}
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Repository {
@AliasFor(annotation = Component.class)
String value() default "";
}
我们可以看到@Controller, @Service, @Repository这三个注解上都有@Component这个注解
也就是说,上面四个注解标记的类都能够通过@ComponentScan 扫描到,上面四个注解最大的区别就是使用的场景和语义不一样,比如你定义一个Service类想要被Spring进行管理,你应该把它定义为@Service 而不是@Controller因为我们从语义上讲,@Service更像是一个服务的类,而不是一个控制器的类,@Component通常被称作组件,它可以标注任何你没有严格予以说明的类,比如说是一个配置类,它不属于MVC模式的任何一层,这个时候你更习惯于把它定义为 @Component。@Controller,@Service,@Repository 的注解上都有@Component,所以这三个注解都可以用@Component进行替换。
同@Import注解组合使用
新建一个配置类,例如数据库配置类:
@Configuration
public class DatabaseConfig {
@Bean
public DataSource dataSource(){
return new DataSource(){
...
};
}
}
然后在AppConfig中用@Import来导入配置类
@Configuration
@Import(DatabaseConfig.class)
public class AppConfig {
@Autowired
public DataSource dataSource; //注入的bean在DatabaseConfig.class中定义
@Bean
IBean appBean(){
return new AppBean();
}
}
最后执行:
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
DatabaseConfig dataSourceConfig = context.getBean(DatabaseConfig.class);
可以看到只注册了AppConfig.class,容器自动会把@Import指向的配置类初始化。
同@Profile注解组合使用
在配置类中可以申明@Profile注解,仅当满足profile条件时,才会处理配置类,也可以将@Profile注解加载配置类中的每一个@Bean来实现更细粒度的条件控制。
@Configuration
@Profile("develop")
public class DatabaseConfig {
@Bean
public DataSource dataSource(){
return new DataSource(){...};
}
}
嵌套使用@Configuration
在配置类中可以创建静态内部类,并添加@Configuration注解,这样上下文只需要注册最外面的配置类,内部的配置类会自动被加载。这样做省略了@Import,因为本身就在配置类内部,无需再特别指定了。
@Configuration
public class AppConfig {
@Autowired
public DataSource dataSource; //注入的bean在内部定义
@Configuration
public static class DatabaseConfig{
@Bean
DataSource dataSource(){
return new DataSource() {...};
}
}
@Bean
IBean appBean(){
return new AppBean();
}
}
注意:任何嵌套的@Configuration 都必须是static 的。
@Lazy初始化
默认情况下,配置类中的Bean都随着应用上下文被初始化,可以在配置类中添加@Lazy注解来延迟初始化,当然也可以在每个@Bean注解上添加,来实现更细粒度的控制。
@Configuration
@Lazy//延时加载
public class AppConfig {
@Bean
IBean appBean(){
return new AppBean();
}
}
配置类约束
- 配置类必须为显式申明的类,而不能通过工厂类方法返回实例。允许运行时类增强。
- 配置类不允许标记final。
- 配置类必须全局可见(不允许定义在方法本地内部类中)
- 嵌套配置类必须申明为static 内部类
- @Bean方法不可以再创建新的配置类(所有实例都当做bean处理,不解析相关配置注解)
@Configuration源码
ApplicationContext的refresh方法
在ApplicationContext容器refresh过程中写过,Spring容器启动时,即ApplicationContext接口实现类的对象实例执行refresh方法时,在Bean初始化完成之前,有一个扩展点,用来操作BeanFactory,来扩展对应的功能,比喻往BeanFactory中注册BeanDefintion,我们回顾一下ApplicationContext的refresh函数:
1 public void refresh() throws BeansException, IllegalStateException {
2 synchronized (this.startupShutdownMonitor) {
3 //准备刷新的上下文 环境
4 prepareRefresh();
5 //初始化BeanFactory,并进行XML文件读取
6 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
7 //对beanFactory进行各种功能填充
8 prepareBeanFactory(beanFactory);
9 try {
10 postProcessBeanFactory(beanFactory);
11 //激活各种beanFactory处理器
12 invokeBeanFactoryPostProcessors(beanFactory);
13 //注册拦截Bean创建的Bean处理器,这里只是注册,真正的调用实在getBean时候
14 registerBeanPostProcessors(beanFactory);
15 //为上下文初始化Message源,即不同语言的消息体,国际化处理
16 initMessageSource();
17 //初始化应用消息广播器,并放入“applicationEventMulticaster”bean中
18 initApplicationEventMulticaster();
19 //留给子类来初始化其它的Bean
20 onRefresh();
21 //在所有注册的bean中查找Listener bean,注册到消息广播器中
22 registerListeners();
23 //初始化剩下的单实例(非惰性的)
24 finishBeanFactoryInitialization(beanFactory);
25 //完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程,同时发出ContextRefreshEvent通知别人
26 finishRefresh();
27 }
28 catch (BeansException ex) {
29 if (logger.isWarnEnabled()) {
30 logger.warn("Exception encountered during context initialization - " +
31 "cancelling refresh attempt: " + ex);
32 }
33 destroyBeans();
34 cancelRefresh(ex);
35 throw ex;
36 }
37 finally {
38 resetCommonCaches();
39 }
40 }
41 }
看到第12行,在初始化BeanFactory后,会激活各种beanFactory处理器,我们来看看invokeBeanFactoryPostProcessors方法
1 public static void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
2
3 // Invoke BeanDefinitionRegistryPostProcessors first, if any.
4 // 1、首先调用BeanDefinitionRegistryPostProcessors
5 Set<String> processedBeans = new HashSet<>();
6
7 // beanFactory是BeanDefinitionRegistry类型
8 if (beanFactory instanceof BeanDefinitionRegistry) {
9 BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
10 // 定义BeanFactoryPostProcessor
11 List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
12 // 定义BeanDefinitionRegistryPostProcessor集合
13 List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
14
15 // 循环手动注册的beanFactoryPostProcessors
16 for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
17 // 如果是BeanDefinitionRegistryPostProcessor的实例话,则调用其postProcessBeanDefinitionRegistry方法,对bean进行注册操作
18 if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
19 // 如果是BeanDefinitionRegistryPostProcessor类型,则直接调用其postProcessBeanDefinitionRegistry
20 BeanDefinitionRegistryPostProcessor registryProcessor = (BeanDefinitionRegistryPostProcessor) postProcessor;
21 registryProcessor.postProcessBeanDefinitionRegistry(registry);
22 registryProcessors.add(registryProcessor);
23 }
24 // 否则则将其当做普通的BeanFactoryPostProcessor处理,直接加入regularPostProcessors集合,以备后续处理
25 else {
26 regularPostProcessors.add(postProcessor);
27 }
28 }
29 //略....
30 }
31
32 // 2、如果不是BeanDefinitionRegistry的实例,那么直接调用其回调函数即可-->postProcessBeanFactory
33 else {
34 // Invoke factory processors registered with the context instance.
35 invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
36 }
37 //略....
38 }
我们看看第21行,看看其实现类,如下截图,发现其中有一个ConfigurationClassPostProcessor,这个类就是本章的重点
ConfigurationClassPostProcessor这个BeanFactoryPostProcessor,来开启整个@Configuration注解的系列类的加载的,即开启基于@Configuration的类配置代替beans标签的容器配置的相关bean的加载。
ConfigurationClassPostProcessor
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
//生成唯一标识,用于重复处理验证
int registryId = System.identityHashCode(registry);
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);
}
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + registry);
}
this.registriesPostProcessed.add(registryId);
//解析Java类配置bean
processConfigBeanDefinitions(registry);
}
processConfigBeanDefinitions(registry)处理逻辑:
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
//所有已经注册的bean
String[] candidateNames = registry.getBeanDefinitionNames();
//遍历bean定义信息
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) ||
ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
//1.如果当前的bean是Javabean配置类(含有@Configuration注解的类),则加入到集合configCandidates中,
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
// 没有@Configuration注解的类,直接退出
if (configCandidates.isEmpty()) {
return;
}
// 多个Java配置类,按@Ordered注解排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
//初始化一个ConfigurationClassParser解析器,可以解析@Congiguration配置类
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
//2.解析Java配置类
parser.parse(candidates);
//主要校验配置类不能使用final修饰符(CGLIB代理是生成一个子类,因此原先的类不能使用final修饰)
parser.validate();
//排除已处理过的配置类
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
//3.加载bean定义信息,主要实现将@bean @Configuration @Import @ImportResource @ImportRegistrar注册为bean
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
//清空已处理的配置类
candidates.clear();
//再次获取容器中bean定义数量 如果大于 之前获取的bean定义数量,则说明有新的bean注册到容器中,需要再次解析
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
//新注册的bean如果也是@Configuration配置类,则添加到数据,等待解析
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}
processConfigBeanDefinitions整个方法可以大体划分为三个阶段:
- 从容器中获取和Configuration有关系的BeanDefinition
- 以该BeanDefinition为起点,进行解析操作,得到解析结果集
- 将解析到的结果集加载到容器中,即构造成一个BeanDefinition放到容器中待初始化
1、判断类是否与@Configuration有关
在上面第1步中,有@Configuration注解的会加入到集合当中,这个判断是在ConfigurationClassUtils#checkConfigurationClassCandidate当中实现
public static boolean checkConfigurationClassCandidate(BeanDefinition beanDef, MetadataReaderFactory metadataReaderFactory) {
String className = beanDef.getBeanClassName();
if (className == null || beanDef.getFactoryMethodName() != null) {
return false;
}
//获取注解元数据信息
AnnotationMetadata metadata;
if (beanDef instanceof AnnotatedBeanDefinition &&
className.equals(((AnnotatedBeanDefinition) beanDef).getMetadata().getClassName())) {
metadata = ((AnnotatedBeanDefinition) beanDef).getMetadata();
}
else if (beanDef instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) beanDef).hasBeanClass()) {
Class<?> beanClass = ((AbstractBeanDefinition) beanDef).getBeanClass();
metadata = new StandardAnnotationMetadata(beanClass, true);
}
else {
try {
MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);
metadata = metadataReader.getAnnotationMetadata();
}
catch (IOException ex) {
return false;
}
}
// 查找当前注解是否是与@Configuration相关
// 该方法还会判断该注解上的注解是否有@Configuration,一直往上寻找
// 因为有的注解为复合注解
if (isFullConfigurationCandidate(metadata)) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);
}
// 查找当前注解上是否有ComponentScan、Component、Import、ImportResource注解
//如果没有则查找Bean注解,同上,一直往上查找
else if (isLiteConfigurationCandidate(metadata)) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);
}
else {
return false;
}
return true;
}
我们看看isFullConfigurationCandidate和isLiteConfigurationCandidate
public static boolean isFullConfigurationCandidate(AnnotationMetadata metadata) {
return metadata.isAnnotated(Configuration.class.getName());
}
public static boolean isLiteConfigurationCandidate(AnnotationMetadata metadata) {
// Do not consider an interface or an annotation...
if (metadata.isInterface()) {
return false;
}
// Any of the typical annotations found?
for (String indicator : candidateIndicators) {
if (metadata.isAnnotated(indicator)) {
return true;
}
}
// Finally, let's look for @Bean methods...
try {
return metadata.hasAnnotatedMethods(Bean.class.getName());
}
catch (Throwable ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to introspect @Bean methods on class [" + metadata.getClassName() + "]: " + ex);
}
return false;
}
}
private static final Set<String> candidateIndicators = new HashSet<>(8);
static {
candidateIndicators.add(Component.class.getName());
candidateIndicators.add(ComponentScan.class.getName());
candidateIndicators.add(Import.class.getName());
candidateIndicators.add(ImportResource.class.getName());
}
2、解析Java配置类parser.parse(candidates)
parser.parse(candidates)方法最终调用processConfigurationClass方法来处理@Configuration配置类,ConfigurationClassParser. processConfigurationClass()方法实现代码如下:
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
//判断是否需要解析
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
//判断同一个配置类是否重复加载过,如果重复加载过,则合并,否则从集合中移除旧的配置类,后续逻辑将处理新的配置类
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass);
do {
//【真正解析配置类】
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
//再次添加到到集合中
this.configurationClasses.put(configClass, configClass);
}
doProcessConfigurationClass方法主要实现从配置类中解析所有bean,包括处理内部类,父类以及各种注解
ConfigurationClassParser. doProcessConfigurationClass()解析配置类逻辑如下:
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
//递归处理任何成员(嵌套)类
processMemberClasses(configClass, sourceClass);
// 处理@PropertySource注解
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.warn("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// 处理@ComponentScan
//获取@ComponentScan注解信息
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// 按@CmponentScan注解扫描bean
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// 遍历扫描出的bean定义是否是配置类bean
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
//若果扫描出的bean定义是配置类(含有@COnfiguration),则继续调用parse方法,内部再次调用doProcessConfigurationClas(),递归解析
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
//处理@Import注解
processImports(configClass, sourceClass, getImports(sourceClass), true);
//处理@ImportResource注解
AnnotationAttributes importResource = AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
//处理@Bean注解
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
//将解析出的所有@Bean注解方法添加到configClass配置类信息中
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
//处理接口中所有添加@Bean注解的方法,内部通过遍历所有接口,解析得到@Bean注解方法,并添加到configClass配置类信息中
processInterfaces(configClass, sourceClass);
// 如果有父类,则返回父类,递归执行doProcessConfigurationClass()解析父类
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
下面看两个很重要的注解@Bean和@ComponentScan的实现过程
-
@ComponentScan注解解析过程
Set<BeanDefinitionHolder> scannedBeanDefinitions = this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
@ComponentScan注解解析,从上面的代码可以看出@ComponentScan注解解析通过调用ComponentScanAnnotationParser的parse方法完成,而parse()方法内部处理了一些scanner属性(过滤器设置)和basePackages包名处理,最终通过调用ClassPathBeanDefinitionScanner.doScan方法实现扫面工作
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
doScan扫描basePackages下所有bean
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
//根据basePackage加载包下所有java文件,并扫描出所有bean组件
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//遍历beandefition
for (BeanDefinition candidate : candidates) {
//解析作用域Scope
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//通用注解解析到candidate结构中,主要是处理Lazy, primary DependsOn, Role ,Description这五个注解
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//检查当前bean是否已经注册,不存在则注册
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册到ioc容器中,主要是一些@Component组件,@Bean注解方法并没有在此处注册,beanname和beandefinition 键值对
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
ClassPathBeanDefinitionScanner.scanCandidateComponents实现bean定义信息扫描
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// @ComponentScan("com.sl.springlearning.extension")包路径处理:packageSearchPath = classpath*:com/sl/springlearning/extension/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
//获取当前包下所有的class文件
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
//按照scanner过滤器过滤,比如配置类本身将被过滤掉,没有@Component等组件注解的类将过滤掉
//包含@Component注解的组件将创建BeanDefinition
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
} else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
- @Bean注解解析过程
retrieveBeanMethodMetadata方法实现了@Bean方法的解析,但并未将实现bean实例的创建。
private Set<MethodMetadata> retrieveBeanMethodMetadata(SourceClass sourceClass) {
AnnotationMetadata original = sourceClass.getMetadata();
//获取所有@Bean注解的方法
Set<MethodMetadata> beanMethods = original.getAnnotatedMethods(Bean.class.getName());
// 如果配置类中有多个@Bean注解的方法,则排序
if (beanMethods.size() > 1 && original instanceof StandardAnnotationMetadata) {
// Try reading the class file via ASM for deterministic declaration order...
// Unfortunately, the JVM's standard reflection returns methods in arbitrary
// order, even between different runs of the same application on the same JVM.
try {
AnnotationMetadata asm =
this.metadataReaderFactory.getMetadataReader(original.getClassName()).getAnnotationMetadata();
Set<MethodMetadata> asmMethods = asm.getAnnotatedMethods(Bean.class.getName());
if (asmMethods.size() >= beanMethods.size()) {
Set<MethodMetadata> selectedMethods = new LinkedHashSet<>(asmMethods.size());
for (MethodMetadata asmMethod : asmMethods) {
for (MethodMetadata beanMethod : beanMethods) {
if (beanMethod.getMethodName().equals(asmMethod.getMethodName())) {
selectedMethods.add(beanMethod);
break;
}
}
}
if (selectedMethods.size() == beanMethods.size()) {
// All reflection-detected methods found in ASM method set -> proceed
beanMethods = selectedMethods;
}
}
}
catch (IOException ex) {
logger.debug("Failed to read class file via ASM for determining @Bean method order", ex);
// No worries, let's continue with the reflection metadata we started with...
}
}
return beanMethods;
}
3.加载bean定义信息 this.reader.loadBeanDefinitions(configClasses)
回到ConfigurationClassPostProcessor#processConfigBeanDefinitions方法,当调用完parse方法之后,能得到一批ConfigurationClass集合,但是这时候只是获取到,而容器中还没有对应的注册信息,那么接下来就是对这批集合进行注册处理
ConfigurationClassBeanDefinitionReader.loadBeanDefinitions()方法的功能就是将之前解析出的configClasses配置类信息中所有配置相关的信息添加到spring的bean定义,主要是配置类中的@Bean注解方法,配置类@ImportResource和@Import(实现ImportBeanDefinitionRegistrar接口方式)的bean注册
ConfigurationClassBeanDefinitionReader.loadBeanDefinitions()方法 实现逻辑如下:
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
//与@Import注解相关
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
//将@Bean方法注册为bean
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
//将configClass中中ImportResource指定的资源注册为bean
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
//将configClass中ImportedRegistrar注册为bean
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
主要看下loadBeanDefinitionsForBeanMethod方法
private void loadBeanDefinitionsForBeanMethod(BeanMethod beanMethod) {
ConfigurationClass configClass = beanMethod.getConfigurationClass();
MethodMetadata metadata = beanMethod.getMetadata();
//获取方法名
String methodName = metadata.getMethodName();
// Do we need to mark the bean as skipped by its condition?
if (this.conditionEvaluator.shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN)) {
configClass.skippedBeanMethods.add(methodName);
return;
}
if (configClass.skippedBeanMethods.contains(methodName)) {
return;
}
//获取@Bean注解的元数据信息
AnnotationAttributes bean = AnnotationConfigUtils.attributesFor(metadata, Bean.class);
Assert.state(bean != null, "No @Bean annotation attributes");
// Consider name and any aliases
//获取@Bean注解是否有name属性,如@Bean(name = "myBean")
List<String> names = new ArrayList<>(Arrays.asList(bean.getStringArray("name")));
//默认bean的名称和方法名称相同,但是如果设置了name,就取name作为beanName
String beanName = (!names.isEmpty() ? names.remove(0) : methodName);
//创建一个BeanMethod的BeanDefinition
ConfigurationClassBeanDefinition beanDef = new ConfigurationClassBeanDefinition(configClass, metadata);
beanDef.setResource(configClass.getResource());
beanDef.setSource(this.sourceExtractor.extractSource(metadata, configClass.getResource()));
//设置工厂方法
//后期Bean的实例化,getBean的时候,会判断BeanMethod是否存在FactoryMethod,如果存在,就使用反射调用工厂方法,返回工厂方法中的对象
if (metadata.isStatic()) {
// static @Bean method
beanDef.setBeanClassName(configClass.getMetadata().getClassName());
beanDef.setFactoryMethodName(methodName);
}
else {
// instance @Bean method
beanDef.setFactoryBeanName(configClass.getBeanName());
beanDef.setUniqueFactoryMethodName(methodName);
}
//....
this.registry.registerBeanDefinition(beanName, beanDefToRegister);
}
上面只列出了核心代码,主要是构造了BeanDefinition,然后注册进容器,而BeanDefinition的一些属性则是由注解中获取,这部分代码省略。
另外,可以看到@Bean的方式构造的BeanDefinition的时候,与普通的不同,这种方式是会设置工厂方法去初始化,也就是说,AppConfig 类下的appBean方法被Spring当成一个工厂方法,也就是说这种方式与下列的初始化方式原理类似:
<bean id="appConfig" class="com.example.springboot.springbootdemo.bean.AppConfig"/>
<bean id="appBean" factory-bean="appConfig" factory-method="appBean"></bean>
总结
处理逻辑理了一遍后,看一下ConfigurationClassPostProcessor处理器解析@configuration配置类主要过程:
-
Spring容器初始化时注册默认后置处理器ConfigurationClassPostProcessor
2. Spring容器初始化执行refresh()方法中调用ConfigurationClassPostProcessor 3. ConfigurationClassPostProcessor处理器借助ConfigurationClassParser完成配置类解析 4. ConfigurationClassParser配置内解析过程中完成嵌套的MemberClass、@PropertySource注解、@ComponentScan注解(扫描package下的所有Class并进行迭代解析,主要是@Component组件解析及注册)、@ImportResource、@Bean等处理 5. 完成@Bean注册, @ImportResource指定bean的注册以及@Import(实现ImportBeanDefinitionRegistrar接口方式)的bean注册
6.有@Bean注解的方法在解析的时候作为ConfigurationClass的一个属性,最后还是会转换成BeanDefinition进行处理, 而实例化的时候会作为一个工厂方法进行Bean的创建
面试题
核心容器的两个接口引发出来的问题
- ApplicationContext:它在创建核心容器时,创建对象采取的策略是采用立即加载的方式,也就是说,只要一读取完配置文件就马上创建配置文件中配置的对象
- 单例对象适用
- 开发中常采用此接口
- BeanFactory: 它在构建核心容器时,创建对象的策略是采用延迟加载的方式,什么时候获取 id 对象了,什么时候就创建对象。
- 多例对象适用
ApplicationContext的三个常用实现类
ClassPathXmlApplicationContext它可以加载路径下的配置文件,要求配置文件必须在路径下,否则加载不了(配置文件所在的目录必须要在IDEA中设置为任何类型的目录但是一般设置为Resource类型的目录)
ApplicationContext ac = new ClassPathXmlApplicationContext("beans.xml");
FileSyetemXmlApplicationContext它可以加载磁盘下任意路径下的配置文件(必须有访问权限)
加载方式如下:
ApplicationContext ac = new FileSystemXmlApplicationContex("C:\\user\\...")
AnnotationConfigApplicationContext它是用于读取注解创建容器的
Spring的单例有线程安全问题吗
大部分时候我们并没有在系统中使用多线程,所以很少有人会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
常见的有两种解决办法:
- 在Bean对象中尽量避免定义可变的成员变量(不太现实)。
- 在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在 ThreadLocal 中(推荐的一种方式)。
什么是三级缓存
- 第一级缓存:单例缓存池singletonObjects。
- 第二级缓存:早期提前暴露的对象缓存earlySingletonObjects。(属性还没有值对象也没有被初始化)
- 第三级缓存:singletonFactories单例对象工厂缓存。
创建Bean的整个过程
- 首先finishBeanFactoryInitialization->preInstantiateSingletons->getBean->doGetBean;
- 在doGetBean中,transformedBeanName:主要负责判断一下有木有别名;getSingleton:从一级缓存singletonObjects拿bean,在getSingleton方法中,有一个判断条件就是isSingletonCurrentlyInCreation,判断为false,因为他是第一次进来,并且还没有正在创建该bean;dependsOn:依赖,暂时先不说他。
- 再来一次getSingleton:再一次的从singketonObjects缓存拿,依然没有的。接着有个重点beforeSingletonCreation:它把bean添加到临时的singletonsCurrentlyInCreation,这就意味着,下次再碰见它,那可就是true了。接着singletonFactory.getObject(),这里getObject调用的是传递的接口createBean方法。
- 在createBean方法中:有个doCreateBean->createBeanInstance方法:它就是直接实例化,实际上构造器有反应了(区分JVM创建对象和Spring创建对象),但是没有赋值(初始化);earlySingletonExposure:提前暴漏该bean。但要知道三个变量,为什么他是true:isSingleton(),是否单例,那肯定是哦;(这里解释了这里是单例才能提前曝漏,意味着才能存三级缓存)allowCircularReferences,默认变量为true,写死了;isSingletonCurrentlyInCreation,这里可就为true了,因为步骤3,已经将它设置为true了。那么会进来这个方法:addSingletonFactory
- addSingletonFactory在这个方法中:将该bean放入到三级缓存singletonFactories中。(解决循环依赖)
- 接下来,就是它了,populateBean:实际上就是属性赋值。(如果这里要有A依赖B,又发现三级缓存中没有B,那么它就会再次执行一次(递归开始)getBean->doGetBean->createBeanInstance(把B给实例化一下),同样的道理,这里会将B也会放入三级缓存中,B开始populateBean,那么它发现B依赖A,此时三级缓存中有A(精髓,牛逼),然后把A放到二级缓存中,同时从三级缓存中移除,接着得到A之后直接赋值,最后完成了初始化,然后来到addSingleton,将B仍到了一级缓存,同时将B从三级缓存仍出去)返回B,递归结束,得到B之后将B的赋值给A了。
- 最后将二级缓存的A删除,仍到一级缓存中。
IOC初始化流程
- Resource资源定位:这个Resouce指的是BeanDefinition的资源定位。这个过程就是容器找数据的过程,就像水桶装水需要先找到水一样。
- BeanDefinition的载入和解析:这个载入过程是把用户定义好的Bean表示成Ioc容器内部的数据结构,而这个容器内部的数据结构就是BeanDefition。
- BeanDefinition注册
- prepareRefresh():预备一下, 标记启动时间,上下文环境,我要的材料(beanDefinition)准备好了嘛?
- obtainFreshBeanFactory():
- 如果已经有了BeanFactory就销毁它里面的单例Bean并关闭这个BeanFactory。
- 创建一个新的BeanFactory。
- 对这个BeanFactory进行定制(customize),如allowBeanDefinitionOverriding等参数
- 转载BeanDefinitions(读取配置文件,将xml转换成对应得BeanDefinition)
- 检查是否同时启动了两个BeanFactory。
- prepareBeanFactory(beanFactory):设置beanFactory的类加载器,材料(BeanDefinition)解析器等
- postProcessBeanFactory(beanFactory):
- 设置beanFactory的后置处理器
- 具体的子类可以在这步的时候添加一些特殊的 BeanFactoryPostProcessor 的实现类或做点什么事
- invokeBeanFactoryPostProcessors(beanFactory):
- 调用beanFactory的后置处理器(BeanDefinitionRegisterPostProcessor和BeanFactoryPostProcessor)
- 调用 BeanFactoryPostProcessor 各个实现类的 postProcessBeanFactory(factory) 方法
- registerBeanPostProcessors(beanFactory):
- 注册 BeanPostProcessor 的实现类(bean的后置处理器)
- 此接口两个方法: postProcessBeforeInitialization 和 postProcessAfterInitialization 两个方法分别在 Bean 初始化之前和初始化之后得到执行。注意,到这里 Bean 还没初始化
- initMessageSource():对上下文中的消息源进行初始化
- initApplicationEventMulticaster():初始化上下文的事件广播器
- onRefresh():- 模版方法,具体的子类可以在这里初始化一些特殊的 Bean(在初始化 singleton beans 之前)
- registerListeners():注册事件监听器
- finishBeanFactoryInitialization(beanFactory):初始化所有的 singleton beans
- finishRefresh():最后,广播事件,ApplicationContext 初始化完成
AOP初始化流程
- 第一句,注册一个AnnotationAwareAspectJAutoProxyCreator(称它为自动代理器),这个Creator是AOP的操作核心,也是扫描Bean,代理Bean的操作所在。
- 第二句,解析配置元素,决定代理的模式。其中有JDK动态代理,还有CGLIB代理。
- 第三句,作为系统组件,把Creator这个Bean,放到Spring容器中。让Spring实例化,启动这个Creator。
总结:
- Spring加载自动代理器AnnotationAwareAspectJAutoProxyCreator,当作一个系统组件。
- 当一个bean加载到Spring中时,会触发自动代理器中的bean后置处理,然后会先扫描bean中所有的Advisor
- 然后用这些Adviosr和其他参数构建ProxyFactory
- ProxyFactory会根据配置和目标对象的类型寻找代理的方式(JDK动态代理或CGLIG代理)
- 然后代理出来的对象放回context中,完成Spring AOP代理
@Transactional(rollbackFor = Exception.class)注解了解吗
@Transactional注解只能应用到public修饰符上,其它修饰符不起作用,但不报错。
默认情况下此注解会对unchecked异常进行回滚,对checked异常不回滚。
checked异常:表示无效,不是程序中可以预测的。比如无效的用户输入,文件不存在,网络或者数据库链接错误。这些都是外在的原因,都不是程序内部可以控制的。unchecked异常:表示错误,程序的逻辑错误。是RuntimeException的子类,比如IllegalArgumentException, NullPointerException和IllegalStateException。
不回滚解决方案:
检查方法是不是public
检查异常是不是unchecked异常
如果是checked异常也想回滚的话,注解上写明异常类型即可@Transactional(rollbackFor=Exception.class)
事务失效的原因
数据库引擎不支持事务
没有被 Spring 管理
方法不是 public 的
自身调用问题
数据源没有配置事务管理器
不支持事务(传播机制)
异常被吃了(捕获异常)
异常类型错误(checked异常失效)
Spring的的事务传播机制
- required(默认):支持使用当前事务,如果当前事务不存在,创建一个新事务。
- requires_new:创建一个新事务,如果当前事务存在,把当前事务挂起。
- supports:支持使用当前事务,如果当前事务不存在,则不使用事务。
- not_supported:无事务执行,如果当前事务存在,把当前事务挂起。
- mandatory:强制,支持使用当前事务,如果当前事务不存在,则抛出Exception。
- never:无事务执行,如果当前有事务则抛出Exception。
- nested:嵌套事务,如果当前事务存在,那么在嵌套的事务中执行。如果当前事务不存在,则表现跟REQUIRED一样。
事务源码
- 开启@EnableTransactionManagement
- 利用TransactionManagementConfigurationSelector给容器中会导入组件
- AutoProxyRegistrar
- 给容器中注册一个 InfrastructureAdvisorAutoProxyCreator 组件
- 利用后置处理器机制在对象创建以后,包装对象,返回一个代理对象(增强器),代理对象执行方法利用拦截器链进行调用;
- ProxyTransactionManagementConfiguration(给容器中注册事务增强器)
- 事务增强器要用事务注解的信息,AnnotationTransactionAttributeSource解析事务注解
- 事务拦截器
- AutoProxyRegistrar
bean在多例模式下的生命周期:
- spring容器启动时解析xml发现该bean标签后,只是将该bean进行管理,并不会创建对象。
- 此后每次使用
getBean()获取该bean时,spring都会重新创建该对象返回,每次都是一个新的对象。这个对象spring容器并不会持有 - 什么销毁取决于使用该对象的用户自己什么时候销毁该对象。通过JVM的垃圾回收器进行回收
Spring面试题
@MapperScan和@ComponentScan的区别
首先@MapperScan和@ComponentScan都是扫描包
@ComponentScan是组件扫描注解,用来扫描@Controller @Service @Repository这类,主要就是定义扫描的路径从中找出标志了需要装配的类到Spring容器中
首先了解@Mapper,在接口上添加了@Mapper,在编译之后就会生成相应的接口实现类。 不过需要在每个接口上面进行配置,为了简化开发,就有了 @MapperScan。
@MapperScan 是扫描mapper类的注解,就不用在每个mapper类上加@MapperScan了
注:@Repository为spring包下的,@MapperScan为ibatis包下的,如果使用mybatis,建议使用@Mapper
@MapperScan和@ComponentScan可以同时使用。
如果都是扫描的相同路径时,对于同一个接口,可能就会出现识别错误。
如果在相同路径,可能识别的不是xxImpl,而去mybatis里面通过反射找绑定,这样就会出现BindingException错误
org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)
所以在设计项目结构的时候要把mapper放到一个合适的位置,通过设置MapperScan的路径basePackages 好避免这种冲突
Spring 源码阅读之 Environment
Spring 源码阅读之 Environment 一 Environment 介绍和占位符解析
概念
environment 翻译过来即是“环境”,表示应用程序运行环境。而在 Spring 应用中,环境包含两个方面的内容:profiles 和 properties. 看看 org.springframework.core.env.Environment 接口的部分注释:
/**
* Interface representing the environment in which the current application is running.
* Models two key aspects of the application environment: profiles and
* properties. Methods related to property access are exposed via the
* {@link PropertyResolver} superinterface.
* ... 此处省略N个字...
*/
org.springframework.core.env.Environment 是表示当前应用程序运行环境的接口,为应用程序运行环境的两个关键方面(profiles 和 properties)建模。其中和 property 访问相关的 Methods 在 Environment 父接口 PropertyResolver 中定义。 由上可知 Environment 接口继承自接口 PropertyResolver,PropertyResolver 提供了 propertiy 访问的相关方法,Environment 本身提供了访问 profile 的相关方法。
- profile 是一个命名的,bean定义的逻辑组。bean 只有在给定的 profile 处于活动状态时,才会在容器中注册
- propertiy 即属性,可以简单理解为应用程序过程中一直存在的键值对集合
Environment 体系结构
本文基于 web 环境为例阅读 Environment 相关代码,先对 Environment 有个总体了解,看下 Environment 体系的类图:

image.png
由上图可以看到 Environment 体系涉及到类或者接口还是比较多的,下面对其做简单介绍,可以仔细看看并尝试记住,需要对各个类或者接口有简单映像,不然阅读到后面容易迷糊。
- PropertyResolver:提供 properties 访问功能。
- ConfigurablePropertyResolver:继承自 PropertyResolver,额外提供 properties 类型转换(基于org.springframework.core.convert.ConversionService)功能,本文不做详细介绍。
- Environment:继承自 PropertyResolver,额外提供获取 profiles 的功能。
- ConfigurableEnvironment:继承自 ConfigurablePropertyResolver 和 Environment,提供设置活的 profile 和默认的 profile 的功能。
- ConfigurableWebEnvironment:继承自 ConfigurableEnvironment,并且提供配置 ServletContext 和ServletConfig 的功能。
- AbstractEnvironment:实现了 ConfigurableEnvironment 接口,默认属性和存储容器的定义,并且实现了 ConfigurableEnvironment 种的方法,并且为子类预留可覆盖了扩展方法。
- StandardEnvironment:继承自 AbstractEnvironment,非 Servlet(Web) 环境下的标准 Environment 实现。实现钩子方法,customizePropertySources(..),初始化 systemEnvironment 和 systemProperties。
- StandardServletEnvironment:继承自 StandardEnvironment,Servlet(Web) 环境下的标准实现。实现钩子方法,customizePropertySources(..),初始化 servletContextInitParams、servletConfigInitParams 和 jndiProperties Web 应用环境需要的参数。
接口方法展示
涉及到的接口提供的方法如下图所示

image.png
properties
PropertySource
先看开始正式介绍 properties 之前,先了解一下 PropertySource 抽象类:
public abstract class PropertySource {
protected final String name;
protected final T source;
public boolean containsProperty(String name) {
return (getProperty(name) != null);
}
// 抽象方法,留给字类实现
@Nullable
public abstract Object getProperty(String name);
@Override
public boolean equals(Object other) {
return (this == other || (other instanceof PropertySource &&
ObjectUtils.nullSafeEquals(this.name, ((PropertySource) other).name)));
}
// hashCode方法, 可以看到hash值仅和name有关系,这个 name 有点像 HashMap 里面的 key, 是唯一的
@Override
public int hashCode() {
return ObjectUtils.nullSafeHashCode(this.name);
}
// 略。。。
}
源码很简单,预留了一个 getProperty 抽象方法给子类实现,重点需要关注的是覆写了的 equals 和 hashCode 方法,实际上只和 name 属性相关,这一点很重要,说明一个 PropertySource 实例绑定到一个唯一的 name,这个 name 有点像 HashMap 里面的 key。PropertySource 的最常用子类是 MapPropertySource、PropertiesPropertySource、ResourcePropertySource、StubPropertySource 和 ComparisonPropertySource:

image.png
- MapPropertySource:封装一个 Map 对象为属性源, 继承抽象类 EnumerablePropertySource,增加了一个抽象方法 getPropertyNames()。
- PropertiesPropertySource:继承自 MapPropertySource,封装一个 Properties 对象为属性源。
- ResourcePropertySource:继承自 PropertiesPropertySource,封装一个 EncodedResource 对象为属性源。
- RandomValuePropertySource:封装一个 Random 对象为属性源,位于 spring-boot.jar 中。
- ServletConfigPropertySource:封装一个 ServletConfig 对象为属性源,位于 spring-web.jar 中。
- ServletContextPropertySource:封装一个 ServletContext 对象为属性源,位于 spring-web.jar 中。
- CompositePropertySource: 封装 Set> propertySources 对象作为属性源。
- CommandLinePropertySource:以命令行参数作为属性源
- SimpleCommandLinePropertySource:继承自CommandLinePropertySource。 简单命令行属性源,使用SimpleCommandLineArgsParser解析器对象解析输入的String数组,把返回的CommandLineArgs对象作为属性的来源。
- JOptCommandLinePropertySource:基于JOpt Simple的属性源实现,JOpt Simple是一个解析命令行选项参数的第三方库
- SystemEnvironmentPropertySource:系统环境属性源,继承 MapPropertySource,此属性源在根据name获取对应的value时,与父类实现不太一样。它认为name不区分大小写,且name中包含的’.’点与’_‘下划线是等效的,因此在获取value之前,都会对name进行一次处理。
- StubPropertySource:PropertySource 的一个内部类,source 设置为 new Object(),实际上就是空实现。用于占位。
- ComparisonPropertySource:继承自 StubPropertySource,所有属性访问方法强制抛出异常,作用就是一个不可访问属性的空实现。
Environment 存储容器
Environment 的静态属性和存储容器都是在 AbstractEnvironment 中定义的 。Environment 的静态属性和存储容器实际上,Environment 的存储容器就是 org.springframework.core.env.PropertySource 的子类集合,AbstractEnvironment 中使用的实例是 org.springframework.core.env.MutablePropertySources。 AbstractEnvironment 中的属性定义:
private final MutablePropertySources propertySources = new MutablePropertySources();
再来看看 MutablePropertySources 是个什么东西:
// PropertySources提供处理多个PropertySource的方法
public interface PropertySources extends Iterable> {
boolean contains(String name);
PropertySource get(String name);
}
// MutablePropertySources 实现了PropertySources
public class MutablePropertySources implements PropertySources {
//内部管理一个 CopyOnWriteArrayList propertySourceList 对象,即 PropertySource 列表
private final List> propertySourceList = new CopyOnWriteArrayList>();
// 判断 propertySourceList 是否包含 name
@Override
public boolean contains(String name) {
return this.propertySourceList.contains(PropertySource.named(name));
}
// 从 propertySourceList 获取名称为 name 的 PropertySource, 如果不存在,返回 null, 如果存在一个或多个,返回第一个
@Override
public PropertySource get(String name) {
int index = this.propertySourceList.indexOf(PropertySource.named(name));
return (index != -1 ? this.propertySourceList.get(index) : null);
}
// 迭代器同 propertySourceList 迭代器
@Override
public Iterator> iterator() {
return this.propertySourceList.iterator();
}
//添加一个 PropertySource, 赋予最高优先级
public void addFirst(PropertySource propertySource) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Adding [%s] PropertySource with highest search precedence",
propertySource.getName()));
}
removeIfPresent(propertySource);
this.propertySourceList.add(0, propertySource);
}
//添加一个 PropertySource, 赋予最低优先级
public void addLast(PropertySource propertySource) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Adding [%s] PropertySource with lowest search precedence",
propertySource.getName()));
}
removeIfPresent(propertySource);
this.propertySourceList.add(propertySource);
}
//添加一个 PropertySource, 优先级在 relativePropertySourceName 的前一位
public void addBefore(String relativePropertySourceName, PropertySource propertySource) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Adding [%s] PropertySource with search precedence immediately higher than [%s]",
propertySource.getName(), relativePropertySourceName));
}
// check 两个 name 是否相同, 如果相同抛出异常
assertLegalRelativeAddition(relativePropertySourceName, propertySource);
removeIfPresent(propertySource);
int index = assertPresentAndGetIndex(relativePropertySourceName);
addAtIndex(index, propertySource);
}
//添加一个 PropertySource, 优先级在 relativePropertySourceName 的后一位
public void addAfter(String relativePropertySourceName, PropertySource propertySource) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Adding [%s] PropertySource with search precedence immediately lower than [%s]",
propertySource.getName(), relativePropertySourceName));
}
// check 两个 name 是否相同, 如果相同抛出异常
assertLegalRelativeAddition(relativePropertySourceName, propertySource);
removeIfPresent(propertySource);
int index = assertPresentAndGetIndex(relativePropertySourceName);
addAtIndex(index + 1, propertySource);
}
// 返回 PropertySource 的优先级
public int precedenceOf(PropertySource propertySource) {
return this.propertySourceList.indexOf(propertySource);
}
// 删除名称为 name 的 PropertySource
public PropertySource remove(String name) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Removing [%s] PropertySource", name));
}
int index = this.propertySourceList.indexOf(PropertySource.named(name));
return (index != -1 ? this.propertySourceList.remove(index) : null);
}
// 替换名称为 name 的 PropertySource
public void replace(String name, PropertySource propertySource) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Replacing [%s] PropertySource with [%s]",
name, propertySource.getName()));
}
//判断 name 存在, 如果不存在, 抛出异常
int index = assertPresentAndGetIndex(name);
this.propertySourceList.set(index, propertySource);
}
// 如果 PropertySource 存在,则删除
protected void removeIfPresent(PropertySource propertySource) {
this.propertySourceList.remove(propertySource);
}
// 将 PropertySource 放置在列表的指定为止(优先级)
private void addAtIndex(int index, PropertySource propertySource) {
removeIfPresent(propertySource);
this.propertySourceList.add(index, propertySource);
}
}
MutablePropertySources 内部属性是:
private final List> propertySourceList = new CopyOnWriteArrayList<>();
这个属性就是最底层的存储容器,也就是环境属性都是存放在一个 CopyOnWriteArrayList> 实例中。MutablePropertySources 是 PropertySources 的子类,它提供了 get(String name)、addFirst、addLast、addBefore、addAfter、remove、replace 等便捷方法,方便操作 propertySourceList 集合的元素。由这些方法的命名可以看出 MutablePropertySources 将 propertySourceList 维护成一个有序的集合,以作为 propertySourceList 获取配置的优先级控制。
小结
- Spring 应用程序运行环境概念,主要包含两个方面的内容。profiles 决定了哪些 Bean 会被加载;properties 就是配置,就是键值对
- PropertySource 表示一个属性源(键值对集合)
- Environment 存储容器 是一个 CopyOnWriteArrayList> 实例,MutablePropertySources 提供了有序访问的 api。
Environment 加载过程
此处关注的是 web 项目,即说明的加载过程使用的是 StandardServletEnvironment。
构造函数配置加载过程
image.png
观察 AbstractEnvironment 构造函数
public AbstractEnvironment() {
customizePropertySources(this.propertySources);
if (this.logger.isDebugEnabled()) {
this.logger.debug(String.format("Initialized %s with PropertySources %s", getClass().getSimpleName(), this.propertySources));
}
}
// 空方法,实现类可以自定义 PropertySources
protected void customizePropertySources(MutablePropertySources propertySources) {
}
再看看 StandardEnvironment 的 customizePropertySources()方法和 StandardServletEnvironment 的 customizePropertySources()
// StandardEnvironment 的 customizePropertySources()方法
@Override
protected void customizePropertySources(MutablePropertySources propertySources) {
// 构造名称为 systemProperties 的MapPropertySource,即 JVM 变量 PropertySource, 并放入 MutablePropertySources propertySources 中
propertySources.addLast(new MapPropertySource(SYSTEM_PROPERTIES_PROPERTY_SOURCE_NAME, getSystemProperties()));
// 构造名称为 systemEnvironment 的MapPropertySource, 即 系统环境变量 PropertySource, 并放入 MutablePropertySources propertySources 中
propertySources.addLast(new SystemEnvironmentPropertySource(SYSTEM_ENVIRONMENT_PROPERTY_SOURCE_NAME, getSystemEnvironment()));
}
// StandardServletEnvironment 的 customizePropertySources()方法
// 此处在 MutablePropertySources 中放入两个 StubPropertySource 类型的 PropertySource,
// servletConfigInitParams 和 servletContextInitParams
// 由上文,我们知道 StubPropertySource 是一个空实现,原因是 Servlet 相关的配置得到 ServletContext 初始化时才有,
// 此处仅起到一个占位的作用, 在 AnnotationConfigEmbeddedWebApplicationContext 初始化时,
// 才会通过 initPropertySources 方重新赋值
@Override
protected void customizePropertySources(MutablePropertySources propertySources) {
// 构造名称为 servletConfigInitParams 的 StubPropertySource,并放入 MutablePropertySources
propertySources.addLast(new StubPropertySource(SERVLET_CONFIG_PROPERTY_SOURCE_NAME));
// 构造名称为 servletContextInitParams 的 StubPropertySource,并放入 MutablePropertySources
propertySources.addLast(new StubPropertySource(SERVLET_CONTEXT_PROPERTY_SOURCE_NAME));
// 如果存在 JNDI 环境, 构造名称为 jndiProperties 的 JndiPropertySource,并放入 MutablePropertySources
if (JndiLocatorDelegate.isDefaultJndiEnvironmentAvailable()) {
propertySources.addLast(new JndiPropertySource(JNDI_PROPERTY_SOURCE_NAME));
}
// 调用父类的customizePropertySources(), 即调用 StandardServletEnvironment 的 customizePropertySources()
super.customizePropertySources(propertySources);
}
// 被 AnnotationConfigEmbeddedWebApplicationContext 调用,冲洗初始化 servletConfigInitParams 和 servletContextInitParams
@Override
public void initPropertySources(ServletContext servletContext, ServletConfig servletConfig) {
WebApplicationContextUtils.initServletPropertySources(getPropertySources(), servletContext, servletConfig);
}
// WebApplicationContextUtils#initServletPropertySources
// 重新构建
public static void initServletPropertySources(
MutablePropertySources propertySources, ServletContext servletContext, ServletConfig servletConfig) {
Assert.notNull(propertySources, "'propertySources' must not be null");
if (servletContext != null && propertySources.contains(StandardServletEnvironment.SERVLET_CONTEXT_PROPERTY_SOURCE_NAME) &&
propertySources.get(StandardServletEnvironment.SERVLET_CONTEXT_PROPERTY_SOURCE_NAME) instanceof StubPropertySource) {
// 使用 servletContext 重新构造名称为 servletContextInitParams 的 ServletContextPropertySource,
// 并替换原有的占位StubPropertySource
propertySources.replace(StandardServletEnvironment.SERVLET_CONTEXT_PROPERTY_SOURCE_NAME, new ServletContextPropertySource(StandardServletEnvironment.SERVLET_CONTEXT_PROPERTY_SOURCE_NAME, servletContext));
}
if (servletConfig != null && propertySources.contains(StandardServletEnvironment.SERVLET_CONFIG_PROPERTY_SOURCE_NAME) &&
propertySources.get(StandardServletEnvironment.SERVLET_CONFIG_PROPERTY_SOURCE_NAME) instanceof StubPropertySource) {
// 使用 servletConfig 重新构造名称为 servletConfigInitParams 的 ServletConfigPropertySource,
// 并替换原有的占位StubPropertySource
propertySources.replace(StandardServletEnvironment.SERVLET_CONFIG_PROPERTY_SOURCE_NAME, new ServletConfigPropertySource(StandardServletEnvironment.SERVLET_CONFIG_PROPERTY_SOURCE_NAME, servletConfig));
}
}
看完代码,可以简单总结一下代码执行顺序,
-
AbstractEnvironment 的构造方法 调用了 customizePropertySources()。
-
StandardEnvironment 和 StandardServletEnvironment 重写 customizePropertySources()。
-
StandardServletEnvironment 在 customizePropertySources()中构造了 StubPropertySource 类型的 servletConfigInitParams 和 servletContextInitParams 放入 MutablePropertySources 中占位, 当servlet环境准备好, 重新初始化和替换,还构建了 jndiProperties 放入 MutablePropertySources 中。最后调用 StandardEnvironment#customizePropertySources()。
-
StandardEnvironment 在 customizePropertySources 方法中,初始化了 systemProperties 和 systemEnvironment。 简单总结,此处用来模板方法设计模式:

image.png
上面的逻辑都是在 StandardServletEnvironment 构造中完成的,且都是用了 addLast()方法操作,由执行顺序可得,配置的优先级递减排序:
-
servletConfigInitParams
-
servletContextInitParams
-
jndiProperties
-
systemProperties
-
systemEnvironment 以上构造过程中的配置加载过程已经说完了。再来看看 spring boot web 服务启动过程中的配置加载过程。
命令行参数
本文不过多介绍spring boot web 服务启动流程,直接到启动过程中,环境准备阶段代码。 由上文描述介绍 Environment, 我们知道,Environment 的配置是存储在一个 MutablePropertySources propertySources 对象中,而 ConfigurableEnvironment 暴露了获取该对象的方法
MutablePropertySources getPropertySources();
这就允许程序在任何地方,只要能获取到 Environment 对象,就可以获取到 MutablePropertySources propertySources 对象,并对齐做修改。 此处介绍两个spring boot web 程序启动过程中的两个 case, 学习一下如何修改,主要是修改的地方太多了,没法枚举。
SpringApplication#prepareEnvironment() 命令行参数 commandLineArgs
private ConfigurableEnvironment prepareEnvironment(SpringApplicationRunListeners listeners,ApplicationArguments applicationArguments) {
// 构造函数创建 Environment
ConfigurableEnvironment environment = getOrCreateEnvironment();
// 配置 Environment 的 PropertySources 和 Profiles
configureEnvironment(environment, applicationArguments.getSourceArgs());
// 发布 ApplicationEnvironmentPreparedEvent 事件, 此处不介绍 spring 事件机制,
// 事件发布后,其实也有很多地方修改该了Environment配置,此处不做介绍
listeners.environmentPrepared(environment);
if (!this.webEnvironment) {
environment = new EnvironmentConverter(getClassLoader()).convertToStandardEnvironmentIfNecessary(environment);
}
return environment;
}
// 配置 Environment 的 PropertySources 和 Profiles
protected void configureEnvironment(ConfigurableEnvironment environment,
String[] args) {
// 配置 PropertySources
configurePropertySources(environment, args);
// 配置 Profiles
configureProfiles(environment, args);
}
protected void configurePropertySources(ConfigurableEnvironment environment, String[] args) {
MutablePropertySources sources = environment.getPropertySources();
if (this.defaultProperties != null && !this.defaultProperties.isEmpty()) {
sources.addLast(new MapPropertySource("defaultProperties", this.defaultProperties));
}
// 如果 存在命令行参数
if (this.addCommandLineProperties && args.length > 0) {
String name = CommandLinePropertySource.COMMAND_LINE_PROPERTY_SOURCE_NAME;
// MutablePropertySources 已存在 commandLineArgs,
// 则将已有的 commandLineArgs 与 新生成的 SimpleCommandLinePropertySource 变成一个合成的 CompositePropertySource,
// 替换MutablePropertySources中的 commandLineArgs
if (sources.contains(name)) {
PropertySource source = sources.get(name);
CompositePropertySource composite = new CompositePropertySource(name);
composite.addPropertySource(new SimpleCommandLinePropertySource(name + "-" + args.hashCode(), args));
composite.addPropertySource(source);
sources.replace(name, composite);
}
// MutablePropertySources 不存在 commandLineArgs,
// 新生成 SimpleCommandLinePropertySource 放入MutablePropertySources的最高优先级位置
else {
sources.addFirst(new SimpleCommandLinePropertySource(args));
}
}
}
构造完成后的Environment debug截图:

image.png
执行configureEnvironment()之后, 可以看到,多了一个的commandLineArgs, Environment debug截图:

image.png
spring-cloud-config 加载外部配置
本文不会详细介绍 spring-cloud-config, 只会介绍其中一段关于 Environment 配置变更的部分。涉及到spring 初始化机制,本文也不会详细介绍。
// 省略不相关代码
// 实现了 ApplicationContextInitializer 接口, 在spring boot启动过程中,会调用 initialize()方法,此处不做详细介绍
@Configuration
@EnableConfigurationProperties(PropertySourceBootstrapProperties.class)
public class PropertySourceBootstrapConfiguration implements ApplicationContextInitializer, Ordered {
// 配置加载器, 主要作用是: 通过http请求,去config-server拉取配置
@Autowired(required = false)
private List propertySourceLocators = new ArrayList<>();
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
// 创建名称为 bootstrapProperties 合成资源
CompositePropertySource composite = new CompositePropertySource(BOOTSTRAP_PROPERTY_SOURCE_NAME);
// 对配置加载器排序
AnnotationAwareOrderComparator.sort(this.propertySourceLocators);
boolean empty = true;
// 当前应用上下文的 Environment
ConfigurableEnvironment environment = applicationContext.getEnvironment();
// 遍历多个配置加载器,加载配置
for (PropertySourceLocator locator : this.propertySourceLocators) {
//配置加载器返回结果, 如果为空, 继续下次循环, 如果配置不为空,添加到合成资源 CompositePropertySource 中
PropertySource source = null;
source = locator.locate(environment);
if (source == null) {
continue;
}
logger.info("Located property source: " + source);
composite.addPropertySource(source);
empty = false;
}
// 配置加载器返回的配置非空,即 CompositePropertySource 非空
if (!empty) {
MutablePropertySources propertySources = environment.getPropertySources();
String logConfig = environment.resolvePlaceholders("${logging.config:}");
LogFile logFile = LogFile.get(environment);
// 如果 Environment 配置中已经包含 bootstrapProperties, 删除
if (propertySources.contains(BOOTSTRAP_PROPERTY_SOURCE_NAME)) {
propertySources.remove(BOOTSTRAP_PROPERTY_SOURCE_NAME);
}
// 将 CompositePropertySource 添加到 MutablePropertySources 中
insertPropertySources(propertySources, composite);
reinitializeLoggingSystem(environment, logConfig, logFile);
setLogLevels(environment);
handleIncludedProfiles(environment);
}
}
// 将 CompositePropertySource 添加到 MutablePropertySources 中
private void insertPropertySources(MutablePropertySources propertySources, CompositePropertySource composite) {
MutablePropertySources incoming = new MutablePropertySources();
incoming.addFirst(composite);
// 构造 PropertySourceBootstrapProperties remoteProperties, 使用 RelaxedDataBinder 为 remoteProperties 赋值
PropertySourceBootstrapProperties remoteProperties = new PropertySourceBootstrapProperties();
new RelaxedDataBinder(remoteProperties, "spring.cloud.config").bind(new PropertySourcesPropertyValues(incoming));
// 如果 配置为远程覆盖本地,则将 composite 放在 propertySources 最高优先级位置
if (!remoteProperties.isAllowOverride()
|| (!remoteProperties.isOverrideNone() && remoteProperties.isOverrideSystemProperties())) {
propertySources.addFirst(composite);
return;
}
// 如果 配置为远程不覆盖本地, 则将 composite 放在 propertySources 最低优先级位置
if (remoteProperties.isOverrideNone()) {
propertySources.addLast(composite);
return;
}
// 当 systemEnvironment 存在,
if (propertySources.contains(StandardEnvironment.SYSTEM_ENVIRONMENT_PROPERTY_SOURCE_NAME)) {
// 如果配置 overrideSystemProperties 为 false, 将 composite 放在 systemEnvironment 优先级后面
// 否则, 放在 systemEnvironment 优先级前面
if (!remoteProperties.isOverrideSystemProperties()) {
propertySources.addAfter(StandardEnvironment.SYSTEM_ENVIRONMENT_PROPERTY_SOURCE_NAME,
composite);
} else {
propertySources.addBefore(StandardEnvironment.SYSTEM_ENVIRONMENT_PROPERTY_SOURCE_NAME,
composite);
}
// 当 systemEnvironment 不存在, 则将 composite 放在 propertySources 最低优先级位置
} else {
propertySources.addLast(composite);
}
}
}
以上内容说明了 命令行参数 和 spring-cloud-config 获取到的远程配置 加载到 Environment 中的过程。
Environment 属性访问
上文提到, Environment 的配置都存储在 MutablePropertySources propertySources 中,那 Environment 是如何访问到配置的呢? 代码在 AbstractEnvironment 中实现:
@Override
public String getProperty(String key) {
return this.propertyResolver.getProperty(key);
}
@Override
public String getProperty(String key, String defaultValue) {
return this.propertyResolver.getProperty(key, defaultValue);
}
@Override
public T getProperty(String key, Class targetType) {
return this.propertyResolver.getProperty(key, targetType);
}
@Override
public T getProperty(String key, Class targetType, T defaultValue) {
return this.propertyResolver.getProperty(key, targetType, defaultValue);
}
可以看到, 属性访问都委托给了 propertyResolver 对象, 而 PropertySourcesPropertyResolver 的构造函数 需要传入一个 propertySources
private final ConfigurablePropertyResolver propertyResolver = new PropertySourcesPropertyResolver(this.propertySources);
public PropertySourcesPropertyResolver(PropertySources propertySources) {
this.propertySources = propertySources;
}
先看看 的类型结构

image.png
- PropertyResolver 决定基础 source 的接口
- ConfigurablePropertyResolver 继承 PropertyResolver, 配置接口,用来定制 ConversionService
- AbstractPropertyResolver 是 ConfigurablePropertyResolver 抽象实现, 决定基础 source 的抽象类
- PropertySourcesPropertyResolver 继承 AbstractPropertyResolver
PropertyResolver-占位符处理
PropertyResolver是 PropertySourcesPropertyResolver 的顶层接口,主要提供属性检索和解析带占位符的文本。
public interface PropertyResolver {
boolean containsProperty(String key);
String getProperty(String key);
String getProperty(String key, String defaultValue);
T getProperty(String key, Class targetType);
T getProperty(String key, Class targetType, T defaultValue);
@Deprecated
Class getPropertyAsClass(String key, Class targetType);
String getRequiredProperty(String key) throws IllegalStateException;
T getRequiredProperty(String key, Class targetType) throws IllegalStateException;
String resolvePlaceholders(String text);
String resolveRequiredPlaceholders(String text) throws IllegalArgumentException;
}
ConfigurablePropertyResolver 确定解析占位符的一些配置方法。
public interface ConfigurablePropertyResolver extends PropertyResolver {
ConfigurableConversionService getConversionService();
void setConversionService(ConfigurableConversionService conversionService);
void setPlaceholderPrefix(String placeholderPrefix);
void setPlaceholderSuffix(String placeholderSuffix);
void setValueSeparator(String valueSeparator);
void setIgnoreUnresolvableNestedPlaceholders(boolean ignoreUnresolvableNestedPlaceholders);
void setRequiredProperties(String... requiredProperties);
void validateRequiredProperties() throws MissingRequiredPropertiesException;
}
AbstractPropertyResolver 封装了解析占位符的具体实现,而 PropertySourcesPropertyResolver 主要是负责提供数据源。AbstractPropertyResolver 中有两个成员变量都是 PropertyPlaceholderHelper 对象,区别在于构造参数不同。
// 解析占位符,忽略不能解析的占位符
public String resolvePlaceholders(String text) {
if (this.nonStrictHelper == null) {
this.nonStrictHelper = createPlaceholderHelper(true);
}
return doResolvePlaceholders(text, this.nonStrictHelper);
}
// 解析占位符,不忽略不能解析的占位符, 遇到不能解析的占位符, 抛出异常
public String resolveRequiredPlaceholders(String text) throws IllegalArgumentException {
if (this.strictHelper == null) {
this.strictHelper = createPlaceholderHelper(false);
}
return doResolvePlaceholders(text, this.strictHelper);
}
// 将解析占位符的逻辑委托给 PropertyPlaceholderHelper helper对象
private String doResolvePlaceholders(String text, PropertyPlaceholderHelper helper) {
return helper.replacePlaceholders(text, new PropertyPlaceholderHelper.PlaceholderResolver() {
// 入参是占位符, 出参是 PropertySource 存储的原生value, 依赖抽象方法 getPropertyAsRawString()
@Override
public String resolvePlaceholder(String placeholderName) {
return getPropertyAsRawString(placeholderName);
}
});
}
// 获取 PropertySource 存储的原生value, 由字类实现
protected abstract String getPropertyAsRawString(String key);
在看看PropertyPlaceholderHelper代码:
// 占位符处理器
public class PropertyPlaceholderHelper {
private static final Map wellKnownSimplePrefixes = new HashMap(4);
static {
wellKnownSimplePrefixes.put("}", "{");
wellKnownSimplePrefixes.put("]", "[");
wellKnownSimplePrefixes.put(")", "(");
}
private final String placeholderPrefix; // 默认 "${"
private final String placeholderSuffix; // 默认 "}"
private final String simplePrefix;
private final String valueSeparator; // 默认 ":"
private final boolean ignoreUnresolvablePlaceholders; // 是否忽略占位符中不存在的数据源,false会抛出IllegalArgumentException。
// 构造函数
public PropertyPlaceholderHelper(String placeholderPrefix, String placeholderSuffix, String valueSeparator, boolean ignoreUnresolvablePlaceholders) {
Assert.notNull(placeholderPrefix, "'placeholderPrefix' must not be null");
Assert.notNull(placeholderSuffix, "'placeholderSuffix' must not be null");
this.placeholderPrefix = placeholderPrefix;
this.placeholderSuffix = placeholderSuffix;
String simplePrefixForSuffix = wellKnownSimplePrefixes.get(this.placeholderSuffix);
if (simplePrefixForSuffix != null && this.placeholderPrefix.endsWith(simplePrefixForSuffix)) {
this.simplePrefix = simplePrefixForSuffix;
}
else {
this.simplePrefix = this.placeholderPrefix;
}
this.valueSeparator = valueSeparator;
this.ignoreUnresolvablePlaceholders = ignoreUnresolvablePlaceholders;
}
// 用来将 value 中占位符替换为从 Properties 取得的值
public String replacePlaceholders(String value, final Properties properties) {
Assert.notNull(properties, "'properties' must not be null");
return replacePlaceholders(value, new PlaceholderResolver() {
@Override
public String resolvePlaceholder(String placeholderName) {
return properties.getProperty(placeholderName);
}
});
}
// 用来将 value 中占位符替换为从 PlaceholderResolver 取得的值
public String replacePlaceholders(String value, PlaceholderResolver placeholderResolver) {
Assert.notNull(value, "'value' must not be null");
return parseStringValue(value, placeholderResolver, new HashSet());
}
// 用来将 value 中占位符替换为从 PlaceholderResolver 取得的值, 具体实现逻辑
// 这是一个递归的解析过程,遇到${开头就会查找最后一个}符号,
// 将最外层占位符内的内容作为新的 value 再次传入 parseStringValue() 方法中,
// 这样最深层次也就是最先返回的就是最里层的占位符名字。
// 调用placeholderResolver将占位符名字转换成它代表的值。
// 如果值为null,则考虑使用默认值 ( valueSeparator 后的内容) 赋值给 propVal。
// 由于 placeholderResolver 转换过的值有可能还会包含占位符,
// 所以在此调用 parseStringValue() 方法将带有占位符的 propVal 传入返回真正的值,用 propVal 替换占位符。
// 如果 propVal==null,判断是否允许忽略不能解析的占位符,
// 如果可以,重置 startIndex,继续解析同一层次的占位符。否则抛出异常,这个函数的返回值就是它上一层次的占位符解析值
protected String parseStringValue(String value, PlaceholderResolver placeholderResolver, Set visitedPlaceholders) {
StringBuilder result = new StringBuilder(value);
int startIndex = value.indexOf(this.placeholderPrefix);
// 当 包含 placeholderPrefix(“${”)时
while (startIndex != -1) {
int endIndex = findPlaceholderEndIndex(result, startIndex);
if (endIndex != -1) {
// 解析到占位符
String placeholder = result.substring(startIndex + this.placeholderPrefix.length(), endIndex);
String originalPlaceholder = placeholder;
// 将解析到的占位符添加到visitedPlaceholders, 如果添加失败,表示由循环的占位符,抛出异常
if (!visitedPlaceholders.add(originalPlaceholder)) {
throw new IllegalArgumentException("Circular placeholder reference '" + originalPlaceholder + "' in property definitions");
}
// 递归调用, 继续转化占位符, 因为转化到的接口,可能仍然包含占位符
placeholder = parseStringValue(placeholder, placeholderResolver, visitedPlaceholders);
// 获取占位符里面的 key 对应的值
String propVal = placeholderResolver.resolvePlaceholder(placeholder);
// 如果 propVal 为空且 this.valueSeparator 不为空
if (propVal == null && this.valueSeparator != null) {
int separatorIndex = placeholder.indexOf(this.valueSeparator);
// 如果占位符包含默认值分割符
if (separatorIndex != -1) {
// 获取正真的占位符, separatorIndex 之前的部分
String actualPlaceholder = placeholder.substring(0, separatorIndex);
// 默认值, separatorIndex 之后的部分
String defaultValue = placeholder.substring(separatorIndex + this.valueSeparator.length());
// 重新解析正真的占位符, 如果值还是不存在,则使用默认值
propVal = placeholderResolver.resolvePlaceholder(actualPlaceholder);
if (propVal == null) {
propVal = defaultValue;
}
}
}
// 如果 propVal 不为空
if (propVal != null) {
// 递归调用, 继续解析 获取到的占位符值,即 propVal
propVal = parseStringValue(propVal, placeholderResolver, visitedPlaceholders);
// 解析到结果 替换结果中
result.replace(startIndex, endIndex + this.placeholderSuffix.length(), propVal);
if (logger.isTraceEnabled()) {
logger.trace("Resolved placeholder '" + placeholder + "'");
}
// 找到下一个 “${” 开始的位置, 赋值给 startIndex
startIndex = result.indexOf(this.placeholderPrefix, startIndex + propVal.length());
} else if (this.ignoreUnresolvablePlaceholders) {
// 如果解析不到结果, ignoreUnresolvablePlaceholders == true的情况下
// 找到下一个 “${” 开始的位置, 赋值给 startIndex
startIndex = result.indexOf(this.placeholderPrefix, endIndex + this.placeholderSuffix.length());
} else {
// 如果解析不到结果, ignoreUnresolvablePlaceholders == false 的情况下, 抛出异常
throw new IllegalArgumentException("Could not resolve placeholder '" +
placeholder + "'" + " in value \"" + value + "\"");
}
// 移除解析成功的占位符
visitedPlaceholders.remove(originalPlaceholder);
} else {
// 占位符中 不包含“${”, 结束循环
startIndex = -1;
}
}
return result.toString();
}
// 判断嵌套的占位符是依据simplePrefix,找到当前占位符前缀对应的尾缀
private int findPlaceholderEndIndex(CharSequence buf, int startIndex) {
int index = startIndex + this.placeholderPrefix.length();
int withinNestedPlaceholder = 0;
while (index < buf.length()) {
if (StringUtils.substringMatch(buf, index, this.placeholderSuffix)) {
if (withinNestedPlaceholder > 0) {
withinNestedPlaceholder--;
index = index + this.placeholderSuffix.length();
}
else {
return index;
}
}
else if (StringUtils.substringMatch(buf, index, this.simplePrefix)) {
withinNestedPlaceholder++;
index = index + this.simplePrefix.length();
}
else {
index++;
}
}
return -1;
}
// PlaceholderResolver是一个接口定了一个方法,入参为占位符参数名,出参为占位符代表的值。
public interface PlaceholderResolver {
String resolvePlaceholder(String placeholderName);
}
}
再来看看 PropertySourcesPropertyResolver 代码
public class PropertySourcesPropertyResolver extends AbstractPropertyResolver {
// 数据源
private final PropertySources propertySources;
// 获取指定类型获取配置
// key
// targetValueType 目标类型
// resolveNestedPlaceholders 是否处理占位符
protected T getProperty(String key, Class targetValueType, boolean resolveNestedPlaceholders) {
if (this.propertySources != null) {
// 顺序遍历 propertySources, 体现了优先级, 之前文中也提到了 MutablePropertySources 维护的是有序列表
for (PropertySource propertySource : this.propertySources) {
if (logger.isTraceEnabled()) {
logger.trace(String.format("Searching for key '%s' in [%s]", key, propertySource.getName()));
}
// 原生的配置 value
Object value = propertySource.getProperty(key);
if (value != null) {
// 判断是否处理占位符
if (resolveNestedPlaceholders && value instanceof String) {
value = resolveNestedPlaceholders((String) value);
}
logKeyFound(key, propertySource, value);
// 类型转换,转换成目标类型 targetValueType
return convertValueIfNecessary(value, targetValueType);
}
}
}
if (logger.isDebugEnabled()) {
logger.debug(String.format("Could not find key '%s' in any property source", key));
}
return null;
}
}
ConversionService-类型转换
上文提到,在占位符处理完成之后, 最后一步是 convertValueIfNecessary(), 类型转化,代码还是在 AbstractPropertyResolver 中:
protected T convertValueIfNecessary(Object value, Class targetType) {
if (targetType == null) {
return (T) value;
}
// 如果自定义 ConversionService, 则使用 DefaultConversionService
ConversionService conversionServiceToUse = this.conversionService;
if (conversionServiceToUse == null) {
// Avoid initialization of shared DefaultConversionService if
// no standard type conversion is needed in the first place...
if (ClassUtils.isAssignableValue(targetType, value)) {
return (T) value;
}
conversionServiceToUse = DefaultConversionService.getSharedInstance();
}
// 转化成功后,返回
return conversionServiceToUse.convert(value, targetType);
}
